









Transformer
壹、整体架构
Transformer 代替了RNN网络,在传统的RNN网络中,训练的时候是一个马尔可夫过程,即每一层中的输出都需要上一步输出的中间结果,传统的RNN无法做到并行,在Transformer中,使用Self-Attention机制来进行并行计算,输出结果是同时被计算出来的,并行计算只存在于在训练阶段,现在基本已经取代RNN了。
整体架构:
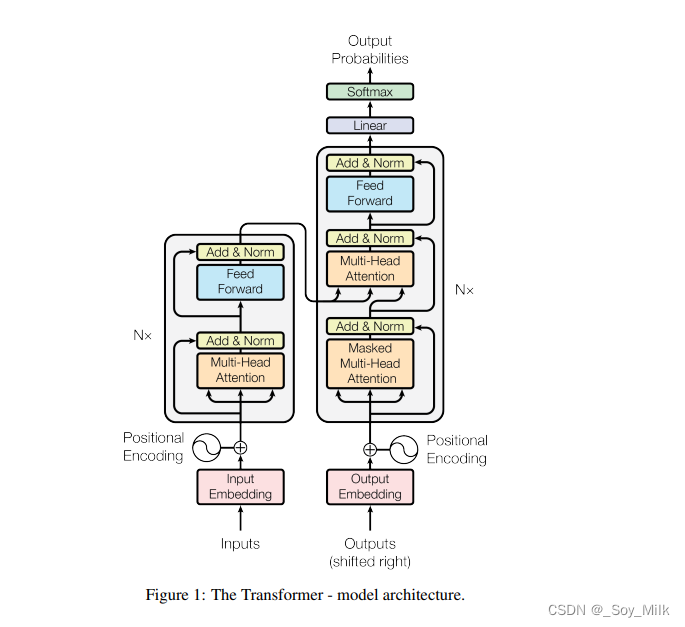
贰、 Transformer网络详解:
Transformer网络可分为两个部分:Encoder层与Decoder层,并且Encoder和Decoder重复了N次。
1. 输入数据的构造:
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
在输入数据中,P表示的是原句子的结束标志,S表示翻译后的句子的开始标志,E也表示结束标志,向Transformer中输入enc_input 和 dec_input然后进行计算损失的时候与dec_output进行计算,dec_input与dec_output的每一个词正好错开一个位置,这样dec_input的每一个词通过网络后得到概率正好是下一个词的概率。
输入数据的预处理操作:
- 对输入的句子的每一个单词进行
WordEmbedding(词向量编码操作)。 - 对输入句子每一个单词进行
PositionalEncoding(位置编码操作)。 - 将两次的编码得到的向量进行相加得到最终的输入,这一步是将位置信息嵌入到词向量中。
2. 词向量编码:
词向量编码是将每个词编码为向量的形式,其向量的大小是自定义的。在Pytorch中,可以使用 nn.Embedding(num_embeddings, embedding_dim)来对词进行编码,其中num_embeddings表示的是输入的词的个数,embedding_dim表示对每一个词进行编码为多长词向量。然后通过输入到改编码层中即可得到编码后的结果,编码后的大小为:shape = (num_embeddings, embedding_dim)。
self.src_emb = nn.Embedding(src_vocab_size, d_model) # 先实例化编码层
enc_outputs = self.src_emb(enc_inputs) # 然后在输入数据
3. 位置编码:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i d m o d e l ) p o s :表示某一个位置 2 i :表示偶数 2 i + 1 :表示奇数 PE_{(pos, 2i)} = \sin{(\frac{pos}{10000^{\frac{2i}{d_{model}}}})} \\ PE_{(pos, 2i + 1)} = \cos{(\frac{pos}{10000^{\frac{2i}{d_{model}}}})}\\ pos:表示某一个位置 ~~~ 2i:表示偶数 ~~~ 2i + 1:表示奇数 PE(pos,2i)=sin(10000dmodel2ipos)PE(pos,2i+1)=cos(10000dmodel2ipos)pos:表示某一个位置 2i:表示偶数 2i+1:表示奇数
通常在代码中使用 e ( − 2 i d m o d e l × log 10000 ) e^{(-\frac{2i}{d_{model} } \times \log{10000})} e(−dmodel2i×log10000)来替换 1 / 1000 0 2 i d m o d e l 1 / 10000^{\frac{2i}{d_{model}}} 1/10000dmodel2i,目的是为了提高计算效率。这样做可以减少计算中的指数运算,因为计算机通常能更高效地处理指数的自然对数形式。
代码中预先生成的是长度为max_len = 5000的位置编码(max_len是可以通过参数来自定义的,自己需要多少个词的位置编码就设定生成多少个),在进行词向量与位置编码相加的时候,还要再将位置编码切片为具体需要位置编码的个数。
代码实现:
# 位置编码的实现
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000): # max_len:表示预先设定最大的位置编码长度
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout) # 以0.1的概率对神经元进行随机失活,提高模型的泛化能力,防止过拟合
# pe用于存储位置编码信息, 首先定义pe为一个0矩阵,大小为[5000, 512]
pe = torch.zeros(max_len, d_model)
# position用于表示单词在句子中的位置
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# torch.arange()用于创建一个具有一定范围的一维张量,unsqueeze用于在张量的维度 1 处添加一个新的维度
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1) # transpose()用于交换张量的维度顺序
self.register_buffer('pe', pe) # 注册缓冲区,其参数为缓冲区的名字与缓冲区存储的值,简单理解为这个参数不更新就可以
def forward(self, x):
x = x + self.pe[:x.size(0), :]
# 将词向量与位置编码进行相加,并且对需要进行位置编码的部分进行切片。
return self.dropout(x)
4. 多头注意力机制
计算得分的公式: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k V ) Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}} V) Attention(Q,K,V)=softmax(dkQKTV)
点乘的含义:点乘可以表示为一个向量在另一个向量的投影,这可以反应两个向量之间的相似度。
如何获取Q,K,V?
注意力层中,将输入的词向量与参数矩阵 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV 进行相乘即可得到Q、K、V,在代码中 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV其实就是一个线性层。
在多头注意力机制中,通常使用多套参数,即多组 W W W, ( W 0 Q , W 0 K , W 0 V , W 1 Q , W 1 K , W 1 V , W 2 Q , W 2 K , W 2 V ) (W_0^Q, W_0^K, W_0^V, W_1^Q, W_1^K, W_1^V, W_2^Q, W_2^K, W_2^V) (W0Q,W0K,W0V,W1Q,W1K,W1V,W2Q,W2K,W2V)这样效果好的原因可能是使Transformer注意到潜空间中的不同位置,可以注意到更多的特征信息。在最后会得到多个值( Z , ( Z 0 , Z 1 , ⋯ , Z 7 ) Z, (Z_0, Z_1, \cdots ,Z_7) Z,(Z0,Z1,⋯,Z7) ),将每一个头的输出合并到一起,乘以一个矩阵(线性层),即得到多头注意力的输出。
Q Q Q与 K T K^T KT点乘的意义:
-
向量点乘的几何意义是:向量 X X X在向量 Y Y Y方向上的投影在与向量 Y Y Y的乘积,能够反映两个向量的相似度。点乘结果越大两个向量越相似。
-
X ⋅ X T X · X^T X⋅XT:表示X中各个行向量的相似度,如: X 0 ⋅ X 0 X_0 · X_0 X0⋅X0表示第一行与第一行的相似度,再如 X 2 ⋅ X 3 X_2 · X_3 X2⋅X3表示第三行与第四行的相似度。
-
如果每一个行向量代表具体的实例,如词向量矩阵则每一行表示每一个词向量那么 X ⋅ X T X · X^T X⋅XT表示各个词向量各个词之间的相似程度。
-
最后进行 s o f t m a x softmax softmax,表示进行归一化处理,各个值将其变为百分数,再与X相乘得到的是词向量经过加权求和之后的新表示。
除以 d k \sqrt {d_k} dk的原因:
将内积结果除以 d k \sqrt{d_k} dk,可以控制得分的尺度,确保不会出现过大或过小的值。这是因为内积的结果通常会随着输入维度的增加而增大,为了避免得分过大导致梯度爆炸或者过小导致信息丢失,使用 d k \sqrt{d_k} dk进行缩放。
除以 d k \sqrt{d_k} dk还有一个好处是可以提高不同维度特征的区分度,因为相较于较小的 d k d_k dk,较大的 d k d_k dk 可以使得得分更加平缓和均匀。这有助于模型更好地捕捉输入之间的相关性和重要性。
代码中首先是Q与K进行相乘(假设得到的结果为A),如果Q和K都是相同的数据生成的,那么表示的是这些数据之间的相关性,并且每个词与本身的相关性最大,如果Q和K是不同的数据生成的,那么表示的是不同数据之间的相关性,是不同句子的不同词之间的相关性。然后A矩阵再与V矩阵进行相乘,得到最后的得分矩阵,最后的得分矩阵中的值表示的是每一个词嵌入与其它词之间的相关性的信息。
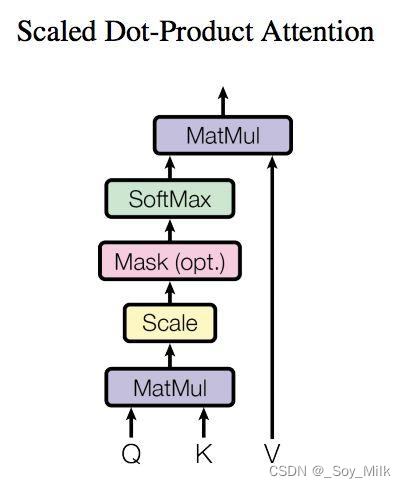
掩码机制(mask)
在Transformer中一共涉及到了两种mask。
第一种mask是规范化输入数据的时候,在一个batch_size中,由于句子中的词的个数可能不是相等的,我们需要将所有句子与最长的句子的长度设置为相等的大小,并且用0进行填充,用0填充以后,在计算注意力得分的时候还需要将填充的部分进行屏蔽掉 ,因为填充的部分与原来句子中的所有词都是没有关系的,第一种mask应用在Encoder的注意力层和Decoder的第一个注意力层种。
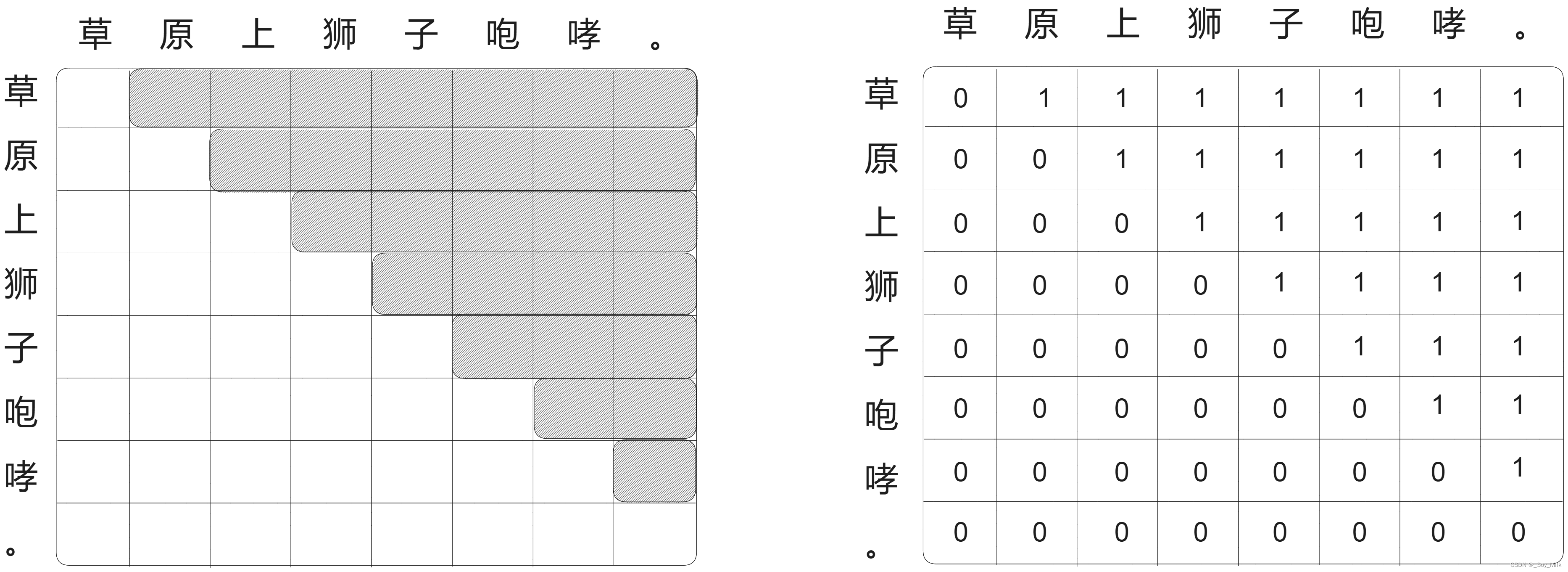
第二种mask是在屏蔽掉未来词的信息的时候,训练模型时,mask是为了让decoder输出的时候只能参考前面词的信息,而不是整个句子的全部信息,如果知到了后面的全部信息,因为我们在这是预测的时候不知道后面的信息的,因此我们需要将后面的信息进行mask,在代码实现时,其实就是生成了一个上三角矩阵,需要掩盖的部分设置为1,正常的部分设置为0,再计算得分的时候使用这个mask矩阵,将每个词和其之后的词的相关概率进行抹除。如下图,每一个词语只能和之前的词语有相关概率,和之后的词语的相关概率都被mask掉了。
代码实现:
第一种mask:
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
# eq(0) 表示将该张量中值等于 0 的元素变为 True,其余元素变为 False,表示那些部分是填充的
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k],
最后返回的时候,将维度扩展为len_q,len_k 是因为在计算注意力得分的时候,mask掉的是句子填充的部分。因为计算注意力得分的时候需要一个相关性矩阵,而mask正是在这一步起作用的,将句子扩充的部分的相关性进行抹除(因为扩充的部分本身和句子中的每一个词就没有相关性),len_q和len_k分别表示的是两个句子的词的个数(这两个句子可能相同也可能不同,因为使用第一种mask的时候三种多头注意力层都用到了,如果是自注意力,那么两个句子是相同的,如果是交叉注意力,那么这两个句子是不同的)扩充为len_q和len_k正好与相关性矩阵的shape一致,可以直接在相关性矩阵上进行mask。
第二种mask:
def get_attn_subsequence_mask(seq):
attn_shape = [seq.size(0), seq.size(1), seq.size(1)] # 这一步和上面的解释一致
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 将值为1的单位矩阵得到上三角部分(其余部分使用0进行填充)
subsequence_mask = torch.from_numpy(subsequence_mask).byte() # 将numpy创建为tensor类型
return subsequence_mask
三个多头注意力层的理解:
在具体的Transformer代码中,一共涉及到3处使用多头注意力的地方,分别是Encoder中的一个多头注意力层,和Decoder中的两个多头注意力层,我们来具体来了解一下这三个多头注意力层是如何工作的。
Encoder中的多头注意力层,其输入只有enc_inputs(编码端的输入),然后Q、K、V都是通过enc_inputs进行生成的,这个多头注意力层的作用是对编码端的每一个词都嵌入与其它词之间的相关性,即输入端词与词的位置、语义关系。
Decoder中的第一个多头注意力层,其输入只有dec_inputs(解码端的输入),然后Q、K、V也都是通过dec_inputs进行生成的,这个多头注意力层的作用是解码端的每一个词都嵌入与其它词之间的相关性,即解码端词与词的位置、语义关系。看起来这个多头注意力层的作用与Encoder中的多头注意力层的功能几乎一样,但是有一点不同的是因为解码端是翻译任务中的目标语言,需要注意力去学习这个词与词之间的语义关系,因此需要一个mask机制(接下来的部分会进行说明),使注意力不能直接看到词与词之间的相关性,只能看到某个词语与之前词语的相关性,与之后词语的相关性是需要去学习的,而这个学习过程是通过反向传播来实现的。
Decoder中的第二个多头注意力层,输入一共有两部分,一部分是解码端的输出(enc_outputs),和Decoder中上一个注意力层的输出(dec_outputs_temp),然后Q是通过dec_outputs_temp来生成的,K、V是通过enc_outputs来生成的。这个多头注意力层的作用是以编码端的输出作为参照然后去生成概率矩阵,Q与K进行矩阵乘法,得到的是enc_outputs与dec_outputs各个词语之间的相关性,然后这个相关性矩阵再与V进行矩阵乘法,得到的是dec_output中的各个词语与这个相关性矩阵相乘后的结果,这个相关性矩阵既融了dec_outputs各个词语之间的相关性信息又融入了enc_outputs各个词语之间的相关性信息,还又dec_outputs与enc_outputs各个词语之间的相关性信息,这样可以很好的参照全局的信息进行生成概率矩阵,这样在进行预测的时候,根据不同的enc_inputs,可以得到不同的注意力,从而可以生成不同的dec_outputs。
# 多头注意力
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
residual, batch_size = input_Q, input_Q.size(0)
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1, 2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
# attn_mask : [batch_size, n_heads, seq_len, seq_len], 第二个维度重复8次,其它维度不重复.
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
# 计算注意力的得分,传入参数(Q, K, V, attn_mask), 得到一个最终的得分和一个相似度矩阵
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v],将多个头进行合并
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).cuda()(output + residual), attn # attn是一个得分矩阵
计算自注意力得分:
计算得分的公式: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k V ) Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}} V) Attention(Q,K,V)=softmax(dkQKTV)
# 计算自注意力的得分
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k], 将k的倒数第1个维度与倒数第2个维度进行交换,然后再进行矩阵的乘法。
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True. 将mask的部分置为负无穷大, 当值为负无穷的时候softmax之后的值才会是0
attn = nn.Softmax(dim=-1)(scores) # 在scores的最后一个维度上进行softmax操作。
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v] 执行矩阵的乘法
return context, attn # 返回的是一个相似度的结果与一个相似度矩阵
可以说整个模型最重要的部分就是每个多头注意力层的 W Q , W K , W V W^Q, W^K,W^V WQ,WK,WV 这三个线性层了,每个多头注意力层的这三个线性层学到的分别是编码端各个词之间的相关性,解码端各个词之间的相关性,以及编码端和解码端之间各个词的相关性。
Q,K,V的交互流程图
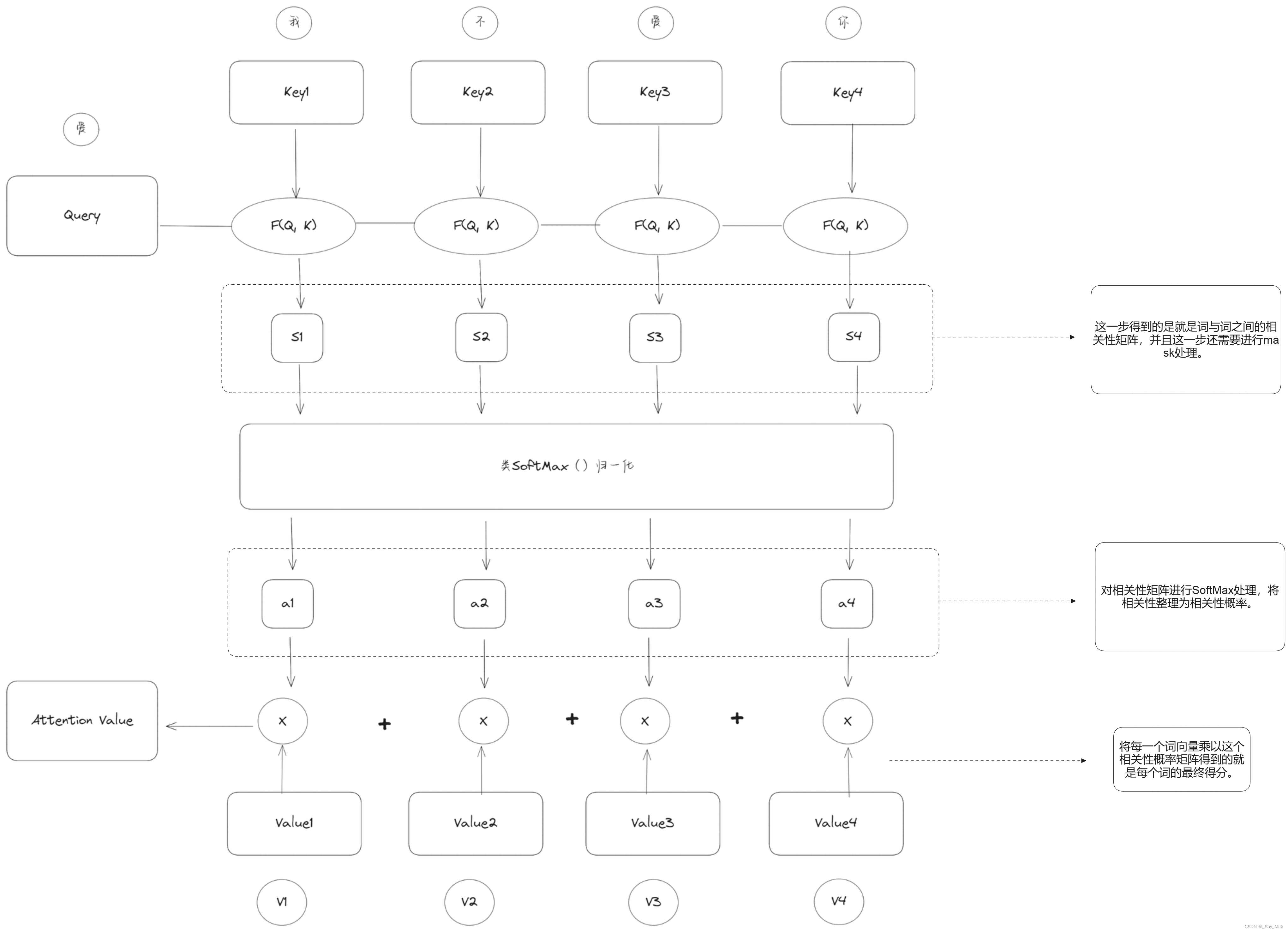
叄、 代码详解
一、 Transformer模型
__init__方法
- 定义编码器(
Encoder)- 定义解码器(
Decoder)- 定义全连接层(
Linear),这个层的作用主要是规范化输出,将输出映射为词表的长度。
forward方法
- 将原句子输入到编码端,得到编码端的输出(一个嵌入词与词之间相关性信息的词向量和一个注意力层的相关性矩阵)。
- 将编码端的输入、解码端的输入以及编码器的输出一起输入到解码器端中,这里输入编码端的输入只是为了生成编码端的第一种
mask矩阵,因为在交叉注意力层中,编码端扩充的部分和任何词都是没有关系的,需要进行mask掉。- 解码端的输出:第一个输出是嵌入了编码端各个词之间的序列语义关系、解码端各个词之间的序列语义关系、编码端和解码端之间各个词的序列语义关系的词向量,第二个和第三个输出都是两个多头注意力层的相关性矩阵。
- 将解码端的输出输入到最后的全连接层,改变维度,映射为词表长度,得到每一个位置预测词表中每一个词的概率。
- 最后通过view改变维度,将
batch维度与每一个词的维度进行合并(例:如果batch是2那么说明有两个句子,每个句子又有n个词,将batch与每一个词的维度进行合并得到的就是 b a t c h × n batch\times n batch×n个词,也就是得到了一次输入中每一个词在词表中的概率,即输出的维度为:[ b a t c h × n batch \times n batch×n,tgt_vocab_size])。
# Transformer模型定义
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder().cuda() # 编码器
self.decoder = Decoder().cuda() # 解码器
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).cuda() # 线性全连接层,输出层
# 接收两个参数,编码端的输入与解码端的输入
def forward(self, enc_inputs, dec_inputs):
enc_outputs, enc_self_attns = self.encoder(enc_inputs) # 编码端输入带翻译句子
# dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs) # 解码端的输入:解码端的输入、编码端的输入、编码端输出
dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, tgt_len, tgt_vocab_size] # 映射词表操作
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns # enc_self_attns, dec_self_attns, dec_enc_attns分别表示的是三个注意力层的相关性矩阵。
二、Encoder端
1. 编码器(Encoder)
__init__方法
- 定义编码器
- 定义位置编码器
- 定义N个(代码中N=6)
EncoderLayer。
__forward__方法
- 首先对输入的数据通过编码器进行编码,将数字索引转化为词向量。
- 将词向量输入到位置编码器中,将词向量与位置编码进行相加,得到的是嵌入位置信息的词向量。
- 生成
mask矩阵,对句子中进行填充的部分进行标记,生成一个bool类型的矩阵,填充的部分标记为True。- 将嵌入位置信息的词向量与
mask矩阵一同输入到EncoderLayer中,然后重复N次。- 得到最终的注意力得分矩阵。
Embedding操作:直接使用Pytorch提供的nn.Embedding()方法,传入的参数是需要编码的词的个数和每个词需要生成多长的编码,返回一个矩阵,每一行表示一个词的编码。
# 编码器
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) # 词向量层,对原词表的每一个词都设置一个d_model大小的词向量。
self.pos_emb = PositionalEncoding(d_model) # 位置编码层
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model] 进行编码,通过数字索引转化为对应的向量
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model]
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len] [2, 5, 5],生成mask矩阵。
enc_self_attns = []
for layer in self.layers: # 对每一个layer进行循环
# enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) # 对每一个layer输入加入位置编码的词向量以及需要掩盖的部分
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns # 返回的是一个编码器输出的结果和N个EncoderLayer(通过列表的形式)
2. 位置编码(PositionalEncoding):
__init__方法
- 定义一个随机失活层,目的是提高模型的泛化能力,防止过拟合。
- 定义一个大小为
max_len, d_model的0矩阵,max_len初始赋值为5000,表示初始设定有5000个词需要进行位置编码;这个值也可以通过参数进行赋值为需要编码的词的个数,在最后进行相加的时候还会依据真实词的个数对编码进行切片。- 使用
arange方法生成从0 ~ max_len的序列,表示每一个单词在句子中的位置。- 通过公式: P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i d m o d e l ) PE_{(pos, 2i)} = \sin{(\frac{pos}{10000^{\frac{2i}{d_{model}}}})} \\PE_{(pos, 2i + 1)} = \cos{(\frac{pos}{10000^{\frac{2i}{d_{model}}}})}\\ PE(pos,2i)=sin(10000dmodel2ipos)PE(pos,2i+1)=cos(10000dmodel2ipos) 得到最终的位置编码信息,在代码我们使用: e ( − 2 i d m o d e l × log 10000 ) e^{(-\frac{2i}{d_{model} } \times \log{10000})} ~~~~ e(−dmodel2i×log10000) 来替换 1 / 100 0 2 i d m o d e l 1 / 1000^{\frac{2i}{d_{model}}} 1/1000dmodel2i部分。
- 整理维度信息为,将
batch的信息与词个数的信息进行交换。- 存储到缓冲区中,缓冲区不会在反向传播中被更新。通过在模型中注册缓冲区,可以避免在每次前向传播时重新计算相同的中间状态,从而减少计算量和内存开销。
__forward__方法
- 将位置编码与输入已经编码的词在
batch维度进行相加(这里使用了广播机制,对batch_size的每一个batch都进行了相加)- 通过一个随机失活层后进行返回。
# 位置编码的实现
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout) # p=dropout表示以0.1的概率对神经元进行随机失活,提高模型的泛化能力,防止过拟合
# pe用于存储位置编码信息, 首先定义pe为一个0矩阵,大小为[5000, 512]
pe = torch.zeros(max_len, d_model)
# position用于表示单词在句子中的位置
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # torch.arange()用于创建一个具有一定范围的一维张量,unsqueeze用于在张量的维度 1 处添加一个新的维度, [5000, 1]
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # 对应公式
pe[:, 0::2] = torch.sin(position * div_term) # 在列中,从0开始步长为2进行读取,偶数
pe[:, 1::2] = torch.cos(position * div_term) # 奇数
pe = pe.unsqueeze(0).transpose(0, 1) # transpose()用于交换张量的维度顺序,[5000, 1, 512]
self.register_buffer('pe', pe) # 注册缓冲区,其参数为缓冲区的名字与缓冲区存储的值,简单理解为这个参数不更新就可以
def forward(self, x):
x = x + self.pe[:x.size(0), :] # 将词向量与位置编码进行相加, 这里x为[5, 2, 512], pe为[5000, 1, 512], 这里的加法为在维度2上进行累加,在这里进行了切片,只取需要进行编码的部分,因此实际相加的是[5, 1, 512]
return self.dropout(x)
3. 掩码(Padding):
掩码的主要作用是标记出句子中padding的部分,首先得到batch的大小与句子的长度,然后将输入的矩阵中值为0的用True进行标记(因为填充的时候是使用数值0进行填充的),其其它部分使用False进行标记,表示这些部分不是填充的部分,将得到的pad_attn_mask进行扩充为矩阵的形式,以便在后面对相关性矩阵进行标记。这里有一个巧妙的部分是在encoder端输入的时候句子中有一个标记符号P表示结束的位置,P在词表中的索引也为0,因此也会被mask掉,这很巧妙,因为P本身和句子各个词之间并没有相关性。
def get_attn_pad_mask(seq_q, seq_k): # seq_q = seq_k = enc_input/dec_input
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], False is masked # eq(0) 表示将该张量中值等于 0 的元素变为 True,其余元素变为 False,表示那些部分是填充的
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k], 这里扩展为len_q, len_k 是因为,在计算得分的时候需要进行标记,k,v矩阵相乘得到的维度是[batch_size, 5, 5],将掩码矩阵设置为这样是为了方便标记。
4. 编码层(EncoderLayer):
__init__方法
- 多头自注意力层
- 位置感知前馈神经网络层
__forward__方法
- 将
encoder端嵌入位置编码的词向量和mask输入到多头自注意力层中,得到注意力得分矩阵,和相似度矩阵- 将注意力得分矩阵输入到前馈神经网络中,得到嵌入了各个词之间相关性的词向量。
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention() # 多头注意力层
self.pos_ffn = PoswiseFeedForwardNet() # 位置感知前馈神经网络
def forward(self, enc_inputs, enc_self_attn_mask):
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs,enc_self_attn_mask)
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn # 返回的是一个编码层的输出与相似度矩阵
5. 多头注意力层(MultiHeadAttention):
__init__方法
- 定义三个线性层,分别表示 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV,并且默认设定为8个头,即8组 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV。
- 定义一个线性层,用于将多头注意力生成的结果进行合并处理。
__forward__方法
- 首先需要将原来的Q进行复制下来(
residual),以便残差网络进行相加操作。- 将输入的词向量分别通过 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV之后,使用
view及那个8个头进行分离出来,得到8个头的输出矩阵QKV。- 调整mask的维度,将QKV与mask一并输入到得分矩阵中,得到最后的得分与词与词之间的相关性矩阵。
- 各个头生成的得分进行合并,在通过一个一个线性层进行整理。
- 最后将结果通过一个归一化模块之后,再通过残差网络与
residual进行相加得到最终的输出。返回的维度与输入的维度一致。
# 多头注意力
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False) # d_k = d_v = 64, => 64 * 8
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
residual, batch_size = input_Q, input_Q.size(0) # input_Q = input_K = input_V (and shape = (2, 5, 512))
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1, 2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask) # 计算注意力的得分,这一行表示实例化类,并且传入参数(Q, K, V, attn_mask), 得到一个最终的得分和一个相似度矩阵
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v] 将多个头进行合并
output = self.fc(context) # [batch_size, len_q, d_model] # 最终的结果输入到一个线性层进行输出
return nn.LayerNorm(d_model).cuda()(output + residual), attn # attn 是一个相似度矩阵。
6. 计算得分(ScaledDotProductAttention):
公式: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k V ) Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}} V) Attention(Q,K,V)=softmax(dkQKTV)
__init__方法
- 继承父类
ScaledDotProductAttention。
__forward__方法
- 将Q矩阵与K矩阵进行矩阵的乘法,并除以 d k \sqrt{d_k} dk,得到相关性矩阵。
- 将相关性矩阵进行mask,mask的部分(即值为True的部分)使用负无穷大的值进行填充,因为我们之后进行SoftMax的时候,需要将mask的部分的相关性置为0,又有前提条件:只有当值为负无穷时,SoftMax之后的值才会是0。
- 进行SoftMax操作。
- 再将相关性矩阵与矩阵V进行相乘,得到最后的得分矩阵。
- 返回得分矩阵与相关性矩阵。
# 计算自注意力的得分
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True. 将mask的部分置为负无穷大,只有当值为负无穷的时候softmax的值才会是0
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v] 执行矩阵的乘法
return context, attn # 返回的是一个相似度的结果与一个相似度矩阵
7. 前馈神经网络层(PoswiseFeedForwardNet):
__init__方法
- 继承父类
PoswiseFeedForwardNet。- 定义容器:线性层、RelU激活函数、线性层。
__forward__方法
- 复制输入的数据(
residual),以便于后面残差网络进行相加操作。- 将输入输入到容器中,得到输出结果
- 将输出的结果与
residual进行相加,并且送入到归一化层中进行归一化操作。
# 位置感知的前馈神经网络
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).cuda()(output + residual) # [batch_size, seq_len, d_model]
三、 Decoder端
1. 解码器(Decoder):
__init__方法
- 继承父类
Decoder。- 定义编码器。
- 定义位置编码器。
- 定义N个(代码中设定N=6)
DecoderLayer。
__forward__方法
- 将解码端的词通过编码器进行编码,将数字索引转换为词向量。
- 将词向量送入到位置编码层,得到的是嵌入位置信息的词向量。
- 计算
decoder端的pad_mask(填充部分的掩码)。- 得到掩盖未来词的
subsequence_mask矩阵(上三角矩阵)。- 将两个
mask矩阵进行合并得到最终的mask矩阵。- 得到
encoder端的pad_mask,因为encoder端也有词是填充的,与其它的词之间没有相关性。- 将解码端嵌入位置信息的词向量和编码端的输出以及两个
mask矩阵一同输入到DecoderLayer中。- 得到最终的注意力得分矩阵。
# 解码器
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) # 编码
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) # 6个layer
def forward(self, dec_inputs, enc_inputs, enc_outputs):
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).cuda() # [batch_size, tgt_len, d_model]
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() # [batch_size, tgt_len, tgt_len] # 计算一次pad
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda() # [batch_size, tgt_len, tgt_len] # 对未来单词进行mask,使用一个上三角矩阵(值为1)
# 两个矩阵进行相加,大于0的部分为1,不大于0的部分为0,为1的在之后就会被fill到无穷小
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0).cuda() # [batch_size, tgt_len, tgt_len]
# 交互注意力层中使用的mask(掩盖未来的词)
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers: # 对每一层(6个层)进行遍历
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask,
dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn) # 添加masked的多头注意力层的相似矩阵
dec_enc_attns.append(dec_enc_attn) # 添加多头注意力层的相似矩阵
return dec_outputs, dec_self_attns, dec_enc_attns # 返回encoder的输出、masked的多头注意力层的相似矩阵列表、多头注意力层的相似矩阵列表
2. 掩盖未来词(get_attn_subsequence_mask):
- 首先构造一个
mask的shape形状。 - 使用
np.triu()方法构造出上三角矩阵,上三角部分的值为1,其余部分的值为0。 - 将
numpy类型转换为torch数据类型。 - 返回这个上三角矩阵。
# 防止decoder在进行解码的时候掌握到未来单词的信息
def get_attn_subsequence_mask(seq):
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix # 将值为1的单位矩阵得到上三角部分(其余部分使用0进行填充)
subsequence_mask = torch.from_numpy(subsequence_mask).byte() # 将numpy创建为tensor类型
return subsequence_mask # [batch_size, tgt_len, tgt_len]
3. 解码层(DecoderLayer):
__init__方法
- 多头自注意力层。
- 多头交叉注意力层。
- 位置感知前馈神经网络层。
__forward__方法
- 将
decoder端嵌入位置编码的词向量输入到多头自注意力层中,得到注意力得分矩阵,和相似度矩阵。- 将解码端的多头自注意力得分和编码端的多头自注意力得分以及编码端的
mask都输入到多头交叉注意力层中,得到交叉注意力得分矩阵,以及相似度矩阵。- 将交叉注意力得分矩阵通过前馈神经网络之后进行返回。
# 解码器层
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention() # 多头自注意力层
self.dec_enc_attn = MultiHeadAttention() # 多头交叉注意力层
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask) # 多头交叉注意力层
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn # dec_self_attn, dec_enc_attn 分别是decoder端两个注意力层得到的相似度矩阵。
四、数据集
1. 制作数据集
Padding填充操作,我们可以使用Pytroch中提供的pad_squence()方法。
pad_sequence(sequences, batch_first, padding_value)
sequences:一个由张量组成的列表或元组,这些张量将被填充到相同的长度。pad_sequence:这个函数接受一个张量列表作为输入,并返回一个新的张量,其中每个序列都被填充到相同的长度。较短的序列会在末尾添加特定的padding_value以匹配最长序列的长度。batch_first:一个布尔值,指示返回的张量中第一个维度应该是批量大小(batch_size)。如果设置为True,则输出张量的形状会是(batch_size, seq_length);如果为False,则形状为(seq_length, batch_size)。padding_value:这个参数用于指定填充的值。这个值将用于填充较短序列的末尾,以达到最长序列的长度
# 制作数据集
def make_data(sentences):
'''
将输入的句子通过构建的词向量得到对应的索引表
'''
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
# 将数据中的句子通过词表映射为索引
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] # [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
# extend用于将参数列表的元素添加到调用方法的列表末尾,这里是直接添加到空列表中
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
# 对句子进行pad操作
enc_inputs = pad_sequence([torch.tensor(l) for l in enc_inputs], batch_first=True, padding_value=0)
dec_inputs = pad_sequence([torch.tensor(l) for l in dec_inputs], batch_first=True, padding_value=0)
dec_outputs = pad_sequence([torch.tensor(l) for l in dec_outputs], batch_first=True, padding_value=0)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
2. 定义DataSet
# 方便训练的时候对数据进行读取
class MyDataSet(Data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
# 用于查看数据集中有多少个样本
def __len__(self):
return self.enc_inputs.shape[0]
# 用于取第index个样本的信息
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
五、训练和推理程序(main()):
整体流程:
- 构建样本:使用一个列表进行构建,其中
P表示原句子(翻译前的句子)的标识符,S表示解码端目标语言(翻译后的句子)的起始标识,E表示目标语言的结束标识符。- 进行词表的构建:使用一个字典分别构建原语言的词表与目标语言的词表。
- 进行词表的映射,即:将字典的键值互换,键是数字序列,值是各个词。
- 存储原语言的句子的最大长度和目标语言的句子的最大长度(后面
Padding的时候会使用)- 定义超参数。
- 制作数据集。
- 设置模型、损失函数、优化器。
- 训练:
- 分别得到编码端的输入(
enc_inputs)、解码端的输入(dec_inputs)、真实的目标语言(dec_outputs)。- 将
enc_inuputs和dec_inputs输入到Transformer模型中,得到transformer的输出、和三个注意力层的三个相似度矩阵。- 将
Transformer的输出与真实的目标语言传入到损失函数中,通过优化器进行反向传播。- 更新参数
- 测试:
- 首先从
dataset中得到原语言(翻译前的句子)。- 遍历
batch中的每一个原语言句子,作为enc_inputs,并且初始的时候将dec_inputs赋值为:S。- 将
enc_inputs和dec_inputs一同输入到Transformer模型中,通过贪婪策略,每次预测出一个词就将该词的在词表中的索引添加到dec_inputs中,直到遇到了句号.结束。- 接着将最终的
dec_inputs和enc_inputs一同输入到Transformer中,得到最终推理的结果。
if __name__ == '__main__':
# 构建样本
# S: Symbol that shows starting of decoding input 表示句子的起始符 解码端的输入
# E: Symbol that shows starting of decoding output 表示句子的结束符 解码端的真实标签
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps 表示填充字符padding,编码端的输入
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
'''================================================================================================================='''
# 词表的构建
# Padding Should be Zero 构建原语言的词表
src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4, 'cola': 5}
src_vocab_size = len(src_vocab) # 统计原词表的长度(字符个数)
# 目标语言词表的构建
tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'coke': 5, 'S': 6, 'E': 7, '.': 8}
idx2word = {i: w for i, w in enumerate(tgt_vocab)} # 词表的映射,即:键值互换
tgt_vocab_size = len(tgt_vocab) # 目标词表的长度(字符个数)
src_len = 5 # enc_input max sequence length 定义原语言的长度为5,这里表示为原语言中最大的句子长度
tgt_len = 6 # dec_input(=dec_output) max sequence length 定义目标语言的长度为6,这里表示为目标语言中最大的句子长度
'''================================================================================================================='''
# 定义超参数
# Transformer Parameters
d_model = 512 # Embedding Size 每一个句子转换为embedding时的大小
d_ff = 2048 # FeedForward dimension
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer 堆叠的个数
n_heads = 8 # number of heads in Multi-Head Attention 多头注意力层中的头的个数
'''================================================================================================================='''
# 制作数据集,这里是将输入的句子通过构建的词表将其转换为索引
enc_inputs, dec_inputs, dec_outputs = make_data(sentences) # enc_inputs, dec_inputs, dec_outputs都是对应句子的索引
# 对数据集进行封装,batch size = 2, shuffle = True
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), batch_size=2, shuffle=True)
# 设置模型,损失函数,优化器
model = Transformer().cuda()
criterion = nn.CrossEntropyLoss(ignore_index=0) # 交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)
'''================================================================================================================='''
# 进行训练
for epoch in range(1000):
for enc_inputs, dec_inputs, dec_outputs in loader:
enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda()
# outputs: [batch_size * tgt_len, tgt_vocab_size]
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, dec_outputs.view(-1))
if epoch % 3 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad() # 对梯度进行清零
loss.backward() # 进行反向传播
optimizer.step() # 更新参数
'''================================================================================================================='''
# Test 进行测试
enc_inputs, _, _ = next(iter(loader)) # 得到输入的句子
enc_inputs = enc_inputs.cuda()
for i in range(len(enc_inputs)): # 对每一个样本进行翻译(一个样本表示一个句子)
greedy_dec_input = greedy_decoder(model, enc_inputs[i].view(1, -1), start_symbol=tgt_vocab["S"]) # 得到预测翻译句子在词表的索引
predict, _, _, _ = model(enc_inputs[i].view(1, -1), greedy_dec_input) # 将编码端的输入与解码端的输入一起输入到模型中,得到解码端的输出
predict = predict.data.max(1, keepdim=True)[1] # 从预测输出中选择最大值作为预测结果。
print(enc_inputs[i], '->', [idx2word[n.item()] for n in predict.squeeze()])
六、通过贪婪策略来进行推理
贪婪策略主要用来求得最终解码端的输入数据。
# 通过输入要翻译的句子,每一次得到下一步预测的词,最后得到预测的句子,但是这一步的句子是带有符号的,即得到的是解码端的输入。
def greedy_decoder(model, enc_input, start_symbol): # 参数解释:Transformer模型,输入的句子,目标语言句子的起始位置
enc_outputs, enc_self_attns = model.encoder(enc_input) # 首先对输入的句子进行编码
dec_input = torch.zeros(1, 0).type_as(enc_input.data) # 设定一个空的向量,用于存放翻译之后的句子
terminal = False # 用于终止预测
next_symbol = start_symbol # 上一个预测的输出,初始的时候为 'S'
# 每次将上一次的总输出输入到decoder中,然后经过线性层得到最大词的概率,并且在下一次的循环中进行添加
while not terminal:
dec_input = torch.cat([dec_input.detach(), torch.tensor([[next_symbol]], dtype=enc_input.dtype).cuda()], -1) # dec_input.detach() 将返回一个从 dec_input 分离出来的新张量,该张量不再与当前计算图相关联, 将上一次的输出进行记录
dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs) # 进行解码
projected = model.projection(dec_outputs) # 经过线性层,将其映射到词表长度的一个向量
# 选取一个概率最大的进行输出,squeeze(0) 操作,它的目的是将 projected 的维度中的大小为 1 的维度去除,从而使得维度减少一个。这通常是为了适应后续操作的需要
# max(dim=-1, keepdim=False) 方法来计算 projected 张量在 dim=-1(即最后一个维度)上的最大值。返回一个元组,第一个张量是最大值,第二个张量是最大值所在的索引。
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
next_word = prob.data[-1] # 得到最大概率的词的索引
next_symbol = next_word # 将此次的输出进行记录
if next_symbol == tgt_vocab["."]: # 如果此次的输出与“.”的索引一致,则退出循环
terminal = True
# print(next_word)
return dec_input # 返回输出
肆、Transformer完整代码:
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
from torch.nn.utils.rnn import pad_sequence
# 制作数据集
def make_data(sentences):
'''
将输入的句子通过构建的词向量得到对应的索引表
'''
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
# 将数据中的句子通过词表映射为索引
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] # [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
# extend用于将参数列表的元素添加到调用方法的列表末尾,这里是直接添加到空列表中
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
# 对句子进行pad操作
enc_inputs = pad_sequence([torch.tensor(l) for l in enc_inputs], batch_first=True, padding_value=0)
dec_inputs = pad_sequence([torch.tensor(l) for l in dec_inputs], batch_first=True, padding_value=0)
dec_outputs = pad_sequence([torch.tensor(l) for l in dec_outputs], batch_first=True, padding_value=0)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
# 方便训练的时候对数据进行读取
class MyDataSet(Data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
# 用于查看数据集中有多少个样本
def __len__(self):
return self.enc_inputs.shape[0]
# 用于取第index个样本的信息
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
# 位置编码的实现
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout) # 以0.1的概率对神经元进行随机失活,提高模型的泛化能力,防止过拟合
# pe用于存储位置编码信息, 首先定义pe为一个0矩阵,大小为[5000, 512]
pe = torch.zeros(max_len, d_model)
# position用于表示单词在句子中的位置
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # torch.arange()用于创建一个具有一定范围的一维张量,unsqueeze用于在张量的维度 1 处添加一个新的维度
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1) # transpose()用于交换张量的维度顺序
self.register_buffer('pe', pe) # 注册缓冲区,其参数为缓冲区的名字与缓冲区存储的值,简单理解为这个参数不更新就可以
def forward(self, x):
x = x + self.pe[:x.size(0), :] # 将词向量与位置编码进行相加, 这里x为[5, 2, 512], pe为[5000, 1, 512],切片与x中最大的长度相同的位置编码,即[5, 2, 512] + [5, 1, 512]
return self.dropout(x)
# 由于句子的长度是不同的,取最大的句子的长度,其余的句子需要补全,get_attn_pad_mask函数就是实现该功能的, 即告诉机器那些词在后面的计算过程中是没有必要考虑进去的
def get_attn_pad_mask(seq_q, seq_k): # seq_q = seq_k = enc_input/dec_input, 在decoder中,seq_q是incoder
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], False is masked # eq(0) 表示将该张量中值等于 0 的元素变为 True,其余元素变为 False,表示那些部分是填充的
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k], 这里扩展为len_q, len_k 是因为,在计算得分的时候q与k进行相乘得到的结果需要
# 防止decoder在进行解码的时候掌握到未来单词的信息
def get_attn_subsequence_mask(seq):
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix # 将值为1的单位矩阵得到上三角部分(其余部分使用0进行填充)
subsequence_mask = torch.from_numpy(subsequence_mask).byte() # 将numpy创建为tensor类型
return subsequence_mask # [batch_size, tgt_len, tgt_len]
# 计算自注意力的得分
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, # 将mask的部分置为负无穷大
-1e9) # Fills elements of self tensor with value where mask is True. 当值为负无穷的时候softmax的值才会是0
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v] 执行矩阵的乘法
return context, attn # 返回的是一个相似度的结果与一个相似度矩阵
# 多头注意力
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False) # d_model 表示每个字符的编码512, d_k = d_v = 64, => 64 * 8
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
residual, batch_size = input_Q, input_Q.size(0) # input_Q = input_K = input_V (and shape = (2, 5, 512))
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # Q: [batch_size, n_heads, len_q, d_k] [2, 8, 5, 64]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,
2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1,
1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask) # 计算注意力的得分,这一行表示实例化类,并且传入参数(Q, K, V, attn_mask), 得到一个最终的得分和一个相似度矩阵
context = context.transpose(1, 2).reshape(batch_size, -1,
n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v] 将多个头进行合并
output = self.fc(context) # [batch_size, len_q, d_model] # 最终的结果输入到一个线性层进行输出
return nn.LayerNorm(d_model).cuda()(output + residual), attn # 返回的是一个经过线性层、归一化层的得分(传入output + residual是因为残差网络),与一个相似矩阵
# 位置感知的前馈神经网络
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).cuda()(output + residual) # [batch_size, seq_len, d_model]
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention() # 多头注意力层
self.pos_ffn = PoswiseFeedForwardNet() # 位置感知的前馈神经网络
def forward(self, enc_inputs, enc_self_attn_mask):
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, # 将与位置编码相加后的词向量与mask输入到多头注意力层中
enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn # 返回的是一个编码层的输出与相似度矩阵
# 解码器层
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
# 注意:两次的注意力机制中,需要的两次mask是不同的,第一次是解码端自己的padding操作与未来词掩盖操作的和,第二次是编码端与解码端的padding(目的是屏蔽编码端的padding)
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask) # masked多头注意力层编码
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask) # 多头注意力层编码
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn
# 编码器
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) # 词向量层,去定义一个词表,大小是src_vocab_size(原词表长度:6个) * d_model(512),shape=(6, 512),相当于是直接对词表中的每一个词进行了编码,每个编码的长度为512
self.pos_emb = PositionalEncoding(d_model) # 位置编码层
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
'''
enc_inputs: [batch_size, src_len]
'''
enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model] # 进行编码,通过数字索引转化为对应的向量
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model] # 进行位置编码
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len] [2, 5, 5] 对长度不够的句子进行补全,进行pad填充
enc_self_attns = []
for layer in self.layers: # 对每一个layer进行循环
# enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) # 对每一个layer输入加入位置编码的词向量以及需要掩盖的部分
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns # 返回的是一个编码器输出的结果和N个EncoderLayer(通过列表的形式)
# 解码器
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) # 编码
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) # 6个layer
def forward(self, dec_inputs, enc_inputs, enc_outputs):
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).cuda() # [batch_size, tgt_len, d_model]
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() # [batch_size, tgt_len, tgt_len] # 对decoder的输入进行一次padding操作
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(
dec_inputs).cuda() # [batch_size, tgt_len, tgt_len] # 对未来单词进行mask,使用一个上三角矩阵(值为1)
# 两个矩阵进行相加,大于0的部分为1,不大于0的部分为0,为1的在之后就会被fill到无穷小
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask),
0).cuda() # [batch_size, tgt_len, tgt_len]
# 对decoder的输入与encoder的输入进行一次padding,原因是因为编码端的输出结果中存在padding的标志,需要对这些标记进行屏蔽操作
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers: # 对每一层(6个层)进行遍历
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask,
dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn) # 添加masked的多头注意力层的相似矩阵
dec_enc_attns.append(dec_enc_attn) # 添加多头注意力层的相似矩阵
return dec_outputs, dec_self_attns, dec_enc_attns # 返回encoder的输出、masked的多头注意力层的相似矩阵列表、多头注意力层的相似矩阵列表
# Transformer模型定义
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder().cuda() # 编码器
self.decoder = Decoder().cuda() # 解码器
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).cuda() # 线性全连接层,输出层
# 接收两个参数,编码端的输入与解码端的输入
def forward(self, enc_inputs, dec_inputs):
enc_outputs, enc_self_attns = self.encoder(enc_inputs) # 将编码端的输入到编码器中
# dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs,
enc_outputs) # 解码端的输入:解码端的输入、编码端的输入、编码端输出
dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, tgt_len, tgt_vocab_size] # 映射词表操作
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns # 返回的是一个总的输出和encoder的一个相似矩阵列表、decoder的两个相似矩阵列表
# 通过输入要翻译的句子,每一次得到下一步预测的词,最后得到预测的句子,但是这一步的句子是带有符号的,即得到的是解码端的输入。
def greedy_decoder(model, enc_input, start_symbol): # 参数解释:模型, 输入的句子, 句子的起始位置
enc_outputs, enc_self_attns = model.encoder(enc_input) # 首先对输入的句子进行编码
dec_input = torch.zeros(1, 0).type_as(enc_input.data) # 设定一个空的向量,用于存放翻译之后的句子
terminal = False # 用于终止预测
next_symbol = start_symbol # 上一个预测的输出,初始的时候为 'S'
# 每次将上一次的总输出输入到decoder中,然后经过线性层得到最大词的概率,并且在下一次的循环中进行添加
while not terminal:
dec_input = torch.cat([dec_input.detach(), torch.tensor([[next_symbol]], dtype=enc_input.dtype).cuda()], -1) # dec_input.detach() 将返回一个从 dec_input 分离出来的新张量,该张量不再与当前计算图相关联, 将上一次的输出进行记录
dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs) # 进行解码
projected = model.projection(dec_outputs) # 经过线性层,将其映射到词表长度的一个向量
# 选取一个概率最大的进行输出,squeeze(0) 操作,它的目的是将 projected 的维度中的大小为 1 的维度去除,从而使得维度减少一个。这通常是为了适应后续操作的需要
# max(dim=-1, keepdim=False) 方法来计算 projected 张量在 dim=-1(即最后一个维度)上的最大值。返回一个元组,第一个张量是最大值,第二个张量是最大值所在的索引。
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
next_word = prob.data[-1] # 得到最大概率的词的索引
next_symbol = next_word # 将此次的输出进行记录
if next_symbol == tgt_vocab["."]: # 如果此次的输出与“.”的索引一致,则退出循环
terminal = True
# print(next_word)
return dec_input # 返回输出
if __name__ == '__main__':
# 构建样本
# S: Symbol that shows starting of decoding input 表示句子的起始符 解码端的输入
# E: Symbol that shows starting of decoding output 表示句子的结束符 解码端的真实标签
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps 表示填充字符padding,编码端的输入
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
# 词表的构建
# Padding Should be Zero 构建原语言的词表
src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4, 'cola': 5}
src_vocab_size = len(src_vocab) # 统计原词表的长度(字符个数)
# 目标语言词表的构建
tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'coke': 5, 'S': 6, 'E': 7, '.': 8}
idx2word = {i: w for i, w in enumerate(tgt_vocab)} # 词表的映射,即:键值互换
tgt_vocab_size = len(tgt_vocab) # 目标词表的长度(字符个数)
src_len = 5 # enc_input max sequence length 定义原语言的长度为5,这里表示为原语言中最大的句子长度
tgt_len = 6 # dec_input(=dec_output) max sequence length 定义目标语言的长度为6,这里表示为目标语言中最大的句子长度
# Transformer Parameters 定义超参数
d_model = 512 # Embedding Size 每一个句子转换为embedding时的大小
d_ff = 2048 # FeedForward dimension
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer 堆叠的个数
n_heads = 8 # number of heads in Multi-Head Attention 多头注意力层中的头的个数
# 制作数据集,这里是将输入的句子通过构建的词表将其转换为索引
enc_inputs, dec_inputs, dec_outputs = make_data(sentences) # enc_inputs, dec_inputs, dec_outputs都是对应句子的索引
# 对数据集进行封装,2表示batch size True表示shuffle
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), batch_size=2, shuffle=True)
# 设置模型,损失函数,优化器
model = Transformer().cuda()
criterion = nn.CrossEntropyLoss(ignore_index=0) # 交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)
# 进行训练
for epoch in range(30):
for enc_inputs, dec_inputs, dec_outputs in loader:
enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda()
# outputs: [batch_size * tgt_len, tgt_vocab_size]
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, dec_outputs.view(-1))
if epoch % 3 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad() # 对梯度进行清零
loss.backward() # 进行反向传播
optimizer.step() # 更新参数
# Test 进行测试
enc_inputs, _, _ = next(iter(loader)) # 得到输入的句子
enc_inputs = enc_inputs.cuda()
print('-' * 50)
for i in range(len(enc_inputs)): # 对每一个样本进行翻译(一个样本表示一个句子)
greedy_dec_input = greedy_decoder(model, enc_inputs[i].view(1, -1), start_symbol=tgt_vocab["S"]) # 得到预测翻译句子在词表的索引
predict, _, _, _ = model(enc_inputs[i].view(1, -1), greedy_dec_input) # 将编码端的输入与解码端的输入一起输入到模型中,得到解码端的输出
predict = predict.data.max(1, keepdim=True)[1] # 从预测输出中选择最大值作为预测结果。
print(enc_inputs[i], '->', [idx2word[n.item()] for n in predict.squeeze()])















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









