






目录
阅读文献《Simple Cues Lead to a Strong Multi-Object Tracker》的总结
1、介绍
MOT旨在识别并追踪视频中所有运动物体的轨迹。该领域长期以来一直通过检测跟踪,它将跟踪分为两个步骤:(i)逐帧对象检测,(ii)数据关联以链接检测和形成轨迹。逐帧匹配通常由外观、再识别 (reID) 特征或运动线索等线索驱动。而如何高效并准确地利用线索则是重中之重,这里将提出一个简单的基于匈牙利算法的跟踪器,该跟踪器具有外观和运动线索,在多个基准上占主导地位,甚至不需要任何跟踪数据进行训练(reID)
匈牙利算法:本质是将前一帧与当前帧中的识别信息进行关联计算距离,知乎上的一篇帖子很贴切地进行了解释 【小白学习笔记】(一)目标跟踪-匈牙利匹配 - 知乎 (zhihu.com)
reID:以行人为例,由于人脸识别受多种因素影响不再适用,一个区域有多个摄像头拍摄视频序列,reID要求对一个摄像头下感兴趣的行人,检索到该行人在其他摄像头下出现的所有图片,类似于《碟中谍》根据一个人人脸在多个摄像头间进行检索并定位(既然这个跟踪器是以reID进行改进,不应该使用reID的数据集进行检验更有说服力吗)
小白入门系列——ReID(一):什么是ReID?如何做ReID?ReID数据集?ReID评测指标? - 知乎 (zhihu.com)
首先将最先进的再识别 (reID) 网络应用于MOT的外观匹配不充足的真实场景。得到了 reID 性能不一定转化为 MOT 性能的结论。问题在于:reID模型需要考虑不同时间周期内的不同变化,在物体的附近帧中,外观变化最小,在较长的时间间隔会发生更严重的变化,reID往往并不一致。
针对该问题提出动态域适应,以及活动和非活动轨道的不同策略来解决,此外,还在能见度、遮挡时间和相机运动的不同条件下进行分析,确定reID不足以满足,于是使用加权和将reID与一个简单线性运动模型相结合,这样面对不同的数据集每个线索都可以被赋予更多权重,在这期间从未在任何跟踪数据集上训练(意思是要训练两次吗,这句话感觉重复了很多次)
贡献:1)提供关键设计选择,显著提高reID在MOT中的性能;2)分析说明外观不足以支撑,提出一个跟踪器GHOST将外观和运动相结合,应用于四个数据集中进行评估
2、相关工作
逐检测跟踪TbD(即上文所提到的DBT)是MOT工作中的经典案例,以行人为例,首先使用对象检测器检测行人,然后进行跨帧关联检测,即利用运动、位置、外观等线索形成与特定身份相对应的轨迹,该关联既可以逐帧求解在线应用程序,也可以按顺序以跟踪方式逐帧求解。
Graph-Based方法:遵循TbD案例执行数据关联的一种常见形式是将每个检测视为图中的节点,随后将节点相连接形成轨迹,GHOST证明不必使用结合了强大但复杂的线索的复杂图标模型
运动关联:不同于上一个方法,许多TbD方法直接使用来自检测和现有轨迹的运动和位置线索来执行逐帧关联。这些方法利用的两个相邻帧的物体的位移很小,在短期关联中发挥出色,例如卡尔曼滤波器等,它们按照注意力跟踪方式跟踪。不同于这些方法,GHOST证明一个简单的线性运动模型在多数情况下足以对短期关联进行建模,例如在移动摄像机、遮挡场景或需要非平凡长期关联场景中
外观关联:为了应用于长期关联场景,许多方法使用额外的基于外观的再识别网络编码外观线索来在遮挡后再识别,为了增强MOT性能,这种使用外观而不是运动线索的方法需要使用的关联方案具有复杂的步骤,也因此很难得出正确的结论。相比GHOST不依赖复杂的过程,仅仅在一个简单但强大的TbD跟踪器结合轻量级运动和清晰外观线索,只需要很少的训练数据
人类再识别和领域适应:根据研究,在域外样本上进行评估,通过其他数据集训练得到的reID模型往往会显著降低性能,在应用中可以使用跨数据集评估方式将模型在给定目标中训练。受这些方法启发,GHOST使用简单的动态域适应方法增强了外观模型,更加适合MOT。
3、方法
3.1、通过跟踪器进行的简单追踪
在跟踪中,每一个轨迹在每一个时间t使用线性运动模型产生对应的预测位置,检测被分配给轨迹,若未添加则定义为非活动,否则保持活动,使用内存库来保持非活动轨迹,将检测与实况轨迹进行匹配
通过匈牙利算法利用二部匹配在连续帧中对检测进行关联,该分配由成本矩阵驱动,即将新检测与前一帧已获得的轨迹进行对比。GHOST使用外观特征、运动线索,将两者进行简单加权来填充成本矩阵,又使用匹配阈值在匹配后过滤检测轨迹对
3.2、外观模型
外观模型基于ResNet50改进,最后有一个额外的全连接层进行下采样,并在一个个公共人员再识别数据集上进行训练,由于基本reID模型在MOT任务中性能表现不佳,提出两种方法使外观模型效果更好:(i)以不同方式处理活动轨道和非活动轨道;(ii)添加动态区域适应,为此分析了MOT序列中检测和跟踪的距离
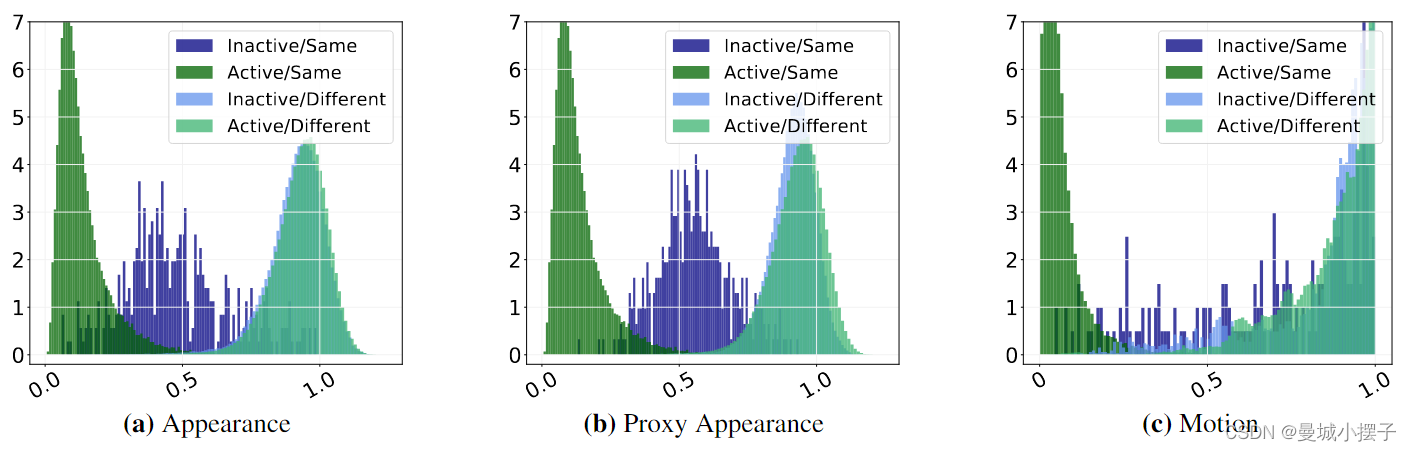
外观距离直方图:在图(a)中,利用不同距离度量分析了MOT17验证集上新检测和活动或非活动轨迹之间的距离直方图,在深色和浅色中分别展示了轨道和相同身份(正匹配)和不同身份(负匹配)的检测的距离
活动和非活动轨道的不同处理:由于遮挡或姿态的变化,相同身份的嵌入即使在连续两个帧之间也会产生极大距离,图(a)中可视化了新检测和最后一个检测(活动或非活动轨道)间的距离,由于两个深色直方图差异很大,表明有必要对主动或非主动轨迹进行不同处理,同时,可以观察到非活动轨道正匹配和负匹配间的重叠,证明了遮挡后匹配的固有困难
对于活动轨道,利用在t-1帧分配给轨道j的检测外观特征来计算t帧检测i的距离,
对于非活动轨道,计算非活动轨迹k中所有Nk检测的外观特征向量与新的检测i间的距离,然后利用这些距离的平均值作为代理距离,即

得到距离直方图如图(b),该代理距离对检测和非活动轨迹间的真实潜在距离进行更有意义的估计,因此与使用代理距离的非活动轨道的单个特征向量(图(a))相比,可以得到更好的分离直方图(图(b))
因此活动轨道和非活动轨道在二部分配过程中需要不同处理,阈值通常确定应该允许匹配的成本。如图(b),不同阈值将活动轨道和非活动轨道的距离直方图划分为相同(深色)和不同(浅色)身份的检测。相比级联匹配,GHOST的赋值避免了每帧多次运用二部匹配
动态域适应:如第2节所述,reID领域将域适应(DA)技术应用于源数据集统计数据可能与目标数据集统计数据不匹配。对于MOT,每个序列遵循不同的统计数据并代表一个新的目标域,因此使用动态DA防止应用于不同MOT序列中reID模型性能下降
一些工作引入利用DA思想的方法,将归一化层适应InstanceBatch, Meta Batch, 或 Camera-Batch Normalization 层来实现数据集泛化,不同于这些,GHOST利用当前批次的特征的均值和方差,对应架构的BN层中一个帧的检测:
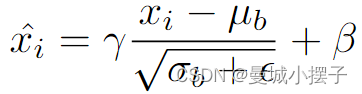
其中 xi 为样本 i 的特征,μb 和 σb 是当前批次的均值和方差, 是确定数值稳定性的小值 ,并且在训练期间学习γ 和 β,不需要复杂的训练或测试,但合理逼近序列的统计数据,并且一个序列所有图像都具有高度相似的底层分布,使跟踪序列间的距离直方图更相似,反过来又促使定义适合所有序列的阈值分离所有直方图。
将这些应用于外观模型,使对遮挡更适应,更适合不同序列
4、实验
4.1、实验细节
首先使用Market-1501数据集使用标签平滑交叉熵损失训练模型,利用RAdam优化器,在最后分类层添加了一个·BN层,利用类平衡采样,训练期间应用随机裁剪和水平翻转,评估后远低于当前最先进性能。
对于跟踪,将i和j间的外观距离定义为外观嵌入的余弦距离
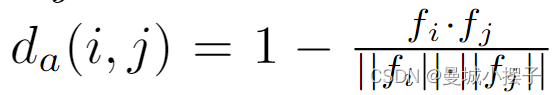
对于运动距离,使用两个边界框之间的交集/并集(IoU)
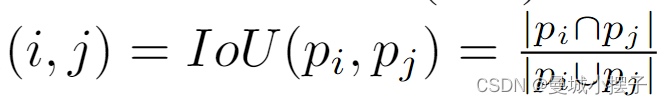
4.2、数据和评估
对于MOT17 和 MOT20 将在公共和私有检测设置中进行评估。BDD和DanceTrack将使用YOLOX-X生成的私有检测评估
MOT17:沿时间维度拆分MOT17训练序列,使用每个序列的前半部分作为训练集,后半部分作为评估集
MOT20:MOT20由四个训练集和测试集组成,每帧有超过100名行人。
DanceTrack:包含具有高度相似外观、不同运动和极端发音的舞蹈人类视频
BDD:由1400、200和400个训练、验证和测试序列组成,其中8个不同的类具有不同的不同类的频率
指标: HOTA 指标 、IDF1 分数 和 MOTA 是最常见的。MOTA 指标主要由对象覆盖率决定,IDF1 主要关注身份保存,但 HOTA 平衡了两者。
4.3、外观模型分析
研究外观模型的设计选择对跟踪性能的影响,控制不使用运动
活动轨道和非活动轨道的不同处理:通过对指标的评估发现,使用不同的活动和非活动轨道阈值将跟踪性能提高,此外利用代理距离计算而不是非活动轨道的最后一个检测进一步增强
动态域适应:通过考虑序列之间的差异,得到了在所有序列上的合适阈值。将动态域适应和各种不同的其他域适应方法比较,性能均有提升,同样适用于使用 IBN 而不是 BN 层,它结合了 Instance 和 Batch Normalization 层的优点
4.4、运动和外观强度
分析了3.2节外观线索的性能,找到它们相对于给定跟踪条件的优势,即检测的可见性级别、轨道的遮挡时间和相机运动等,还分析了下面介绍的线性运动模型的互补性能。
线性运动模型:将短期运动,如两个连续帧中,用线性模型近似,假设速度恒定。给定轨道j的检测,计算最后k个连续检测之间的平均速度vj,并预测轨道的当前位置
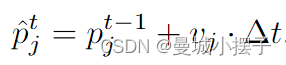
通过计算新检测和预测位置之间的IoU,还可视化了相应的距离直方图,表明相同身份和不同身份的检测和跟踪之间的距离直方图 很好地分离了运动轨迹
分析设置:研究MOT17验证集上的正确关联(RCA)的比率,定义为:

其中TP-Ass和FP-ASS分别表示真阳性和假阳性关联。对来自多个跟踪器的预处理私有检测集(4.5节)的RCA进行平均以获得更少的噪声统计数据
观察:通过可视化检测和轨迹之间的RCA,以及静态序列和动态序列相对于遮挡时间和可见性的运动和外观的性能,高度可见的边界框外观在长期和短期关联方面的表现优于运动,受相机运动的影响。在静态序列中,线性运动模型在长期关联方面比外观表现更好。
结论:可见性、遮挡时间、相机运动三个因素相互作用主要影响运动和外观的性能,同时外观和运动也相对于这些因素相互补充,因此创建了跟踪器结合了外观和简单的线性运动模型。
4.5、简单的线索产生一个强大的跟踪器
将外观和运动结合为一个基于匈牙利算法的在线跟踪器,同4.4节相同,将GHOST应用于其他跟踪器,评价IDF1和HOTA等关联性能
外观:同原始跟踪器相比,在平均遮挡水平较低的检测集中性能显著提升,但在高遮挡、具有外观模糊的检测集中证明它不适合
运动:仅应用没有外观的简单线性运动模型同原始跟踪器相比总是有所提升或相当,利用卡尔曼滤波器而不是简单线性运动模型不会显著影响性能(说明线性运动模型很顶),移动摄像机会从较低的运动权重中获益,同样适用于极端情况,如DanceTrack数据集
结合:将外观、线性运动或卡尔曼滤波器相结合,由于移动摄像机序列会从较低运动权重中获益,遮挡水平较高的检测从较高的运动权重中获益,因此设定运动权重为0.5,实验发现,无论外观模型和线性运动模型还是卡尔曼滤波器结合,都比单独外观模型性能更强
4.6、和现有技术的比较
将GHOST与当前先进方法进行比较
MOT17:公共检测方面,GHOST进行了改进,但在MOTA中并没有提高(因为它主要依赖检测性能)。在私有检测中,在HOTA和IDF1中与ByteTrack相当
MOT20:GHOST将基于MOT20的最新公共检测在IDF1和HOTA方面显著提高,表明在强外观线索和线性运动的结合适应更高遮挡的环境。MOT的私有检测方面在,HOTA和IDF1都显著提高,GHOST在私有检测中充分利用额外的可用边界框,同私有设置相比身份验证显著增加
DanceTrack:尽管reID和线性运动模型不适合DanceTrack,但GHOST却优于所有方法(呼应了前文“适用于极端情况”),被称为通用的基于Transformer的GTR方法和MOTR方法在DanceTrack上的性能却无法从MOT17和MOT20上转移,在HOTA、IDF1和MOTA上均显著提高
5、结论
本文展示了原始TbD跟踪器在不同数据集上的应用,对于简单的匈牙利跟踪器GHOST,引入了一个外观模型,该模型以不同方式处理活动和非活动轨迹,通过动态域适应来适应测试序列。对外观和简单线性运动模型基于可见性、遮挡时间、相机运动三个因素进行分析,得出需要使用加权和的结论,即根据数据集中情况,为任一因素赋予更多权重。















 1850
1850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









