






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
本文讲解如何使用 Q-learning 算法和 ε-greedy 策略来解决随机生成的方形迷宫问题。
首先,让我们了解一下 Q-learning 算法和 ε-greedy 策略:
**Q-learning 算法**是一种基于价值迭代的强化学习算法,用于学习如何在一个环境中做出行动以达到最大的累积奖励。在 Q-learning 中,我们通过更新一个 Q-table(或 Q 函数)来学习最佳策略。这个表存储了在给定状态下采取行动的预期回报。
**ε-greedy 策略**是一种在探索(explore)和利用(exploit)之间进行权衡的方法。在每一步中,ε-greedy 策略以 ε 的概率随机选择一个动作,以 1-ε 的概率选择当前状态下 Q 值最高的动作。
接下来,我们可以将这两种方法结合起来,使用 Q-learning 算法和 ε-greedy 策略来解决随机生成的方形迷宫问题。具体步骤如下:
1. **定义状态和动作**:首先,我们需要定义迷宫的状态和可以采取的动作。在方形迷宫中,每个格子可以看作是一个状态,可以向上、向下、向左、向右移动,这些动作就是可选的动作。
2. **初始化 Q-table**:创建一个 Q-table,其行代表状态,列代表动作。初始时,Q-table 可以初始化为零或者随机值。
3. **选择动作**:根据当前状态,使用 ε-greedy 策略选择一个动作。
4. **执行动作**:在环境中执行所选择的动作,观察奖励和下一个状态。
5. **更新 Q-table**:使用 Q-learning 更新规则更新 Q-table。
6. **重复步骤 3 至 5** 直到达到终止状态或者达到最大迭代次数。
7. **收敛**:通过反复迭代,Q-table 逐渐收敛到最优值函数,此时可以得到最佳策略。
8. **应用最佳策略**:根据 Q-table,选择每个状态下 Q 值最高的动作作为最佳策略。
这样,通过 Q-learning 算法和 ε-greedy 策略,我们可以解决随机生成的方形迷宫问题,并找到最佳路径以达到目标状态。


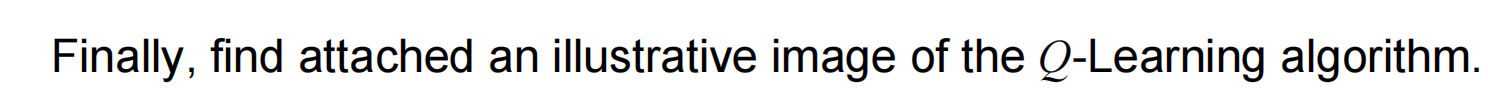
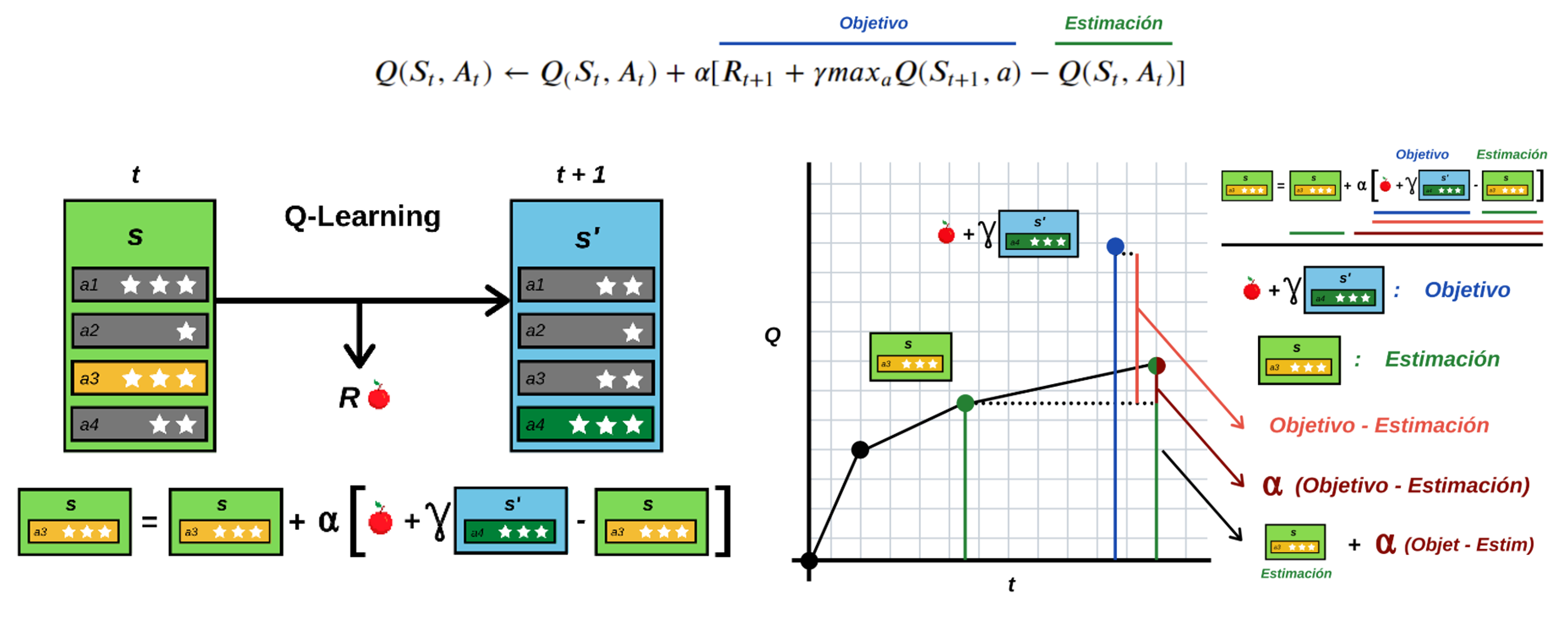


📚2 运行结果

部分代码:
% Colormaps for each maze plot
cmap_initial = [[0,0,0];[1,1,1];[1,0,0]];
cmap_solved = [[0,0,0];[1,1,1];[1,0,0];[1,0,1]];
%% Initial maze
figure(1)
clf
p1 = subplot(1,2,1);
imagesc(maze);
% Colormap
colormap(p1,cmap_initial)
% Start and End text
text(x_start_state,y_start_state,'START','HorizontalAlignment','center','Color','b')
text(x_end_state,y_end_state,'END','HorizontalAlignment','center','Color','b')
% Design of wall cells (Add white X symbol)
for i=1:n
for j=1:n
if maze(i,j) == 1 % wall_value
text(j,i,'X','HorizontalAlignment','center','Color','w') % text(x = columns = j, y = row = i,...)
end
end
end
% Subplot title and other requirements
title('Maze')
axis off
%% Solved maze
% Build solved maze matrix for plotting overwriting optimal path cells pmat(i,j) onto the basic maze matrix
maze_solved = maze;
for i=1:n
for j=1:n
if pmat(i,j) ~= 0 % 0 is empty cell pmat_matrix
maze_solved(i,j) = pmat(i,j);
end
end
end
% Recover color of start and end cells
maze_solved(start_state) = maze(start_state);
maze_solved(end_state) = maze(end_state);
% Plotting solved maze
p2 = subplot(1,2,2);
imagesc(maze_solved)
% Colormap
colormap(p2,cmap_solved)
% Start and End text
text(x_start_state,y_start_state,'START','HorizontalAlignment','center','Color','b')
text(x_end_state,y_end_state,'END','HorizontalAlignment','center','Color','b')
% Design of wall and solved path cells (Add white X and * symbols)
for i=1:n
for j=1:n
if maze_solved(i,j) == 1 % wall_value
text(j,i,'X','HorizontalAlignment','center','Color','w')
elseif maze_solved(i,j) == 4 % path color
text(j,i,'*','HorizontalAlignment','center','Color','w')
end
end
end
% Subplot title and other requirements
title('Solved Maze')
axis off
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
















 5030
5030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









