






“
这个任务就是深度学习最擅长的。颜色、亮度体现在图像数据第3维,以数值来体现,CNN可以完美捕捉到这种特征。人所担心的“体型相似”并不是神经网络怕的,因为通过损失反向传播得来的权重自然而然会把“颜色”这种特征组合的权重调高,而其他特征不影响。所以只要数据够多、标签标对了,CNN几乎可以完美处理。
作者:番茄射手
链接:https://www.zhihu.com/question/391774138/answer/1191919036
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
”
2023/7/31
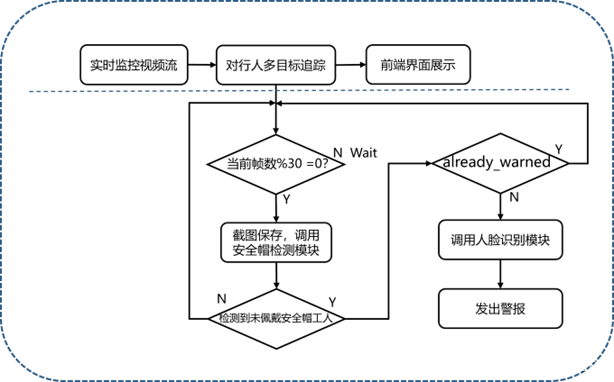
开启论文的最后一章 “针对未佩戴安全帽人员目标追踪及身份识别的方法研究”
导师让我最后一章也提一下人脸
用reid
初步想法是 改进一下特征提取网络 IOU
报警策略: 没办法做到谭要求的 发现他没带 然后去追踪他 只能说更精准的追没带帽子的人 对于带的人不care
突然想到 之前很多MOT可是用到了Reid
deepsort中的reid 去除最后分类用的全连接层,即只利用该网络做特征提取不进行后续分类
1.有一个问题 匈牙利算法和IOU匹配什么关系
深入浅出——零基础一文读懂DeepSORT(原理篇)_YouOnlyLookOnemiotms的博客-CSDN博客
炮哥:目标追踪---deepsort原理讲解_炮哥带你学的博客-CSDN博客
IOU匹配的结果计算其代价矩阵(cost matrix ,代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果
每次只要Tracks匹配上都会保存Detections其的外观特征和运动信息,默认保存前100帧,利用外观特征和运动信息和Detections进行级联匹配
级联匹配: (利用之前保存的外观特征(之前reid提取的吗?),基于之前KF预测的运动信息 和当前帧的Detections 的外观特征(reid) 和当前帧的 运动信息) 匹配
应该是only reid , 运动信息的权重为0 有空研究下Deep sort算法论文解读_deepsort论文解读_mini猿要成长QAQ的博客-CSDN博客)
而与马氏距离做融合机制会有一个好处就是它会限制reid的匹配距离
对于bytetrack 最好的也是第一次匹配 only reid 第二次only 运动 ,这一点两个算法是一样的
下面开始看如下方法的Reid

FairMoT:
论文阅读-FairMOT:《A Simple Baseline for Multi-Object Tracking》_高斯核函数是哪篇论文提出的_DJames23的博客-CSDN博客
两阶段:将目标检测和re-ID作为两个分开的任务。首先使用基于CNN的目标检测器比如Faster R-CNN[8]和YOLOv3[11]来定位输入图片感兴趣的所有物体。然后在另一个步骤中,根据检测框来裁剪图片并把它们喂到一个身份嵌入网络来提取re-ID特征,用于随着时间推移来链接检测框。链接步骤通常遵循标准的做法,首先根据bbox的re-ID特征和交并比(IoU)计算成本矩阵,然后使用卡尔曼滤波[34]和匈牙利算法[35]来完成链接任务。
这两个任务需要单独完成而没有共享 所以 慢 浪费计算资源
一阶段:
核心思想是在单个网络中同时完成目标检测和身份嵌入(re-ID特征),以通过共享大部分计算来减少推理时间。例如,Track-RCNN [15]在Mask-RCNN [9]的顶部添加了一个Re-ID头,并为每个proposal回归了边界框和一个re-ID特征。 **JDE [14]是在YOLOv3 [11]**上构建的,该框架可实现接近视频速率的推断。
但是,一阶段方法的跟踪精度通常低于两阶段方法的跟踪精度。

Bot-Sort(以ByteTrack为基础)、Strong、GIAO
【文献阅读笔记】BoT-SORT: Robust Associations Multi-Pedestrian Tracking_朝-的博客-CSDN博客
BoT-SORT与Strong-SORT论文对比及思考总结_botsort 和strongsort哪个更新_mumuxi_c的博客-CSDN博客
GIAOTracker in VisDrone 2021_Fwenxuan的博客-CSDN博客

EMA Bank
起源于GIAO
时间序列预测基本方法--移动平均(SMA、EMA、WMA) - 知乎 (zhihu.com)
小组会8.8ppt
第一页:reid是没有全连接的特征提取网络
deepsort、bytetrack中是如何权衡运动和外观的
第二页:
FairMot中的二阶段和一阶段
所以现在大家用的都是几阶段? (还是两阶段)
第三页:
deepsort中的gallery和 新的EMA Bank
每次更新特征都会将特征放入其中,按照队列形式,此处会出现一个问题,当目标在一个位置长时间不动的时候,特征池里面的特征可能都几乎为相同的特征,而当快速变化时,由于特征池来不及更新,会导致自身特征匹配不上导致id变换,轨迹丢失。而EMA方式可能长时间的不动也仍然存在之前特征的影子,并不是单一的姿态特征。
原文链接:https://blog.csdn.net/ganbelieve/article/details/126664525
第四页
iou和reid结合的方法 Bot-Sort的
高分 iou+reid 低分只有IOU (没有reid 也没有iou
距离度量对短期的预测和匹配效果很好,但对于长时间的遮挡的情况,使用外观特征的度量比较有效。
如何融合我第四章的工作
第四章KF不可信 不用KF 但是REID还要继续更新
2023/9/23
之前8.8大组会的研究没有保存
大论文框架

下周一要去找谭argue 以及周二讲
第二章没什么问题
三四章的区别与联系:
1. 方法上: 第三章是Reid 2. 第四章是KF 轨迹插值
2. 关注的特征: 第三章是外观 第四章是运动信息
3. 逻辑: 第三章是针对未佩戴的人员讲的 第四章是针对所有人 或者说是为了更好的追未戴帽子的
关于reid的创新点&论文
1.EMA Bank
详情看上面 这里只有创新点
1.1DEEP-oc sort
消融实验的baseline是ocsort
deepocsort源码详解_Mort_al的博客-CSDN博客
DeepSORT再升级 | Deep OC-SORT引入目标外观信息,大幅领先SOTA - 热点 - 科研解读 - AMiner
1.1.1DA 动态外观
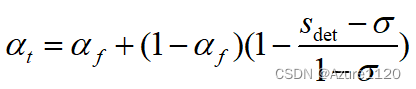
1.1.2AW 自适应加权
自适应的外观特征比重
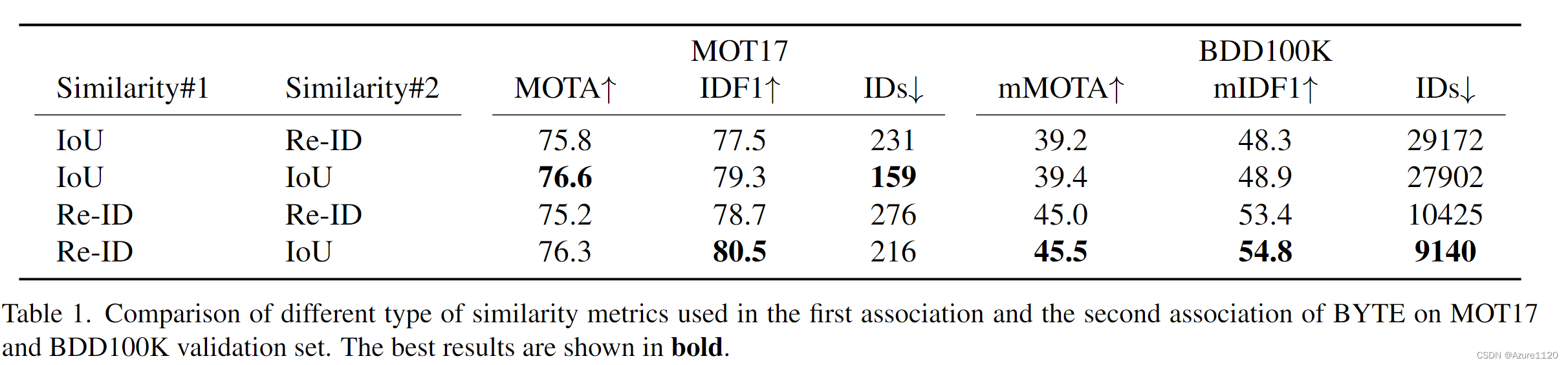
2. Reid & IOU
deepsort的做法是 马氏距离做保险 几乎就是reid 加 第二次的IOU
bytetrack(reid版) 第一次纯reid 第二次纯iou
2.1 这是BOT-SORT提出来的
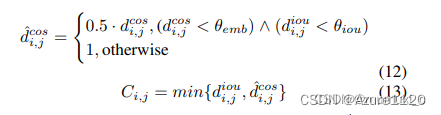
2.2 Deep -oc sort中的AW
在本周ppt提到了 但是没有实验
| 方法 | 描述 |
|---|---|
| DeepSort | aIou+(1-a)cos |
| ByteTrack | one:cos ; two:iou |
| BOT-SORT | one:min{iou,0.5cos(满足阈值)} ; two:iou |
| AW | deep oc sort的 计算差异度 |
| ACM | bytetrack改进混合运动特征+自适应计算混淆矩阵 |
3. 藏辉
CVPR2023 多目标跟踪(MOT)汇总_藏晖的博客-CSDN博客
3.1 cvpr2023 的二《MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking》
对于密集的人群,我们设计了一个新的交互模块,从短期轨迹中学习交互感知运动,它可以估计每个目标的复杂运动。对于极端遮挡,我们建立了一个新的重寻模块(和reid无关),从目标的历史轨迹中学习可靠的长期运动,它可以将中断的轨迹与相应的检测联系起来。
基于ByteTrack的改进,用网络来强化其运动预测
3.2 CVPR2023的九 《Simple Cues Lead to a Strong Multi-Object Tracker》
将我们的外观特征与一个简单的运动模型相结合,可以得到强大的跟踪结果。
文中要解的问题是在目标丢失之后,appearance特征的区分性并不强,影响跟踪性能。
因此,本文提出了两种设计选择,以使外观模型更强: (i)以不同的方式处理active和inactive的轨迹,简单来说就是对active轨迹计算了前后两帧之间的距离,对于inactive轨迹计算了当前帧与轨迹消失前所有帧的距离,并求了平均;(ii)我们添加了动态的域自适应,即一种归一化方式让ReID特征可以更自适应不同的场景,如遮挡等(与ECCV2022一篇paper思路相似 就是下面的3.3)
ECCV2022 多目标跟踪(MOT)汇总_mot跟踪_藏晖的博客-CSDN博客
3.3 ECCV的三 《Robust Multi-Object Tracking by Marginal Inference》
本文作者提出了一种归一化的方式,能保证不同的视频序列可以用相同的REID阈值,以提高算法性能。
CVPR2022 多目标跟踪(MOT)汇总_20202 多目标跟踪_藏晖的博客-CSDN博客
3.4 cvpr2022的一 《DanceTrack: Multi-Object Tracking in Uniform Appearance and Diverse Motion》 一篇数据集文章
我们实际中通常跟踪的目标不具有相同的外观表征,同时其运动姿态也会更多样。为此,本文作者提出了一个“DanceTrack”的数据集,希望其能提供一个更好的平台来开发更多的MOT算法,更少地依赖于视觉辨别,更多地依赖于运动分析。
DanceTrack: 相似外观和复杂运动的多目标追踪数据集 (CVPR2022) - 知乎 (zhihu.com)
为了实现这个目标,我们收集了100段视频,内容包括集体舞蹈、功夫、体操等,他们共同的特点是:(1)目标人物穿着相似甚至一致;(2)目标之间有大量的遮挡和位置交错;(3)目标的运动模式非常复杂多样,呈现明显的非线性,并且时常伴随多样的肢体动作。
3.5 它的reid系列
4.赵炎给的两篇还剩一篇没有看过
bytetrack改进混合运动特征+自适应计算混淆矩阵
4.1Hybrid Motion Feature HMF
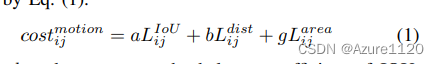
4.2ACM Adaptive Calculation Method (ACM)
感觉不如3中的
两个等式对应——对应两个阶段
IoU-constrained appearance cost matrix
use the IoU as a constraint to prevent the similar-looking but too distant objects

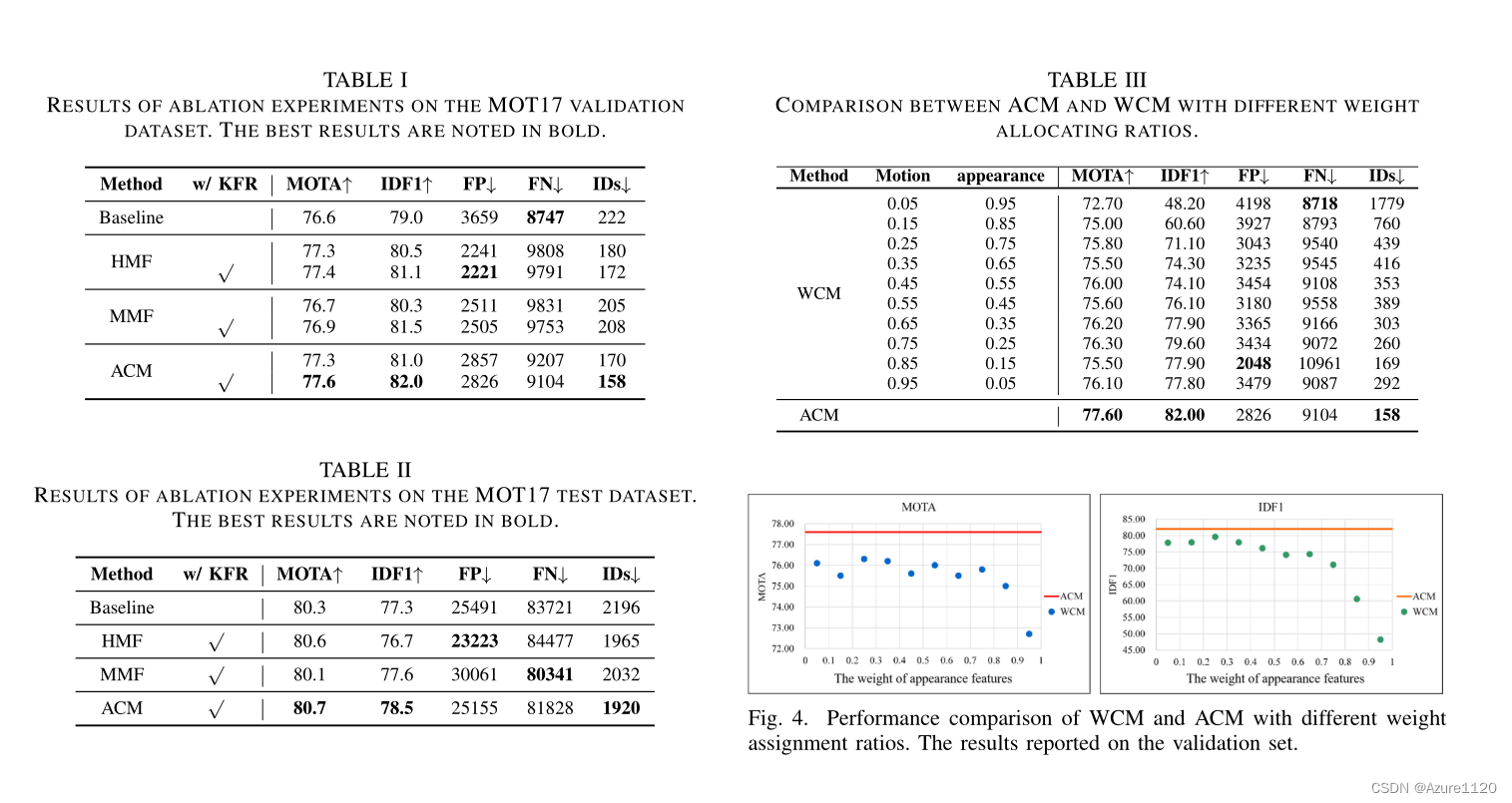
2023/10/14
有一个很重要的问题 why需要追踪
Deep -oc sort中的AW 或者4中的ACM
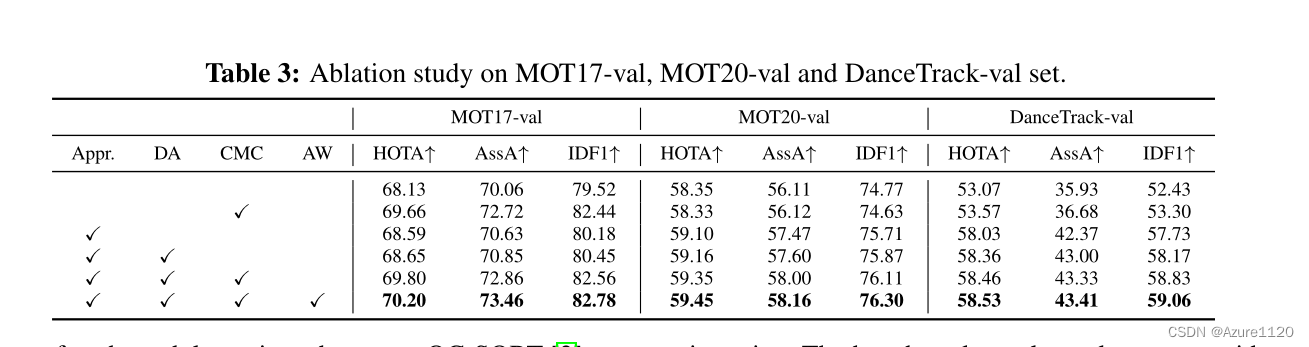
1. 这次组会需要给帅哥画个流程图 第三四章的关联
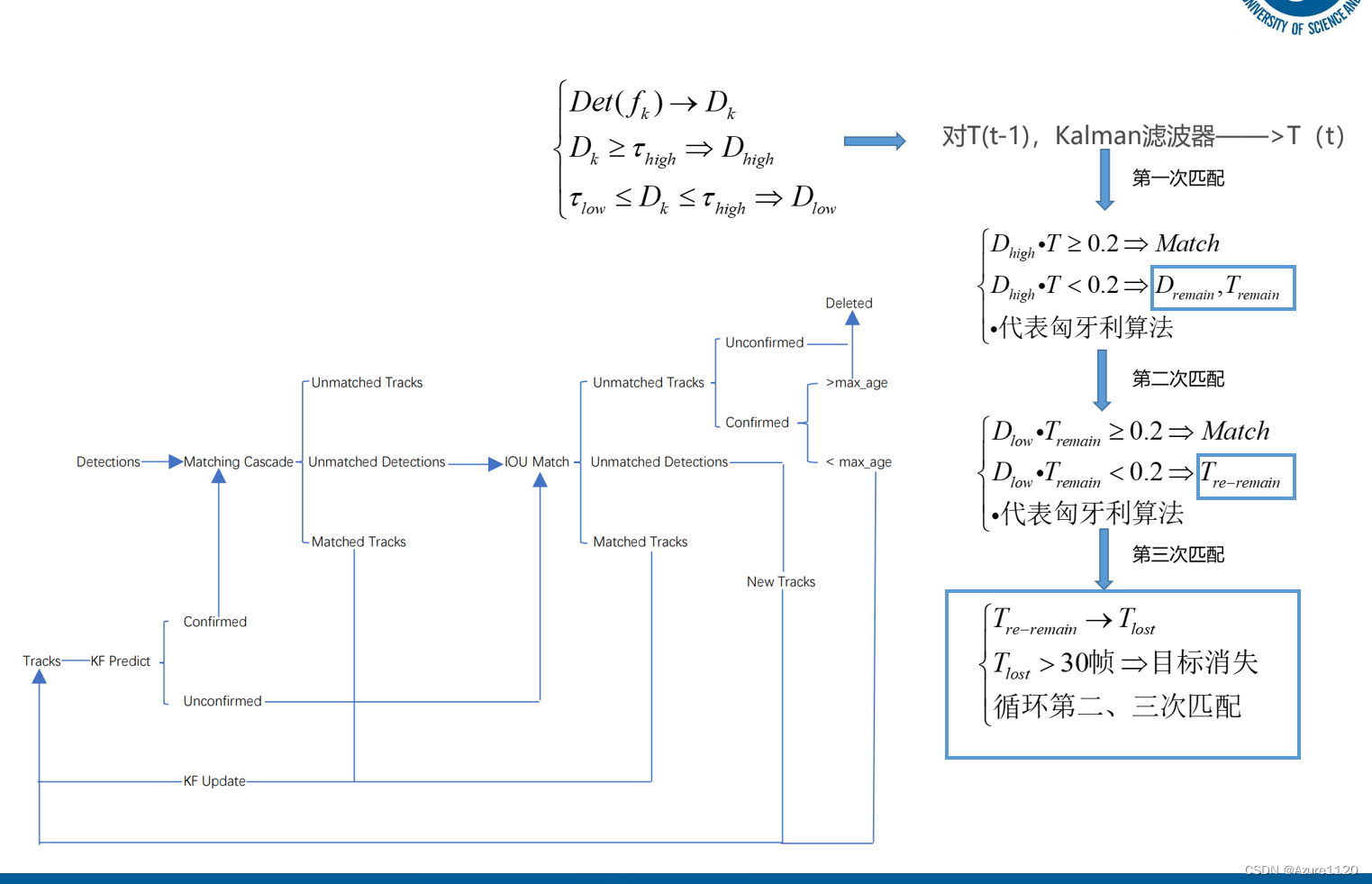
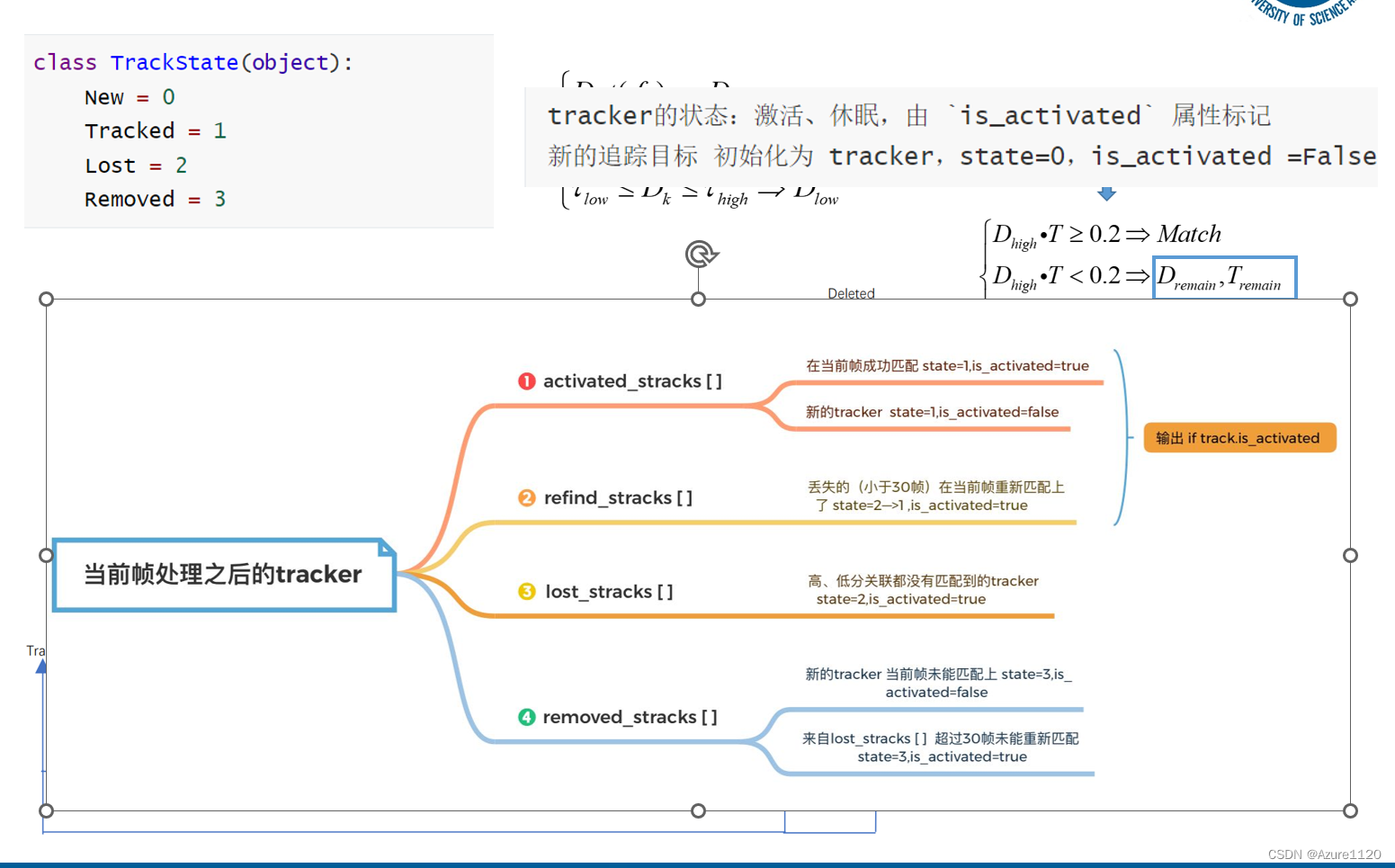
第三章适用的场景:
bytetrack分为高分匹配和低分匹配,但是轨迹只要是满足条件(上面的1、2 无论找回还是匹配上的)都会在两次中使用
所以,第三章适用 高分的检测框(无遮挡、检测条件非常好) ,并且满足如下阈值
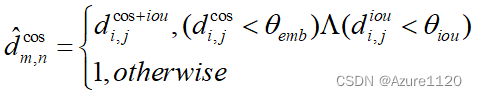
否则 低分匹配(遇到了遮挡、检测条件没有那么好) 就用纯第四章
2. 还答应帅哥 给改进的思路 主要是关于reid和iou的融合吧
dancetrack数据集
2023/11/20小组会
重点是关于IOU和Re-ID的融合
基于AW
余弦相似度的取值范围在 -1 到 1 之间,值越接近 1 表示两个向量越相似,越接近 -1 表示两个向量越不相似,接近 0 表示两个向量之间没有明显的相似性或差异。
首先 作者说的是使用 standard cosine similarity,不知道这个标准的意思是取值0到1吗? 先默认它是-1到1 。 但是另外一个问题 第一和第二差异度大不是个好事吗? 为什么要min限制呢?“where is a hyper-parameter to cap(限制) the boost where there's a large difference in appearance cost between the first and second best matches. ”
那么当E的值为0.75 Wb的最大值是0.75,最小值 是0,
对于外观成本矩阵必须要用iou来限制
明早过来 先把知云这个文献研究明白 然后把实验编出来,
下次组会需要再完善下第三章的实验 需要尽快动笔了 第三章写完才能第四章















 2273
2273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









