






1、主要贡献
MOT的最新趋势是利用深度学习来提高跟踪性能。然而,以端到端的方式解决数据关联问题并非易事。本文提出了一种新颖的基于提案的可学习框架,该框架将 MOT 建模为亲和图上的提案生成、提案评分和轨迹推理范式。该框架类似于两级目标检测器 Faster RCNN,可以以数据驱动的方式解决 MOT 问题。
对于提案生成,提出了一种迭代图聚类方法,在保持生成提案质量的同时降低计算成本;对于提案评分,部署了一个可训练的图卷积网络 (GCN) 来学习生成的提案的结构模式,并根据估计的质量分数对它们进行排名,可以直接优化整个提案分数而不是成对匹配成本,可以在提案中加入高阶信息来进行更准确的预测;对于轨迹推理,采用一种简单的去重叠策略来生成跟踪输出,同时遵守不能分配给多个轨道的约束。通过实验证明,所提出的方法在两个公共基准上实现了最先进的性能,在 MOTA 和 IDF1 上都取得了明显的性能改进
2、简要介绍
本文提出了一种简单但有效的方法,以数据驱动的方式解决 MOT 问题。
通过两个关键模块设计MOT算法:(1)提案生成(2)图卷积网络(GCN)的建议评分。
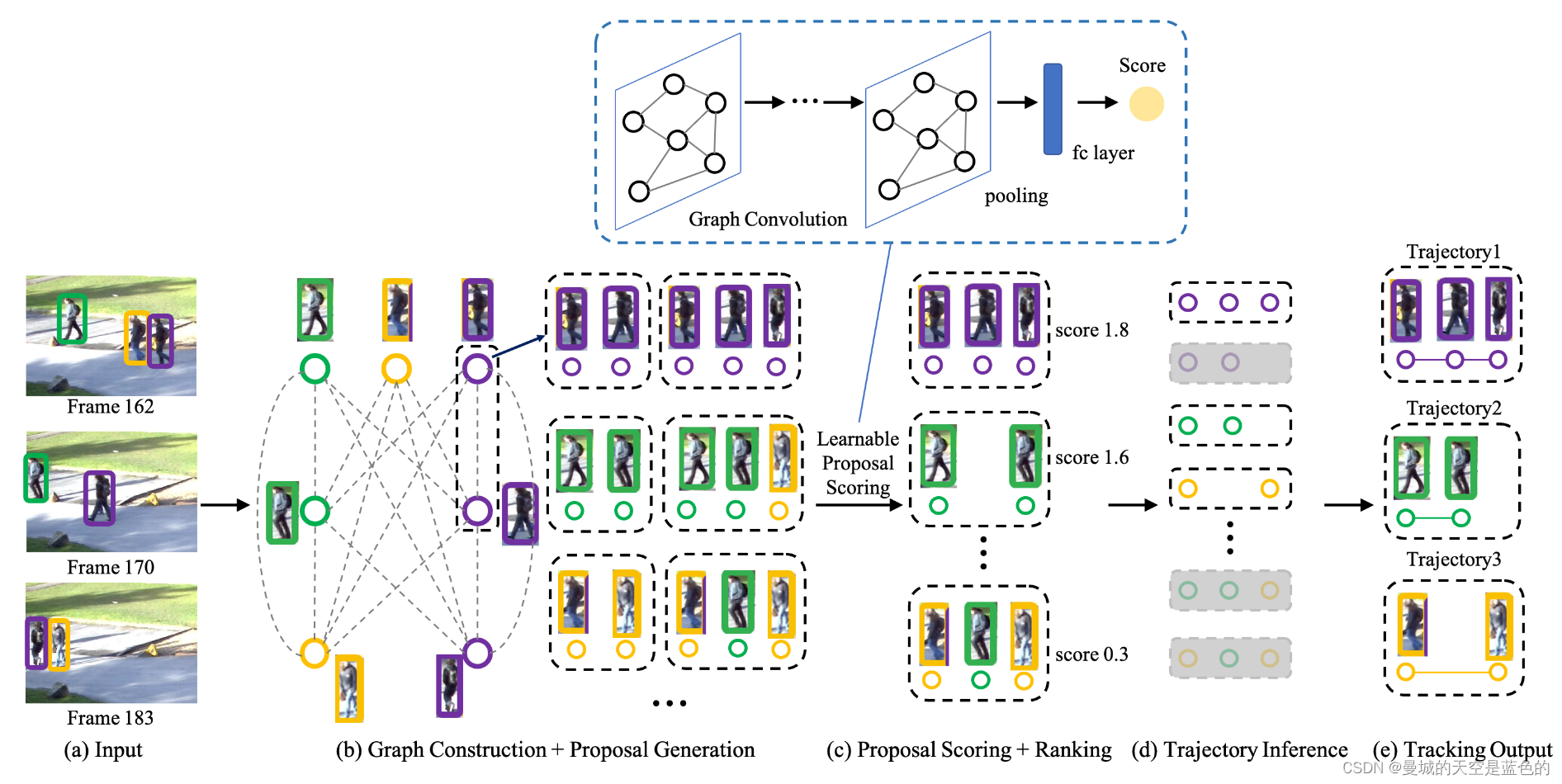
(a) 给定一组连续帧和检测的轨迹作为输入
(b) 构建一个图来对数据关联问题进行建模。图中的节点表示检测/轨迹,边表示节点之间的可能链接,不同颜色的节点表示不同的对象。基于亲和图生成一组提案,其中包含完整的轨迹集,以完全覆盖每个单独的对象,但也可能有多个带有污染的轨迹集的建议(如多个不同对象合并到同一提案中)。
(c) 下一步通过使用可训练的 GCN 来评估生成的提案的质量分数,使用学习到的排名/评分函数对它们进行排名,识别哪个提案比其他提案更好
(d) 最后采用推理算法来生成给定每个提议等级的跟踪输出,同时遵守典型的跟踪约束,例如没有分配给多个轨道的检测。
3、模型
3.1、输入数据
首先使用 CNN 提取每个检测的 ReID 特征。然后,通过累积三个基本亲和力(由它们的外观、时间戳和位置得到)来计算两个检测或检测到轨迹的整体亲和力。最后,通过基于匈牙利算法得到的的亲和力来连接检测生成低级轨迹。
3.2、生成提案
由于从亲和图 G 探索所有完美提案有很大的计算成本,所以提出一种迭代图聚类策略(由两个模块组成),通过模拟自下而上的聚类过程,可以在提案质量和计算成本之间提供良好的权衡
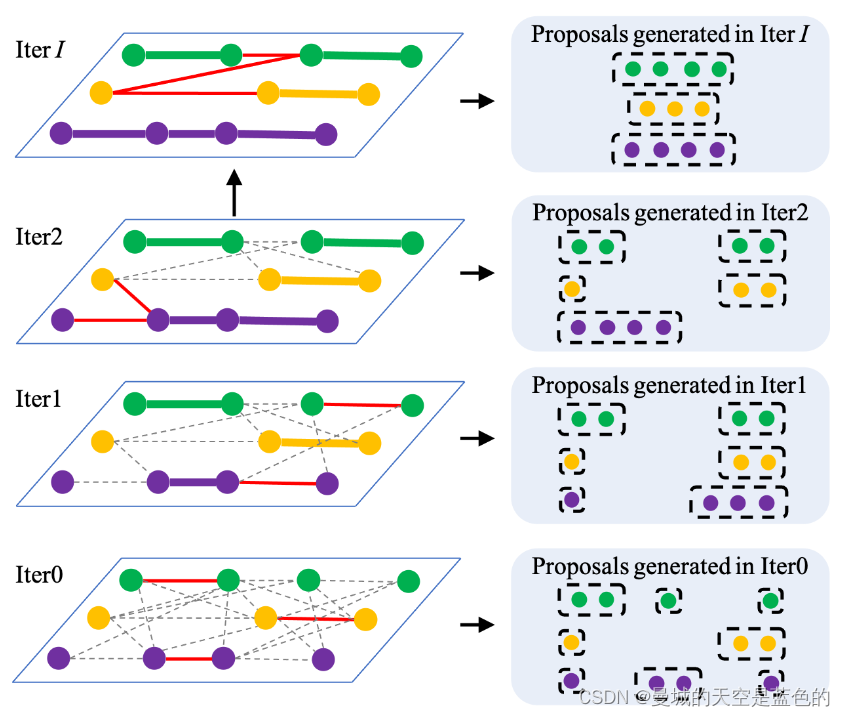
在每次迭代中,只有一小部分满足门控阈值的边(红色实线)才能处于活动状态。迭代 i 生成的每个集群将在迭代 i + 1 中分组为顶点。为了保持集群的纯度,在前几次迭代中设置严格的门控阈值。随着迭代次数的增加,这些阈值将逐渐放松以增长建议
亲和图构建
在每次迭代中 ,构建一个亲和图
来模拟顶点
之间的相似性。设顶点
,其中
是提案的平均ReId特征,
是提案中检测的排序时间戳,
是对应的 2D 图像坐标。边
的亲和力分数定义为基于时间、空间和外观相似性的平均分数
集群提案
提案生成的基本思想是使用连接组件来查找集群。为了在早期迭代中保证生成的集群纯度很高,将每个集群的最大大小限制为低于阈值 。在这个阶段,目标对象的顶点可能被过度分割成几个集群。迭代 i 生成的集群作为下一次迭代的输入顶点。并且在这些集群之上构建一个新图,从而产生更大尺寸的集群。最终的提议集包括每次迭代中的所有集群,从而提供不完整和多样化的提议集
3.3、提案评分
计算过完备的提案集的质量分数并对其进行排序,选择最能代表真实轨道的提案子集,理想情况下,质量分数可以定义为准确率和召回率的组合
(准确率和召回率公式可参见关于MOT常见数据集和评价指标的总结-CSDN博客)
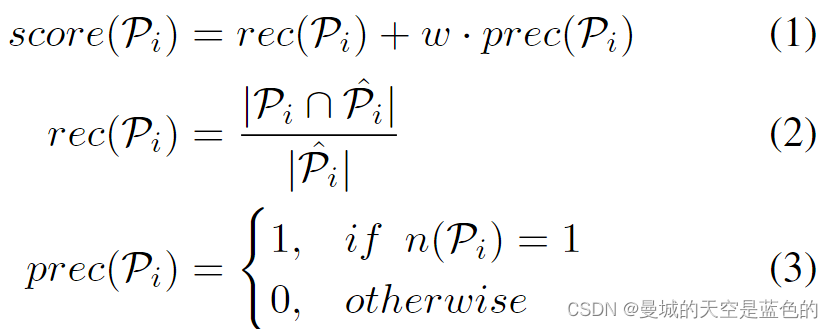
表示控制精度分数贡献的加权参数
表示提案
的大多数标签,
表示
所有检测的的真实对象(GT)
表示检测的数量
表示提案
中包含的标签数量
衡量纯度,
表示
和 匹配的真实对象(GT)
综合上述定义,采用基于GCN的网络来学习估计提案分数,可以通过训练利用二元交叉熵损失来学习提案的精度。然而,GCN 在探索整个图结构(包括与给定提议相距很远的顶点)的情况下学习提案的召回率要困难得多。由于归一化轨道长度 (,其中
是归一化常数)与精度高时提案的召回率正相关,因此用归一化轨道长度近似提案的召回率,并让网络专注于准确学习提案的精度。
纯度分类公式
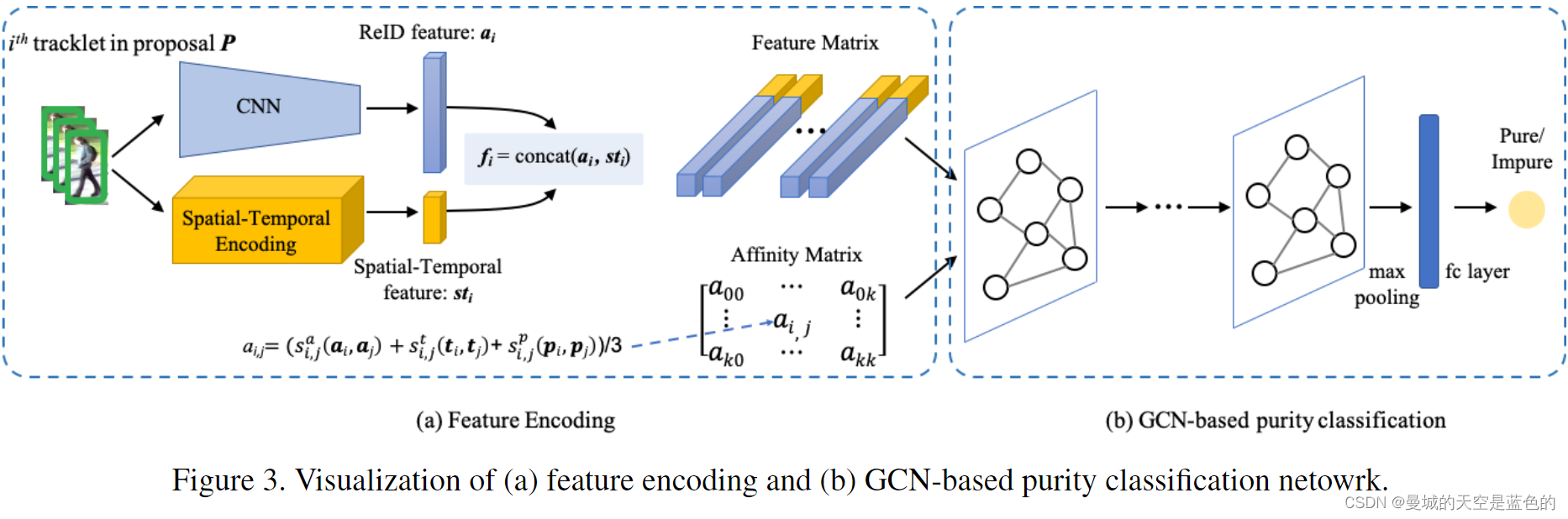
设计纯度分类网络来估计生成的提案 的精度分数
。具体来说,给定一个具有
个顶点的提案
,GCN 将与其顶点和子图亲和矩阵相关的特征作为输入,并预测提案
是纯的概率
特征编码的设计
外观和时空特征都是MOT的关键线索。对于外观特征,应用 CNN 直接从每个检测的 RGB 数据中提取特征并嵌入。然后,我们通过取所有检测外观特征的平均值得到对应的外观特征,再对每对时间相邻的小轨迹进行编码,包括它们的相对位置、相对方框大小以及时间上的距离。
GCN的设计
如上获得与 顶点相关的特征
,通过计算每对顶点之间的亲和力,采用全连接图构成
的亲和矩阵
,GCN 网络由
层组成,每一层的计算可以表述为
![]()
为对角矩阵,
表示第
层的特征嵌入,
表示变换矩阵,
是非线性激活函数
在顶层特征嵌入 中,对提案
中的所有顶点应用最大池化以提供整体摘要。最后,采用全连接层将
分为纯建议或无效建议
(1)计算每个顶点及其相邻特征的加权平均值(2) 用 转换特征(3) 将转换后的特征馈送到非线性激活函数。通过该公式,纯度分类网络可以学习提案
的内部一致性
3.4、轨迹推理
和目标检测中的非最大抑制类似,需要一种轨迹推理策略利用排序的提案生成最终的跟踪输出。为了减少计算成本,采用一个简单的去重叠算法。
通过纯度推理结果,可以得到所有提案的质量分数。采用一个简单的去重叠算法来保证每个轨迹小波都被分配一个唯一的轨迹 ID 。首先按照质量分数的降序对提案进行排名。然后从排序列表中按顺序将轨道 ID 分配给提案中的顶点,并通过删除前面的顶点来修改每个提案
4、结论
本文提出一种新颖的基于提案的 MOT 可学习框架。对于提案生成,提出了一种迭代图聚类策略,该策略在提案质量和计算成本之间取得了很好的平衡。对于提案评分,部署了基于 GCN 的纯度分类网络来捕获每个提案中的高阶信息,从而提高遮挡等挑战场景中的抗干扰能力。通过实验证明,与之前的最先进技术相比,该方法实现了明显的性能改进。















 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









