







有这样一类需求:让你维护一些集合,可以执行合并集合,查询两个数是否在一个集合中,以及可能还有一些其他奇怪的操作。
那么首先想到的暴力做法就是,开一个数组,让在一个集合中的数都等于相同的值。但是这样做的话,假设有一万个点在集合1里,有两万个点在集合2里,要合并的话,首先要遍历一遍全部数组,把所有在集合1里的点挑出来,然后再让他们等于集合2的值,这样显然是十分愚蠢的。
并查集就可以很好地维护这样的集合。并查集的思想就是,开一个数组记录所有点的祖宗节点,并且一个集合的根节点就是这个集合的编号。举个例子就是:

意思是:下标代表点的编号,而数组值代表他的父节点是谁。我们可以发现:当数组值等于下标值的时候,说明这个点就是根节点,否则它就是某一子节点。目前他对应的集合含义是:
那么这时候有一个合并集合的操作。假设给出两个点:点1、点2,现在它们都在一个集合中,要和并这两个集合。那么只需要把点2的根节点直接接到点1的根节点上即可。举例说明:
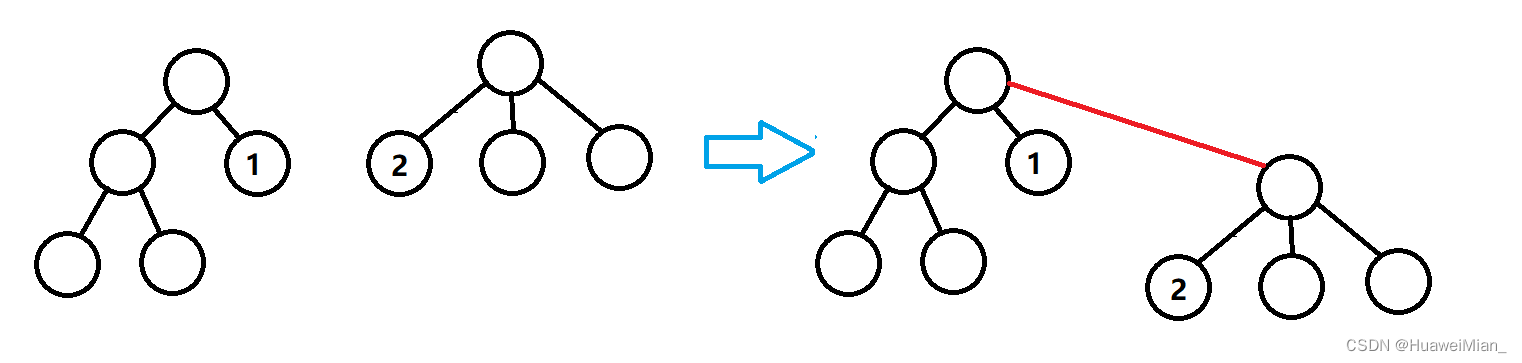
所以可以看到,这里需要费时间的操作就是找到根结点的操作。我们需要一个函数来找到每个点的祖宗节点,还需要一个数组来记录一下每个点的父节点是谁:
//数组作用:存储每个点的父节点
int p[N];
//函数作用:找到点x的根节点
int find(int x)
{
//依次向上找,直到找到根节点
while (x != p[x]) x = p[x];
return x;
}
那么合并操作就是:
//找到a的根节点,并且让其父节点等于b的根节点
//意思就是把a所在的集合接到b所在的集合上了,也就实现了合并
p[find(a)] = find(b);
查询操作就更加简单了,只要看看两个点的根节点是不是一样的即可(因为根节点代表集合编号)。
这里还有一个问题。设想一种情况:一开始把点1接到点2上,然后把点2接到点3上,然后把点3接到点4上……就会出现这样一个非常坏的集合:
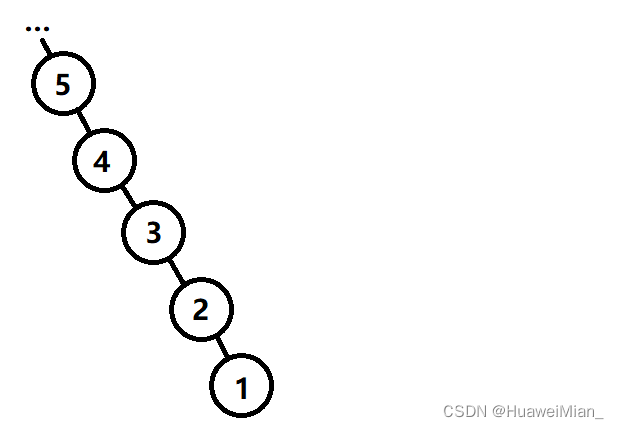
因为找到一个点的根节点是需要递归上去的,越摞越高的话,查询的时间复杂度会非常高。因为集合问题中,树的形状并不重要。所以这里用到了一个路径压缩的思想:意思就是,递归某一条路径寻找根节点时,把路径上所有的点在递归的同时接到根节点上。这样一来,只有一次会很麻烦的查询,后续查询就非常快了。这样就要对find函数做一些小小的修改了:
int find(int x)
{
if (x != p[x]) p[x] = find(p[x]);
return p[x];
}
这个递归函数非常精妙,建议自己用纸和笔模拟一下体会它的精妙之处。它的作用是:找到x的根节点(也即集合编号),同时把路径上所有的点都接到根节点上。举个例子:
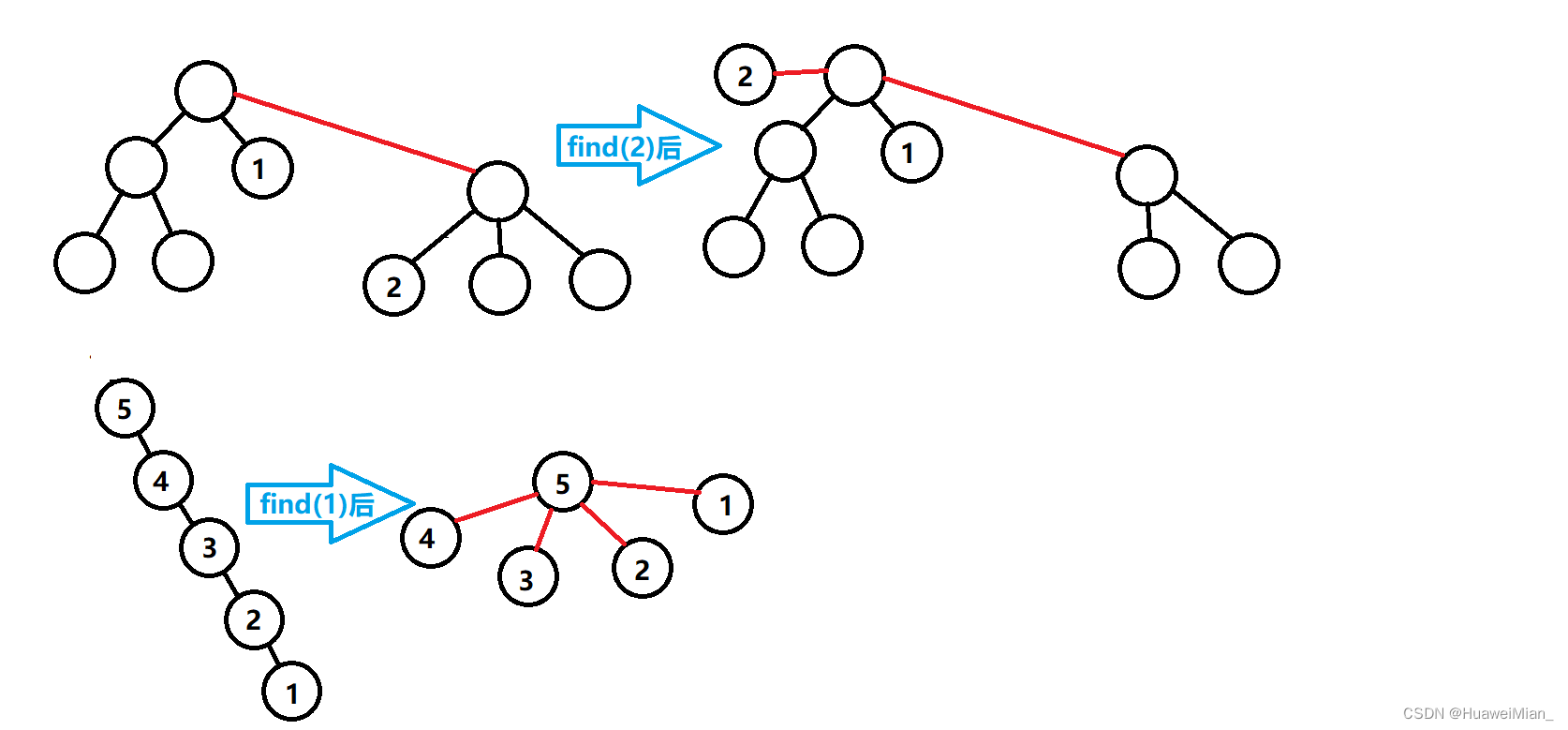
接下来给出一道裸题和题解:
原题acwing 合并集合
一共有 n 个数,编号是 1∼n,最开始每个数各自在一个集合中。
现在要进行 m 个操作,操作共有两种:
M a b,将编号为 a 和 b 的两个数所在的集合合并,如果两个数已经在同一个集合中,则忽略这个操作;
Q a b,询问编号为 a 和 b 的两个数是否在同一个集合中;
输入格式
第一行输入整数 n 和 m。
接下来 m 行,每行包含一个操作指令,指令为 M a b 或 Q a b 中的一种。
输出格式
对于每个询问指令 Q a b,都要输出一个结果,如果 a 和 b 在同一集合内,则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1≤n,m≤105
输入样例:4 5
M 1 2
M 3 4
Q 1 2
Q 1 3
Q 3 4输出样例:
Yes
No
Yes
#include <iostream>
#include <cstdio>
using namespace std;
const int N = 100010;
int p[N];
//核心操作
int find(int x)
{
if (x != p[x]) p[x] = find(p[x]);
return p[x];
}
int main()
{
int n, m;
cin >> n >> m;
for (int i = 0; i < n; i ++ ) p[i] = i;
while (m -- )
{
char op[5];
int a, b;
scanf("%s%d%d", op, &a, &b);
if (*op == 'M') p[find(a)] = find(b);
else
{
if (find(a) == find(b)) puts("Yes");
else puts("No");
}
}
return 0;
}
并查集还允许维护一些奇怪的操作,比如查询当前集合中点的数量,那么需要自己构思如何实现。这里给出维护点的数量版本的代码,其他奇怪的操作大家可以自己想办法实现:
#include <iostream>
#include <cstdio>
using namespace std;
const int N = 100010;
//cnt记录某个集合中点的数量
int p[N], cnt[N];
//核心操作是不变的
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int main()
{
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i ++ )
{
p[i] = i;
cnt[i] = 1;
}
while (m -- )
{
char op[5];
int a, b;
scanf("%s", op);
//输入C合并集合
if (!strcmp(op, "C")
{
scanf("%d%d", &a, &b);
a = find(a), b = find(b);
//排除两个点已经在同一集合的情况
if (a!= b)
{
p[a] = b;
cnt[b] += cnt[a];
}
}
//输入Q1查询两点是否在一个集合中
else if (!strcmp(op, "Q1")
{
scanf("%d%d", &a, &b);
a = find(a), b = find(b);
if (find(a) == find(b)) printf("Yes\n");
else printf("No\n");
}
//输入Q2查询某个点所在集合中点的数量
else
{
scanf("%d", &a);
printf("%d\n", cnt[find(a)]);
}
}
return 0;
}















 1580
1580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









