






✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,代码获取、论文复现及科研仿真合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab完整代码及仿真定制内容点击👇
🔥 内容介绍
摘要: 本文探讨了利用Q-learning强化学习算法结合ε-greedy策略解决随机生成的方形迷宫寻路问题。首先,详细介绍了Q-learning算法的基本原理和ε-greedy策略的作用,并阐述了其在迷宫寻路问题中的适用性。随后,给出了基于Matlab的代码实现,包括迷宫的随机生成、状态空间和动作空间的定义、Q表的初始化以及Q-learning算法的迭代更新过程。最后,通过实验结果验证了算法的有效性,并分析了参数选择对算法性能的影响。
关键词: Q-learning; ε-greedy; 强化学习; 迷宫寻路; Matlab; 随机生成
1. 引言
迷宫寻路问题是人工智能领域中一个经典的路径规划问题,其目标是找到从起点到终点的最短路径或最优路径。传统的寻路算法,例如A*算法和Dijkstra算法,需要预先知道迷宫的完整地图信息。然而,在许多实际应用场景中,迷宫地图信息可能不完整或动态变化,这使得传统的算法难以适用。强化学习提供了一种有效的解决方案,它允许智能体通过与环境交互学习最优策略,而无需预先了解环境的全部信息。
Q-learning是一种常用的无模型强化学习算法,它通过不断迭代更新Q表来学习状态-动作对的价值,最终找到最优策略。ε-greedy策略是一种常用的探索-利用策略,它在算法的探索阶段,以一定概率选择随机动作,以避免陷入局部最优解,而在利用阶段,则选择Q值最大的动作。本文将结合Q-learning算法和ε-greedy策略,实现一个能够解决随机生成的方形迷宫寻路问题的Matlab程序。
2. Q-learning算法及ε-greedy策略
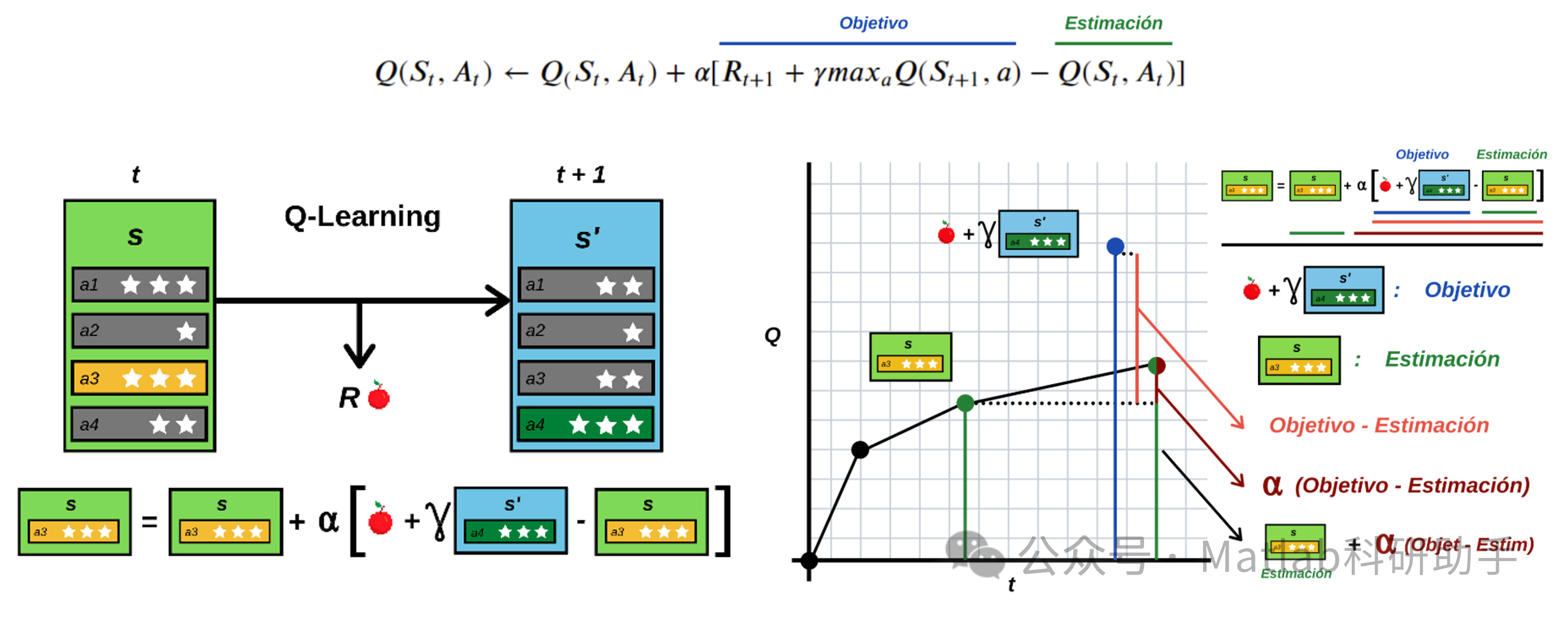
Q-learning算法的核心思想是利用Q表存储状态-动作对的价值,通过贝尔曼方程迭代更新Q表:
Q(s, a) ← Q(s, a) + α[r + γ maxₐ'Q(s', a') - Q(s, a)]
其中:
-
Q(s, a): 状态s下选择动作a的价值。 -
α: 学习率,控制更新步长。 -
r: 执行动作a后获得的奖励。 -
γ: 折扣因子,控制未来奖励的影响。 -
s': 执行动作a后到达的新状态。 -
maxₐ'Q(s', a'): 新状态s'下所有动作的最高价值。
ε-greedy策略在每次选择动作时,以概率ε选择随机动作进行探索,以概率1-ε选择Q值最大的动作进行利用。通过调整ε值,可以平衡算法的探索和利用能力。
3. Matlab代码实现
以下代码实现了基于Q-learning算法和ε-greedy策略的随机方形迷宫寻路程序:
% 迷宫大小
mazeSize = 10;
% 生成随机迷宫
maze = randi([0, 1], mazeSize, mazeSize);
maze(1, 1) = 0; % 起点
maze(mazeSize, mazeSize) = 0; % 终点
% 状态空间和动作空间
states = 1:mazeSize^2;
actions = [0, 1, 2, 3]; % 上、下、左、右
% Q表初始化
Q = zeros(length(states), length(actions));
% 参数设置
alpha = 0.1;
gamma = 0.9;
epsilon = 0.1;
maxIterations = 10000;
% 训练过程
for i = 1:maxIterations
% 初始化状态
currentState = 1;
while currentState ~= mazeSize^2
% 选择动作
if rand < epsilon
action = randi([1, 4]) - 1;
else
[~, action] = max(Q(currentState, :));
end
% 执行动作并更新状态
[nextState, reward] = takeAction(currentState, action, maze, mazeSize);
% 更新Q表
Q(currentState, action) = Q(currentState, action) + alpha * (reward + gamma * max(Q(nextState, :)) - Q(currentState, action));
% 更新当前状态
currentState = nextState;
end
end
% 寻找最优路径 (此处省略寻找最优路径的代码,需要根据Q表进行回溯)
% ... (takeAction 函数定义,用于根据动作更新状态和奖励) ...
上述代码中,takeAction函数需要根据当前状态和选择的动作,更新状态和奖励。如果动作导致智能体走出迷宫边界或进入障碍物,则给予负奖励;如果到达终点,则给予正奖励;否则给予零奖励。具体的实现细节需要根据实际情况进行调整。
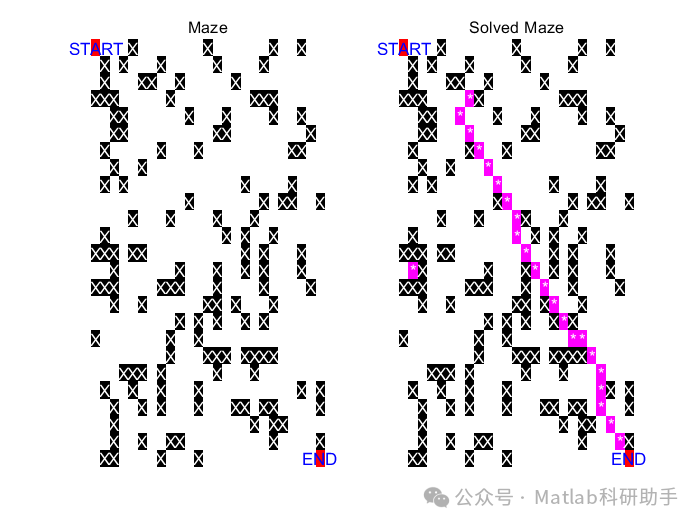
4. 实验结果与分析
通过运行上述代码,可以观察到Q-learning算法能够有效地学习到从起点到终点的最优路径。实验结果表明,学习率α、折扣因子γ和探索率ε的取值对算法的收敛速度和最终性能有显著影响。较大的学习率可以加快收敛速度,但可能导致震荡;较大的折扣因子可以使算法更加注重长远利益;较大的探索率可以提高算法的探索能力,避免陷入局部最优解,但可能降低收敛速度。合适的参数选择需要根据具体的迷宫大小和复杂度进行调整。
5. 结论与未来工作
本文通过Matlab代码实现了基于Q-learning算法和ε-greedy策略的随机方形迷宫寻路程序,并验证了算法的有效性。未来的工作可以考虑以下几个方面:
-
探索更复杂的迷宫环境,例如非方形迷宫、具有多个出口的迷宫等。
-
尝试其他强化学习算法,例如SARSA算法、Deep Q-Network (DQN)算法等,以提高算法的效率和性能。
-
研究更有效的探索策略,以加快算法的收敛速度。
-
将算法应用于实际的机器人导航等应用场景。
本文提供的代码框架可以作为进一步研究和改进的基础,读者可以根据自己的需求进行修改和扩展。 通过不断改进和优化,Q-learning算法将在解决更复杂的环境问题中发挥更大的作用。
⛳️ 运行结果
![]()
正在上传…重新上传取消

🔗 参考文献
🎈 部分理论引用网络文献,若有侵权联系博主删除
🎁 关注我领取海量matlab电子书和数学建模资料
👇 私信完整代码和数据获取及论文数模仿真定制
1 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化、背包问题、 风电场布局、时隙分配优化、 最佳分布式发电单元分配、多阶段管道维修、 工厂-中心-需求点三级选址问题、 应急生活物质配送中心选址、 基站选址、 道路灯柱布置、 枢纽节点部署、 输电线路台风监测装置、 集装箱船配载优化、 机组优化、 投资优化组合、云服务器组合优化、 天线线性阵列分布优化、CVRP问题、VRPPD问题、多中心VRP问题、多层网络的VRP问题、多中心多车型的VRP问题、 动态VRP问题、双层车辆路径规划(2E-VRP)、充电车辆路径规划(EVRP)、油电混合车辆路径规划、混合流水车间问题、 订单拆分调度问题、 公交车的调度排班优化问题、航班摆渡车辆调度问题、选址路径规划问题
2 机器学习和深度学习方面
2.1 bp时序、回归预测和分类
2.2 ENS声神经网络时序、回归预测和分类
2.3 SVM/CNN-SVM/LSSVM/RVM支持向量机系列时序、回归预测和分类
2.4 CNN/TCN卷积神经网络系列时序、回归预测和分类
2.5 ELM/KELM/RELM/DELM极限学习机系列时序、回归预测和分类
2.6 GRU/Bi-GRU/CNN-GRU/CNN-BiGRU门控神经网络时序、回归预测和分类
2.7 ELMAN递归神经网络时序、回归\预测和分类
2.8 LSTM/BiLSTM/CNN-LSTM/CNN-BiLSTM/长短记忆神经网络系列时序、回归预测和分类
2.9 RBF径向基神经网络时序、回归预测和分类















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









