






问题陈述:
某些老师不让对ppt进行下载操作,只能打开看,正常操作大家就是会一张张截图,但是ppt很多
但其实每个ppt都是由多张png图片组成,大家按F12就可以查看图片的下载地址,而且最关键的是所有图片的下载地址都是规律的,只是变了后面的数字,所以这就给自动化下载图片提供了可能,最后附上我的代码:
功能是实现自动化下载网页的png,然后最后整合为横屏的四宫格pdf

源码以及使用方式
使用方式,将图片地址改成自己需要下载的地址,将唯一变动的索引变为{i},然后for循环括号里的(1,53)改成自己ppt的页数,我这里的ppt是51页,所以我设置53,多下载两页没事的。
image_urls = [
f"https://s3.ananas.chaoxing.com/sv-w9/doc/d8/e0/02/54884d5c80102a9f0c3df2714eda18ed/thumb/{i}.png"
for i in range(1, 53)
]import requests
from PIL import Image
from fpdf import FPDF
from io import BytesIO
import os
# 下载图片并保存到本地
def download_images():
image_urls = [
f"https://s3.ananas.chaoxing.com/sv-w9/doc/d8/e0/02/54884d5c80102a9f0c3df2714eda18ed/thumb/{i}.png"
for i in range(1, 53)
]
images = []
for url in image_urls:
response = requests.get(url)
if response.status_code == 200:
image = Image.open(BytesIO(response.content))
images.append(image)
else:
print(f"Failed to download image from {url}")
return images
# 将图片保存为PDF
def save_images_to_pdf(images, output_path):
pdf = FPDF(orientation='L', unit='mm', format='A4') # 设置为横向A4纸
page_width, page_height = 297, 210 # 横向A4纸的尺寸,单位是mm
images_per_page = 4 # 每页放四张图片
img_margin = 10 # 图片之间的间距
img_width = (page_width - 3 * img_margin) / 2 # 每张图片的宽度
img_height = (page_height - 3 * img_margin) / 2 # 每张图片的高度
for i, image in enumerate(images):
if i % images_per_page == 0:
pdf.add_page()
# 临时保存图片到一个文件
temp_filename = f"temp_image_{i}.png"
image.save(temp_filename)
# 获取图片尺寸并调整图片高度和宽度以适应新的尺寸
img_original_width, img_original_height = image.size
scale_ratio = min(img_width / img_original_width, img_height / img_original_height)
scaled_width = img_original_width * scale_ratio
scaled_height = img_original_height * scale_ratio
x_position = img_margin + (i % 2) * (img_width + img_margin) # 图片的水平位置
y_position = img_margin + (i // 2 % 2) * (img_height + img_margin) # 图片的垂直位置
# 将图片添加到PDF
pdf.image(temp_filename, x=x_position, y=y_position, w=scaled_width, h=scaled_height)
# 删除临时文件
os.remove(temp_filename)
pdf.output(output_path, "F")
if __name__ == "__main__":
images = download_images()
if images:
save_images_to_pdf(images, "output.pdf")
print("PDF文件已成功保存为output.pdf")
else:
print("未能下载任何图片")(补档)新手教学,怎么运行脚本
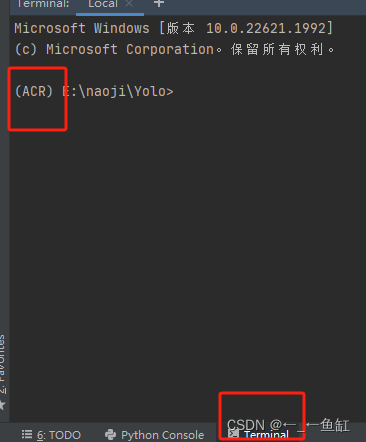
考虑到很多看到这个文章的人都是新手,没怎么接触过编程的,我建议就是,下载anaconda和pycharm,这两个在csdn都有教程。然后打开pycharm里的一个终端,创建一个虚拟环境,如图所示,我进入的是我的名为ACR虚拟环境
#在终端里以此运行以下指令即可
conda create -n ACR python=3.9
conda activate ACR
pip install requests
pip install Pillow
pip install fpdf 打开脚本后,在界面中任意位置右击。
打开脚本后,在界面中任意位置右击。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









