







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在 Google Cloud 上使用 TensorFlow 检测对象
使用 TensorFlow 和 Google Colab 训练自定义对象检测器
在 Google Colab 上运行的 TensorBoard
在第 7 章,使用 YOLO 进行对象检测中,我们学习了 YOLO 对象检测,然后,在前两章中,我们学习了动作识别和图像修复。本章标志着端到端( E2E ) 对象检测框架的开始,它为数据摄取和训练管道奠定了坚实的基础,然后是模型开发。在这里,我们将深入了解各种对象检测模型,例如 R-CNN、单次检测器( SSD )、基于区域的全卷积网络( R-FCN)) 和 Mask R-CNN,并使用 Google Cloud 和 Google Colab 笔记本进行动手练习。我们还将针对如何训练您自己的自定义图像以使用 TensorFlow 对象检测 API 开发对象检测模型进行详细练习。我们将以对各种对象跟踪方法的深入概述和使用 Google Colab 笔记本的动手练习来结束本章。
本章分为八个小节:
- SSD概述
- R-FCN概述
- TensorFlow 对象检测 API 概述
- 在 Google Cloud 上使用 TensorFlow 检测对象
- 使用 TensorFlow Hub 检测对象
- 使用 TensorFlow 和 Google Colab 训练自定义对象检测器
- Mask R-CNN 概述和 Google Colab 演示
- 开发对象跟踪器模型以补充对象检测器
SSD概述
SSD 是一种非常快速的对象检测器,非常适合部署在移动和边缘设备上进行实时预测。在本章中,我们将学习如何使用 SSD 开发模型,在下一章中,我们将评估其部署在边缘设备上时的性能。但在深入了解 SSD 的细节之前,我们将快速了解目前在本书中学到的其他物体检测器模型。
我们在第 5 章,神经网络架构和模型中了解到,Faster R-CNN 由 21,500 个区域提议(60 x 40 滑动窗口和 9 个锚框)组成,它们被扭曲成 2K 固定层。这些 2K 层被馈送到全连接层和边界框回归器以检测图像中的边界框。这 9 个锚框来自 3 个尺度,框面积分别为 128 2、256 2、512 2,以及三个纵横比——1:1、1:2 和 2:1。
128x128:1:1;128x128:1:2;128x128:2:1
256x256:1:1;256x256:1:2;256x256:2:1
512x512:1:1;512x512:1:2;512x512:2:1
在第 7 章,使用 YOLO 进行对象检测中,我们了解到YOLO 使用单个 CNN 来同时预测整个图像中对象的多个边界框。YOLO v3 检测分三层完成。YOLO v3 使用了 9 个锚点:(10, 13), (16, 30), (33, 23), (30, 61), (62, 45), (59, 119), (116, 90), (156) , 198), (373, 326)。此外,YOLO v3 使用了 9 个掩码,这些掩码链接到锚点,如下所述:
- 第一层:掩码 = 6、7、8;对应的锚点:(116, 90), (156, 198), (373, 326)
- 第二层:掩码 = 3、4、5;对应的锚点:(30, 61), (62, 45), (59, 119)
- 第三层:掩码 = 0, 1, 2; 对应的锚点:(10, 13), (16, 30), (33, 23)
SSD 于 2016 年由 Wei Liu、Dragomir Anguelov、Dumitru Erhan、Christian Szegedy、Scott Reed、Cheng-Yang Fu 和 Alexander C. Berg 在一篇题为SSD:Single Shot MultiBox Detector ( https://arxiv.org/ ) 的论文中介绍绝对/1512.02325 )。
它导致比 Faster R-CNN 更快的速度,而其准确性与 YOLO 相比。改进来自于消除区域提议并将小型卷积滤波器应用于特征图以预测不同尺度的多个层。
SSD 的主要特性概述如下:
- SSD 原始论文使用 VGG16 作为基础网络来提取特征层,但也可以考虑其他网络,例如 Inception 和 ResNet。
- SSD 在基础网络之上添加了额外的六个特征层,包括conv4_3、conv7( fc7)、conv8_2、conv9_2、conv10_2和conv11_2,用于对象检测。
- 一组默认框与每个特征图单元相关联,使得默认框位置相对于特征图单元是固定的。每个默认框预测每个c类的分数和相对于 ground truth 的四个偏移量,从而产生(c + 4)k过滤器。这些过滤器应用于特征图(具有m x n大小),产生(c + 4)kmn输出。下表说明了这一点。SSD 的独特之处在于,默认框适用于多个不同分辨率的特征图:
| 图层名称 | 检测 | 净过滤器输出 |
| Conv4_3 | 38 x 38 x 4 = 5776 | 3 x 3 x 4 x (c+4) |
| Conv7 | 19 x 19 x 6 = 2166 | 3 x 3 x 6 x (c+4) |
| Conv8_2 | 10 x 10 x 6 = 600 | 3 x 3 x 6 x (c+4) |
| Conv9_2 | 5 x 5 x 6 = 150 | 3 x 3 x 6 x (c+4) |
| Conv10_2 | 3 x 3 x 4 = 36 | 3 x 3 x 4 x (c+4) |
| Conv11_2 | 4 | |
| Total | 8732 |
- 默认框的设计是使用比例因子和纵横比创建的,这样特定大小的特征图(基于地面实况预测)与对象的特定比例相匹配。
- 比例范围可以从smin(0.2)到线性变化smax(0.95),而纵横比 ( ar) 可以取五个值(1、2、0.5、3.0和0.33),其中k1在到之间变化m。
- 对于 aspect ratio 1,添加了一个额外的默认框。因此,每个特征图位置最多有六个默认框。
- 默认盒子中心的坐标是((i+0.5)/|fk|, (j+0.5)/|fk|),其中|fk|是正方形特征图的大小,和kth的值从i到变化。对六个默认框中的每一个都重复此操作。j0|fk|
- SSD 通过将给定比例和纵横比的默认框与地面实况对象的默认框相匹配并消除不匹配的内容,来预测各种对象的大小和形状。默认框与地面实况对象的匹配是使用 Jaccard 重叠完成的,也称为联合交集( IOU ),在第 7 章“ 使用 YOLO 进行对象检测”中进行了介绍。例如,如果图像由human并且bus两者具有不同的纵横比和比例,SSD 显然能够识别这两者。当两个类彼此靠近且具有相同的纵横比时,问题就出现了,我们稍后会看到。
- 使用 R-CNN,区域提议网络执行筛选以限制被视为 2K 的样本数量。另一方面,SSD 没有区域建议,因此它生成的边界框数量要多得多(如我们之前所学,为 8,732 个),其中许多是反例。SSD 拒绝额外的负例,使用硬负挖掘来保持负和正之间的平衡,最多 3:1。硬负挖掘是一种使用置信损失进行排序的技术,以便保留最高值。
- SSD 使用非最大抑制来选择对给定类具有最高置信度的单个边界框。非最大抑制的概念在第 7 章, 使用 YOLO 进行目标检测中介绍过。非最大抑制算法选择概率最高的对象类并丢弃任何 IOU 大于 的边界框0.5。
- SSD 还通过在训练期间获取假阴性图像作为输入来使用硬阴性挖掘。SSD 保持 3:1 的负数与正数比率。
- 对于训练,使用以下参数:a300x300或图像大小、 40,000 次迭代512x512的学习率10-3和后续 10,000 次迭代的10-4到10-5 、衰减率0.0005和动量0.9。
R-FCN概述
R-FCN 比 SSD 更类似于 R-CNN。R-FCN 由主要来自微软研究院的团队于 2016 年开发,该团队由戴继峰、李毅、何凯明和孙健组成,在一篇题为R-FCN: Object Detection via Region-Based Fully Convolutional Networks的论文中提出。您可以在https://arxiv.org/abs/1605.06409找到该论文的链接。
R-FCN 也是基于区域提议。与 R-CNN 的主要区别在于,R-FCN 不是从 2K 区域提案网络开始,而是等到最后一层,然后应用选择性池化来提取特征进行预测。在本章中,我们将使用 R-FCN 训练我们的自定义模型,并将最终结果与其他模型进行比较。R-FCN的架构如下图所示:

在上图中,汽车的图像通过 ResNet-101 生成特征图。请注意,我们在第 4 章“使用图像深度学习”中学习了如何可视化卷积神经网络( CNN ) 的中间层及其特征图。这种技术本质上是一样的。然后,我们k x k在特征映射中取一个内核(在此图像中,k = 3)并将其滑过图像以创建一个分数映射。如果分数图包含一个对象,我们投票,如果没有,我们投票。跨不同区域的投票被展平以创建一个 softmax 层,该层映射到对象类以进行检测。k2(C+1)yesno
R-FCN 的主要特性更详细地描述如下:
- 在整个图像上计算一个全卷积区域提议网络( RPN ),类似于 R-CNN。
- R-FCN 不像 R-CNN 那样将 2K 扭曲区域发送到全连接层,而是使用预测之前的最后一个特征卷积层。
- ResNet-101,减去平均池化层和全连接层,用于特征提取。因此,只有卷积层用于计算特征图。ResNet-101 中的最后一个卷积块有 2048 个维度,它们被传递到一个 1024 维的 1×1 卷积层进行降维。
- 1,024 个卷积层生成一个分数图,它对应于通道输出,带有对象类别和背景。k2k2(C + 1)C
- 选择性池用于仅从分数图中的分数图中提取响应。k2
- 这种从最后一层提取特征的方法最大限度地减少了计算量,因此 R-FCN 甚至比 Faster R-CNN 更快。
- 对于边界框回归,在卷积层上使用平均池化,从而为每个感兴趣区域层生成一个维度向量。来自每一层的向量被聚合成四维向量,它将边界框的位置和几何特征描述为x、y、宽度和高度。4k24k24k2k2
- 对于训练,使用以下参数——衰减率为0.0005,动量为0.9,图像大小调整为600高度像素,学习率为0.001 的20,000 批次和0.0001的 10,000 批次。
TensorFlow 对象检测 API 概述
TensorFlow 对象检测 API 可以在models/research/object_detection at master · tensorflow/models · GitHub找到。在编写本书时,TensorFlow 对象检测 API 仅适用于 TensorFlow 版本 1.x。当您在终端中下载 TensorFlow 1.x 时,它会将models/research/object detection目录安装到您的 PC 上。如果您的 PC 上有 TensorFlow 2.0,则可以从 GitHub 下载研究目录,网址为models/research at master · tensorflow/models · GitHub。
TensorFlow 对象检测 API 具有预训练模型,您可以使用网络摄像头 ( https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/camera.html ) 检测这些模型以及示例训练自定义图像(Training Custom Object Detector — TensorFlow 2 Object Detection API tutorial documentation)。浏览前两个链接并自己尝试,然后返回下一部分。
在本章中,我们将使用 TensorFlow 对象检测器执行以下任务:
- 使用 Google Cloud 和 Coco 数据集上的预训练模型进行对象检测
- 使用 TensorFlow Hub 和 Coco 数据集上的预训练模型进行对象检测
- 使用迁移学习在 Google Colab 中训练自定义对象检测器
在所有这些示例中,我们将使用汉堡和炸薯条数据集进行检测和预测。
在 Google Cloud 上使用 TensorFlow 检测对象
以下说明介绍了如何使用 Google Cloud 上的 TensorFlow 对象检测 API 来检测对象。为此,您必须拥有 Gmail 和 Google Cloud 帐户。根据地区的不同,您提交信用卡信息后,Google Cloud 可以在有限的时间内免费提供访问权限。此处列出的练习应包含在此免费访问中。按照以下步骤在 Google Cloud Console 中创建虚拟机( VM ) 实例。需要一个 VM 来运行 TensorFlow 对象检测 API 并使用它进行推理:
- 登录到您的 Gmail 帐户并转到h ttps://cloud.google.com/solutions/creating-object-detection-application-tensorflow 。
- 创建一个项目,如下面的屏幕截图所示。这 R-CNN-trainingpack 是我的项目的名称。您的项目名称可能会有所不同。
- 按照启动 VM 实例下的 10 条说明进行操作 — 这也在步骤 12之后的屏幕截图中进行了说明。
- 在 Google Cloud Console 中,导航到VM Instances页面。
- 单击顶部的创建实例。它应该带您进入另一个页面,您必须在其中输入实例名称。
- 以小写字母输入实例的名称。请注意,实例名称与项目名称不同。
- 单击机器类型并选择n1-standard-8 (8vCPU, 30 GB memory) 。
- 单击Custom并调整水平条以将Machine type设置为8 vCPUs并将Memory设置为8GB,如下面的屏幕截图所示。
- 选择防火墙下的允许 HTTP 流量。
- 在Firewall下,您将看到Management、Security、Disks、Networking、Sole tenancy链接,如说明 VM 实例创建步骤的屏幕截图所示。单击它,然后单击网络选项卡。
- 在网络选项卡中选择网络接口部分。接下来,在网络接口部分,我们将通过在外部 IP下拉列表中分配一个新的 IP 地址来分配一个静态 IP 地址。给它一个名字(比如,staticip),然后点击Reserve。
- 完成所有这些步骤后,检查以确保您已按照说明填写所有内容,然后单击Create,如以下屏幕截图所示,以创建 VM 实例。
以下屏幕截图显示了R-CNN-trainingpack在谷歌云平台中创建一个名为的项目:
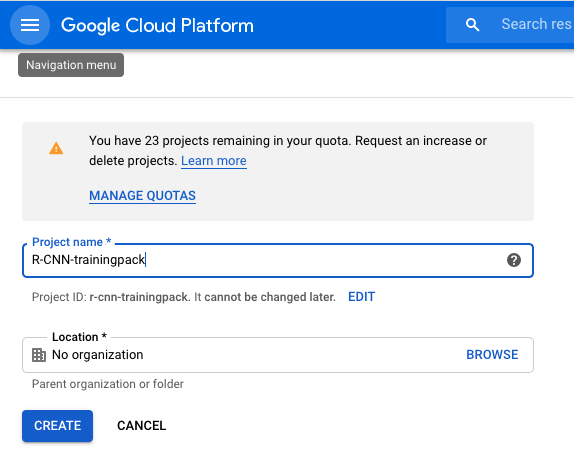
项目创建是第一步,然后我们将在项目中创建一个实例,如下一个屏幕截图所示。此屏幕截图说明了我们刚刚描述的 VM 实例创建步骤:
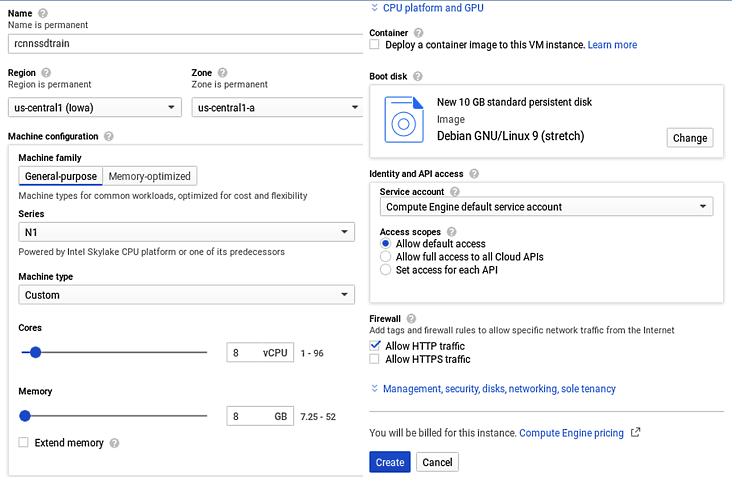
然后,按照以下说明在测试图像上创建对象检测推理:
- 接下来,我们将使用安全套接字外壳( SSH ) 客户端通过 Internet 安全地访问实例。您将需要输入用户名和密码。将用户名设置为username,密码设置为passw0rd;请记住,它不是obut 0,如零。
- 使用https://cloud.google.com/solutions/creating-object-detection-application-tensorflow中描述的说明安装TensorFlow 对象检测 API库和必备软件包。
正确按照上述说明上传图片后,您将获得如下输出:

在此 屏幕截图中,检测到了汉堡、酒杯和桌子,但未检测到炸薯条。我们将在下一节中看到为什么会这样,然后我们将训练我们自己的神经网络来检测这两种情况。
使用 TensorFlow Hub 检测对象
在此示例中,我们将从中导入 TensorFlow 库tfhub并使用它来检测对象。TensorFlow Hub ( https://www.tensorflow.org/hub ) 是一个库,其中代码可用并准备好用于计算机视觉应用程序。代码是从 TensorFlow Hub ( https://github.com/tensorflow/hub/blob/master/examples/colab/object_detection.ipynb ) 中提取的,除了图像是在本地插入的,而不是为云提取的。
tensorflow_hub在这里,我们通过导入和安装 TensorFlow 库six.moves。six.moves是一个 Python 模块,用于提供 Python 2 和 Python 3 之间的通用包。它显示图像并在图像上绘制边界框。在通过检测器之前,图像被转换成一个数组。检测器是一个直接从集线器加载的模块,它在后台执行所有神经网络处理。下面显示了tfhub在两个不同模型上运行示例图像时的输出:
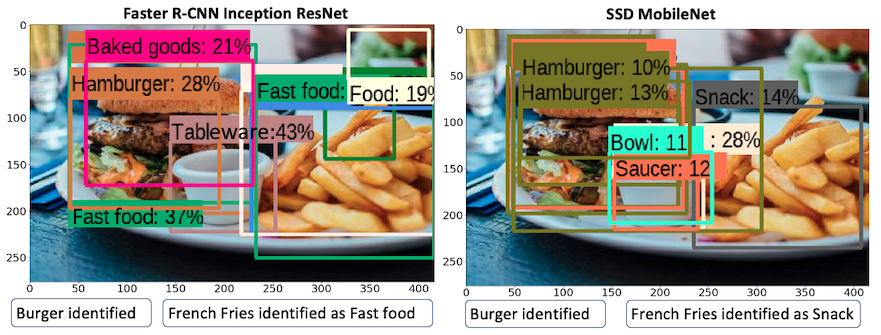
如您所见,使用 Inception 和 ResNet 作为特征提取器的 R-CNN 可以正确预测汉堡和炸薯条,以及许多其他对象。带有 MobileNet 模型的 SSD 可以检测到汉堡,但无法检测到炸薯条——它会将其分类到snacks类别中。当我们训练我们自己的对象检测器并开发我们自己的模型并在此基础上进行推断时,我们将在下一节中了解更多关于这一点的信息。
使用 TensorFlow 和 Google Colab 训练自定义对象检测器
在本练习中,我们将使用 TensorFlow 对象检测 API 来训练使用四种不同模型的自定义对象检测器。Google Colab是在 Google 服务器上运行的 VM,因此 TensorFlow 的所有包都得到了正确维护和更新:
| # | Model | Feature Extractor |
| 1 | Faster R-CNN | Inception |
| 2 | SSD | MobileNet |
| 3 | SSD | Inception |
| 4 | R-FCN | ResNet-101 |
我们将在本练习中使用迁移学习,从在 Coco 数据集上训练的预训练模型开始,然后在此基础上使用我们自己的数据集进行训练。TensorFlow 已经在 ModelZoo GitHub 站点中存储了预训练模型,该站点位于https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md。这些模型主要是具有不同特征提取器的 R-CNN、SSD 和 R-FCN。相应的配置文件可以在https://github.com/tensorflow/models/tree/master/research/object_detection/samples/configs找到。
Coco 数据集 ( http://cocodataset.org ) 具有以下类别:
Person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports, ball, kite, baseball, bat, baseball, glove, skateboard, surfboard, tennis, racket, bottle, wine, glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush如您所见,Coco 数据集没有burger或不French fries作为一个类别。与这些形状接近的项目是sandwich、donut和carrot。因此,我们将获得模型权重并在我们自己的数据集上使用迁移学习来开发检测器。GitHub 站点上的 Jupyter 笔记本包含执行 E2E 训练作业的 Python 代码。
训练工作使用 TensorFlow 对象检测 API,.py在执行过程中调用各种 Python 文件。我们在进行大量练习后发现,最好在 Google Colab 笔记本上运行这项工作,而不是在您自己的 PC 上运行。这是因为许多库是用 TensorFlow 1.x 版本编写的,需要进行转换才能在 TensorFlow 2.0 中工作。在本地 PC 上使用 Anaconda 运行作业时发生的一些错误示例如下所示:
module 'keras.backend' has no attribute 'image_dim_ordering'
self.dim_ordering = K.common.image_dim_ordering()
module 'tensorflow_core._api.v2.image' has no attribute 'resize_images'
rs = tf.image.resize(img[:, y:y+h, x:x+w, :], (self.pool_size, self.pool_size))
61 outputs.append(rs)
62
AttributeError: module 'tensorflow_core._api.v2.image' has no attribute 'resize_images'当作业在 Colab 上的 TensorFlow 中运行时,模块之间的依赖关系配置良好。因此,许多需要花费大量时间才能解决的简单错误不会出现,您可以将时间花在培训发展上,而不是修复错误以开始培训。
在以下部分中,提供了设置培训组合的分步指南。可以在https://github.com/PacktPublishing/Mastering-Computer-Vision-with-TensorFlow-2.0/blob/master/Chapter10/Chapter10_Tensorflow_Training_a_Object_Detector_GoogleColab.ipynb找到代码的详细信息。
收集图像并将其格式化为 .jpg 文件
本节介绍如何处理图像以使其具有通用格式和大小。此处列出了这些步骤:
- 了解您将使用多少个类,并确保您的图像具有平等的类分布。这意味着,例如,如果我们有两个类要使用 (burger和french fries),则图像应该包含大约三分之一的汉堡,三分之一是炸薯条,三分之一是两者的混合。仅仅拥有汉堡的图像和炸薯条的图像而不包括组合图像是不行的。
- 确保图像包含不同的方向。对于形状均匀的图像,例如汉堡的圆形或不均匀的形状(例如炸薯条),图像方向无关紧要,但对于特定形状(例如汽车、笔和船),从不同的方向是至关重要的。
- 将所有图像转换为.jpg格式。
- 调整所有图像的大小以供神经网络快速处理。在此示例中,416x416考虑了图像大小。在 Linux 中,您可以使用 ImageMagick 批量调整图像大小。
- 转换——将file.jpg其调整为416x416图像大小file.jpg。
- 将图像重命名为classname_00x.jpg格式
注释图像以创建 .xml 文件
在本节中,我们将描述如何创建注释文件。每个图像文件对应一个注释文件。注释文件通常采用.xml格式。创建注释文件的步骤如下所述:
- 在此步骤中,用于labelImg创建注释文件。这一步已经在第 7 章中讨论过,使用 YOLO 进行对象检测,但在这里再次重复。labelImg使用终端命令 下载pip install labelImg。
- 下载后,只需labelImg在终端输入即可打开。
- 定义您的源(.jpg文件)和目标(.xml文件)目录。
- 选择每个图像并在其周围绘制一个矩形。定义类名并保存。
- 如果给定图像中有多个类,请在每个类周围绘制一个矩形并为其分配相关的类名称。
此屏幕截图显示了我们如何在一张图像中标记两个类:
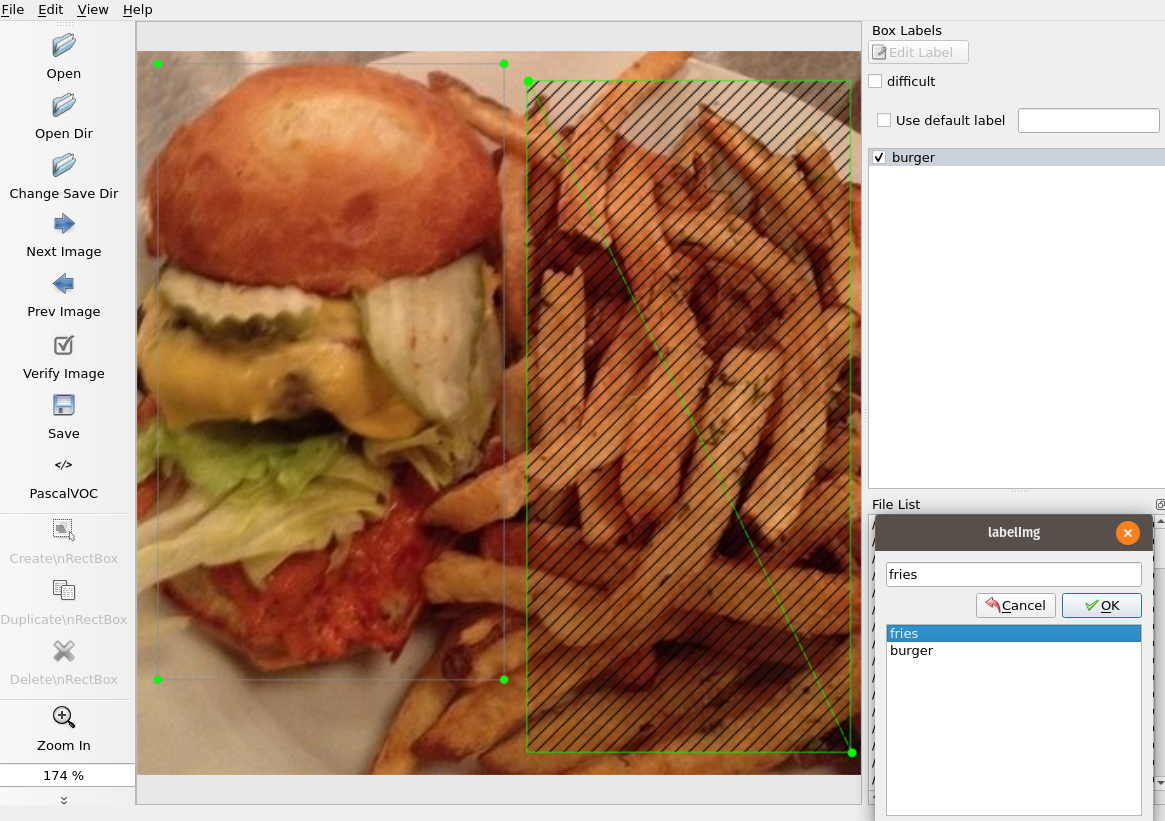
这显示了两个类-burger和fries- 以及如何labelImg在它们周围绘制边界框。的输出labelImg是.xml文件,该文件存储在单独的文件夹中。
通过 train 和 test 文件夹分隔文件
在本节中,我们将数据集划分为train和test文件夹。这是必需的,因为train模型使用train数据集生成模型和test数据集进行验证。请注意,有时testandval名称可以互换使用来表示相同的意思。但一般来说,我们需要第三个文件夹来检查我们的最终模型与模型以前没有见过的一些未知图像。包含这些图像的文件夹称为val- 稍后将讨论。
train按照此处列出的步骤将图像分成test文件夹。请注意,这些任务将在 Google Colab 上完成:
- 如果您按照上述步骤操作,您将拥有两个文件夹 - 一个用于图像,一个用于注释。接下来,我们创建两个单独的文件夹 -train和test.
- 将所有.jpg和.xml文件复制到任何文件夹中。因此,现在该文件夹将由背靠背.jpg和.xml文件组成。
- 将文件名类中的 70% 的文件(.jpg以及相应的.xml文件)复制到train文件夹中。因此,在这个练习之后,您将在train文件夹中拥有大约 140 个文件(70 个.jpg文件和 70 个.xml文件)。
- 将剩余 30% 的文件复制到该test文件夹。
- train将和文件夹上传test到 Google Drive 下data。
- 创建一个名为的验证文件夹val,并将所有类的一些图像插入其中。
7.在我的云端硬盘(如下图所示)下,创建一个名为的文件夹Chapter10_R-CNN,然后在 其中创建一个名为 的文件夹data:
8.创建data文件夹后,在 Google Drive 中创建两个名为annotations和的新文件夹 images,如图所示。下一个任务是填充这些目录。
此屏幕截图显示了其中的目录结构Chapter10_R-CNN和命名约定:
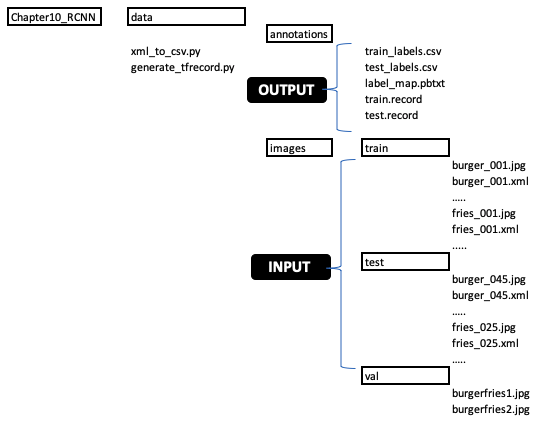
上图所示的目录结构应该是在 Google Drive 中建立的。按照此处描述的格式开始:
- INPUT代表images文件夹,需要提供所有图像数据。请记住遵循上图中概述的命名约定,并将.jpg文件和文件上传.xml到适当的目录,如上图所示。
- annotations是输出文件夹,应该是空的,下一节会填写。不要将annotations文件夹与注释图像混淆以创建.xml文件。所有.xml文件都在images文件夹中。
配置参数并安装所需的包
现在我们的图像准备工作已经完成,我们将开始在 Google Colab 笔记本中编码。第一步是参数配置和获取训练工作所需的包——这涉及模型的类型、训练的参数等。请按照以下步骤执行此操作:
- 在继续下一步之前,将 Chapter10_Tensorflow-Training_a_Object_Detector_GoogleColab.ipynb Python 文件保存到 Google Drive 并将其作为 Colab 笔记本打开。
- 运行单元Configure参数,然后按Shift + Enter按钮安装所需的包。
- 如果一切正常,您应该会看到显示模型配置选择的输出,如以下代码块所示。以下输出从config参数创建测试模型,是我们开始构建数据和准备测试之前的先决条件:
Running tests under Python 3.6.9: /usr/bin/python3
[ RUN ] ModelBuilderTest.test_create_experimental_model
[ OK ] ModelBuilderTest.test_create_experimental_model
[ RUN ] ModelBuilderTest.test_create_faster_R-CNN_model_from_config_with_example_miner
[ OK ] ModelBuilderTest.test_create_faster_R-CNN_model_from_config_with_example_miner
[ RUN ] ModelBuilderTest.test_create_faster_R-CNN_models_from_config_faster_R-CNN_with_matmul
[ OK ] ModelBuilderTest.test_create_faster_R-CNN_models_from_config_faster_R-CNN_with_matmul
[ RUN ] ModelBuilderTest.test_create_faster_R-CNN_models_from_config_faster_R-CNN_without_matmul
[ OK ] ModelBuilderTest.test_create_faster_R-CNN_models_from_config_faster_R-CNN_without_matmul
[ RUN ] ModelBuilderTest.test_create_faster_R-CNN_models_from_config_mask_R-CNN_with_matmul
[ OK ] ModelBuilderTest.test_create_faster_R-CNN_models_from_config_mask_R-CNN_with_matmul
[ RUN ] ModelBuilderTest.test_create_faster_R-CNN_models_from_config_mask_R-CNN_without_matmul
[ OK ] ModelBuilderTest.test_create_faster_R-CNN_models_from_config_mask_R-CNN_without_matmul
[ RUN ] ModelBuilderTest.test_create_rfcn_model_from_config
[ OK ] ModelBuilderTest.test_create_rfcn_model_from_config
[ RUN ] ModelBuilderTest.test_create_ssd_fpn_model_from_config
[ OK ] ModelBuilderTest.test_create_ssd_fpn_model_from_config
[ RUN ] ModelBuilderTest.test_create_ssd_models_from_config
[ OK ] ModelBuilderTest.test_create_ssd_models_from_config
[ RUN ] ModelBuilderTest.test_invalid_faster_R-CNN_batchnorm_update
[ OK ] ModelBuilderTest.test_invalid_faster_R-CNN_batchnorm_update
[ RUN ] ModelBuilderTest.test_invalid_first_stage_nms_iou_threshold
[ OK ] ModelBuilderTest.test_invalid_first_stage_nms_iou_threshold
[ RUN ] ModelBuilderTest.test_invalid_model_config_proto
[ OK ] ModelBuilderTest.test_invalid_model_config_proto
[ RUN ] ModelBuilderTest.test_invalid_second_stage_batch_size
[ OK ] ModelBuilderTest.test_invalid_second_stage_batch_size
[ RUN ] ModelBuilderTest.test_session
[ SKIPPED ] ModelBuilderTest.test_session
[ RUN ] ModelBuilderTest.test_unknown_faster_R-CNN_feature_extractor
[ OK ] ModelBuilderTest.test_unknown_faster_R-CNN_feature_extractor
[ RUN ] ModelBuilderTest.test_unknown_meta_architecture
[ OK ] ModelBuilderTest.test_unknown_meta_architecture
[ RUN ] ModelBuilderTest.test_unknown_ssd_feature_extractor
[ OK ] ModelBuilderTest.test_unknown_ssd_feature_extractor
----------------------------------------------------------------------
Ran 17 tests in 0.157s
OK (skipped=1)创建 TensorFlow 记录
这是非常重要的一步,我们中的许多人都在为此挣扎。请按照以下步骤创建tfRecord文件。在继续执行此步骤之前,您必须在上一步中安装所有必需的软件包:
1.在上图中,Chapter10_R-CNN文件夹下,有两个文件,就在datacallxml_to_csv.py和 generate之下tfrecord.py。这些文件应该从您的本地驱动器复制到 Google 驱动器。
2.当您使用pip install TensorFlow或安装 TensorFlow 时pip install tensorflow-gpu,它会models-master在您的目录下创建一个home目录。在其中,导航到research文件夹,然后导航到文件object_detection夹,您将找到xml_to_csv.py并生成tfrecord.py. 如前所述,复制这些并将它们插入 Google Drive。您也可以在本地运行以下步骤,但我注意到使用 TensorFlow 2.0 在本地运行时出现错误,因此对于本练习,我们将在 Google Colab 中运行它。
3.接下来,我们会将Chapter10_R-CNNGoogle Drive 中的文件夹链接到您的 Colab 笔记本。这是通过使用以下命令完成的:
from google.colab import drive
drive.mount('/content/drive')4.完成上述步骤后,系统会提示您输入 Google Drive 密钥,然后一旦输入,Google Drive 就会安装到 Colab 笔记本上。
5.Chapter10_R-CNN接下来,我们使用以下命令从 Colab 笔记本转到 Google Drive目录:
%cd /content/drive/My Drive/Chapter10_R-CNN6.现在,您可以执行生成tfRecord文件的步骤。
7.完全按照所示输入命令。此命令将数据中的所有.xml文件转换为文件夹中的文件:traintrain_labels.csvdata/annotations
!python xml_to_csv.py -i data/images/train -o data/annotations/train_labels.csv -l data/annotations8.此命令将数据中的所有.xml文件转换为文件夹中的文件:testtest_labels.csvdata/annotations
!python xml_to_csv.py -i data/images/test -o data/annotations/test_labels.csv9.此命令train.record从文件夹生成文件train_labels.csv和图像jpg文件train。它还生成lable_map.pbtxt文件:
!python generate_tfrecord.py --csv_input=data/annotations/train_labels.csv --output_path=data/annotations/train.record --img_path=data/images/train --label_map data/annotations/label_map.pbtxt10.此命令test.record从文件夹生成文件test_labels.csv和图像jpg文件test。它还生成lable_map.pbtxt文件:
!python generate_tfrecord.py --csv_input=data/annotations/test_labels.csv --output_path=data/annotations/test.record --img_path=data/images/test --label_map data/annotations/label_map.pbtx11.如果一切顺利,那么前面的代码行将生成以下输出。这标志着训练和测试tfRecord文件的成功生成。请注意,扩展名可以是tfRecord或record:
/content/drive/My Drive/Chapter10_R-CNN
Successfully converted xml to csv.
Generate `data/annotations/label_map.pbtxt`
Successfully converted xml to csv.
WARNING:tensorflow:From generate_tfrecord.py:134: The name tf.app.run is deprecated. Please use tf.compat.v1.app.run instead.
WARNING:tensorflow:From generate_tfrecord.py:107: The name tf.python_io.TFRecordWriter is deprecated. Please use tf.io.TFRecordWriter instead.
W0104 13:36:52.637130 139700938962816 module_wrapper.py:139] From generate_tfrecord.py:107: The name tf.python_io.TFRecordWriter is deprecated. Please use tf.io.TFRecordWriter instead.
WARNING:tensorflow:From /content/models/research/object_detection/utils/label_map_util.py:138: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.
W0104 13:36:52.647315 139700938962816 module_wrapper.py:139] From /content/models/research/object_detection/utils/label_map_util.py:138: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.
Successfully created the TFRecords: /content/drive/My Drive/Chapter10_R-CNN/data/annotations/train.record
WARNING:tensorflow:From generate_tfrecord.py:134: The name tf.app.run is deprecated. Please use tf.compat.v1.app.run instead.
WARNING:tensorflow:From generate_tfrecord.py:107: The name tf.python_io.TFRecordWriter is deprecated. Please use tf.io.TFRecordWriter instead.
W0104 13:36:55.923784 140224824006528 module_wrapper.py:139] From generate_tfrecord.py:107: The name tf.python_io.TFRecordWriter is deprecated. Please use tf.io.TFRecordWriter instead.
WARNING:tensorflow:From /content/models/research/object_detection/utils/label_map_util.py:138: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.
W0104 13:36:55.933046 140224824006528 module_wrapper.py:139] From /content/models/research/object_detection/utils/label_map_util.py:138: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.
Successfully created the TFRecords: /content/drive/My Drive/Chapter10_R-CNN/data/annotations/test.reco准备模型并配置训练管道
接下来,使用以下命令下载并解压缩基本模型。在配置参数和安装所需软件包部分的配置参数步骤中,已选择模型和相应的配置参数。根据配置参数和批量大小,可以选择四种不同的模型(SSD 的两种变体、Faster R-CNN 和 R-FCN)。您可以从指示的批量大小开始,并在模型优化期间根据需要进行调整:
MODEL_FILE = MODEL + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
DEST_DIR = '/content/models/research/pretrained_model'在这里,目标目录是 Google Colab 笔记本本身,并且该content/models/research目录就在那里——因此,无需自己创建一个。这是在您安装所需的软件包部分时完成的。
此步骤还将自动从您的label_map.pbtxt文件中下载一些类,并调整大小、比例和纵横比以及卷积超参数,为训练作业做好准备。
使用 TensorBoard 监控训练进度
TensorBoard 是一种用于实时监控和可视化训练进度的工具。它绘制了训练损失和准确率,因此无需手动绘制它。TensorBoard 可让您可视化模型图并具有许多其他功能。访问https://www.tensorflow.org/tensorboard以了解有关 TensorBoard 功能的更多信息。
在本地机器上运行的 TensorBoard
通过添加以下代码行,可以将 TensorBoard 添加到您的模型训练中。检查 GitHub 页面上提供的代码以获取确切位置:
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
history = model.fit(x=x_train, y=y_train, epochs=25, validation_data=(x_test, y_test), callbacks=[tensorboard_callback])然后,可以在训练开始后通过在终端中键入以下内容来可视化 TensorBoard 图:
%tensorboard --logdir logs/fit在 Google Colab 上运行的 TensorBoard
本节介绍如何在 Google Colab 上运行 TensorBoard。这涉及以下步骤:
1.为了在 Google Colab 上运行 TensorBoard,必须从本地 PC 访问 TensorBoard 页面。这是通过名为ngrok的服务完成的,该服务将您的本地 PC 链接到 TensorBoard。使用以下两行代码将Ngrok下载并解压缩到您的 PC:
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
!unzip ngrok-stable-linux-amd64.zip2.接下来,使用以下代码打开 TensorBoard:
LOG_DIR = model_dir
get_ipython().system_raw(
'tensorboard --logdir {} --host 0.0.0.0 --port 6006 &
.format(LOG_DIR))3.在此之后,ngrok调用使用 port 启动 TensorBoard 6006,这是一种传输通信协议,用于通信和交换数据:
get_ipython().system_raw('./ngrok http 6006 &')4.最后一步是使用以下命令设置一个公共 URL 以访问 Google Colab TensorBoard:
! curl -s http://localhost:4040/api/tunnels | python3 -c \
"import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"训练模型
完成上述所有步骤后,我们就可以进行最重要的步骤了——训练我们的自定义神经网络。
使用以下五个步骤来训练模型,代码中也列出了这些步骤:
- 指定配置文件。
- 指定输出模型目录。
- 指定STDERR文件的发送位置。
- 指定训练步骤的数量。
- 指定验证步骤的数量:
!python /content/models/research/object_detection/model_main.py \
--pipeline_config_path={pipeline_fname} \
--model_dir={model_dir} \
--alsologtostderr \
--num_train_steps={num_steps} \
--num_eval_steps={num_eval_steps}这段代码的解释如下:
- 流水线配置路径由 定义pipeline_fname,即模型和配置文件。
- Model_dir是training目录。请注意,TensorBoard LOG_DIR它也映射到model_dir,因此 TensorBoard 在训练期间获取数据。
- 训练和评估步骤的数量是在配置设置期间预先定义的,并且可以根据需要进行调整。
成功开始训练后,您将开始在 Jupyter 笔记本中看到消息。在某些包上的一些警告被弃用后,您将开始看到有关训练步骤的评论,并且将成功打开一个动态库:
INFO:tensorflow:Maybe overwriting train_steps: 1000
Successfully opened dynamic library libcudnn.so.7
Successfully opened dynamic library libcublas.so.10
INFO:tensorflow:loss = 2.5942094, step = 0
loss = 2.5942094, step = 0
INFO:tensorflow:global_step/sec: 0.722117
global_step/sec: 0.722117
INFO:tensorflow:loss = 0.4186823, step = 100 (138.482 sec)
loss = 0.4186823, step = 100 (138.482 sec)
INFO:tensorflow:global_step/sec: 0.734027
global_step/sec: 0.734027
INFO:tensorflow:loss = 0.3267398, step = 200 (136.235 sec)
loss = 0.3267398, step = 200 (136.235 sec)
INFO:tensorflow:global_step/sec: 0.721528
global_step/sec: 0.721528
INFO:tensorflow:loss = 0.21641359, step = 300 (138.595 sec)
loss = 0.21641359, step = 300 (138.595 sec)
INFO:tensorflow:global_step/sec: 0.723918
global_step/sec: 0.723918
INFO:tensorflow:loss = 0.16113645, step = 400 (138.137 sec)
loss = 0.16113645, step = 400 (138.137 sec)
INFO:tensorflow:Saving checkpoints for 419 into training/model.ckpt.
model.ckpt-419
INFO:tensorflow:global_step/sec: 0.618595
global_step/sec: 0.618595
INFO:tensorflow:loss = 0.07212131, step = 500 (161.657 sec)
loss = 0.07212131, step = 500 (161.657 sec)
INFO:tensorflow:global_step/sec: 0.722247
] global_step/sec: 0.722247
INFO:tensorflow:loss = 0.11067433, step = 600 (138.457 sec)
loss = 0.11067433, step = 600 (138.457 sec)
INFO:tensorflow:global_step/sec: 0.72064
global_step/sec: 0.72064
INFO:tensorflow:loss = 0.07734648, step = 700 (138.765 sec)
loss = 0.07734648, step = 700 (138.765 sec)
INFO:tensorflow:global_step/sec: 0.722494
global_step/sec: 0.722494
INFO:tensorflow:loss = 0.088129714, step = 800 (138.410 sec)
loss = 0.088129714, step = 800 (138.410 sec)
INFO:tensorflow:Saving checkpoints for 836 into training/model.ckpt.
I0107 15:44:16.116585 14036592158
INFO:tensorflow:global_step/sec: 0.630514
global_step/sec: 0.630514
INFO:tensorflow:loss = 0.08999817, step = 900 (158.601 sec)
loss = 0.08999817, step = 900 (158.601 sec)
INFO:tensorflow:Saving checkpoints for 1000 into training/model.ckpt.
Saving checkpoints for 1000 into training/model.ckpt.
INFO:tensorflow:Skip the current checkpoint eval due to throttle secs (600 secs).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.505
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.915
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.493
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.200
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.509
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.552
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.602
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.611
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.600
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.611
SavedModel written to: training/export/Servo/temp-b'1578412123'/saved_model.pb
INFO:tensorflow:Loss for final step: 0.06650969.
Loss for final step: 0.06650969.注意前面显示的输出。根据您的 CPU/GPU 能力,执行此步骤需要不同的时间。在前面的训练输出中要注意的最重要的事情是训练期间的准确率和召回值。
运行推理测试
此步骤涉及导出经过训练的推理图和运行推理测试。推理是使用以下 Python 命令完成的:
!python /content/models/research/object_detection/export_inference_graph.py \
--input_type=image_tensor \
--pipeline_config_path={pipeline_fname} \
--output_directory={output_directory} \
--trained_checkpoint_prefix={last_model_path}在这里,last_model_path是model_dir,模型检查点在训练期间存储的地方,pipeline_fname是模型路径和配置文件。检查点涵盖了模型在训练期间使用的参数值。下图显示了在训练期间开发的四种不同模型的输出。这些通过执行前面的过程并仅选择不同的模型类型来逐一运行:
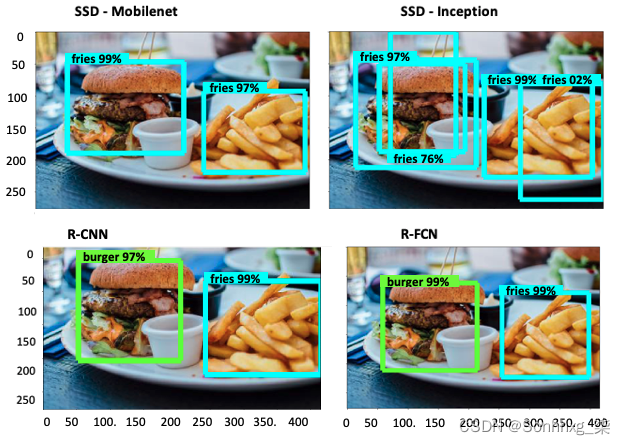
请注意,前面提到的带有代码块的模型针对四种不同的模型运行,如前所述。在运行下一个模型之前,单击Google Colab 页面顶部的Runtime并选择Factory reset runtime,这样您就可以重新开始新模型了。请注意,SSD 模型仍然 无法正确检测对象,而 R-CNN 和 R-FCN 能够正确检测汉堡和炸薯条。这可能是因为汉堡和炸薯条的大小几乎相同,我们从 SSD 概述中了解到 SSD 更擅长检测不同尺度的图像。
一旦设置了 TensorBoard,输出就可以在 TensorBoard 中可视化。
TensorBoard 具有三个选项卡——标量、图像和图表。标量包括mAP(精度)、召回率和损失值,图像包括前面的视觉图像,图包括TensorFlow图形frozen_inference_graph.pb文件。请注意,精确率和召回率之间的差异定义如下:
- 精度 = 真阳性/(真阳性 + 假阳性)
- 召回=真阳性/(真阳性+假阴性)
使用神经网络模型时的注意事项
请注意,我们只使用 了 68 张图像来训练我们的神经网络,它给了我们非常好的预测。这就提出了四个问题:
- 我们开发的模型在所有情况下都能正确预测吗?答案是不。该模型只有两个类burger,fries因此它可以检测其他类似于汉堡形状的对象,例如甜甜圈。为了解决这个问题,我们需要加载相似的图像burger并将它们分类为 not burger,然后用这些额外的图像集训练模型。
- 为什么我们听说我们需要数千张图像来训练神经网络?如果您正在从头开始训练神经网络,甚至使用迁移学习从另一个模型(例如 Inception 或 ResNet)获取权重,但该模型之前没有看到您的新图像,那么您至少需要 1,000 张图像。1,000 来自 ImageNet 数据集,每个类别有 1,000 张图像。
- 如果我们需要数千张图像来训练,那为什么它在我们的案例中起作用?在我们的案例中,我们使用了迁移学习并下载了 ImageNet 数据集的权重。ImageNet 数据集已经cheeseburger属于一类,因此对少于 100 张图像的迁移学习效果很好。
- 在使用少于 1,000 张图像开发模型的情况下,它什么时候根本检测不到任何物体?在对象与 ImageNet 类中的任何对象非常不同的情况下,例如在检测车身上的划痕、红外图像等时。
Mask R-CNN 概述和 Google Colab 演示
Mask R-CNN ( https://arxiv.org/abs/1703.06870 ) 由 Kaiming He、Georgia Gkioxari、Piotr Dollar 和 Ross Girshick 在CVPR 2017 上提出。Mask R-CNN 使用 R-CNN 有效地检测图像中的对象,同时针对每个感兴趣区域执行对象分割任务。因此,分割任务与分类和边界框回归并行工作。Mask R-CNN 的高层架构如下:
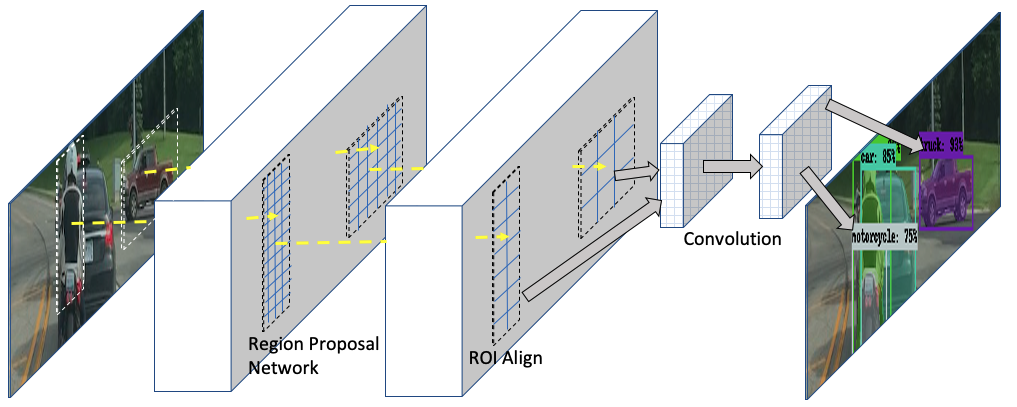
Mask R-CNN 的实现细节如下:
- Mask R-CNN 遵循 Faster R-CNN 的一般两阶段原则,但进行了修改——第一阶段RPN与 Faster R-CNN 保持相同。第二阶段,Fast R-CNN,从感兴趣区域( RoI ) 的特征提取、分类和边界框回归开始,也为每个 RoI 输出一个二进制掩码。
- 掩码表示输入对象的空间形状。Mask R-CNN使用全卷积网络为每个 RoI预测一个 ( M x N ) 掩码以进行语义分割。
- 在将特征图划分为M x N网格之后,在区域提议网络的输出处应用 RoI Align,然后在每个 bin 中应用 2 x 2 bin 和四个采样点,使用双线性插值法进行选择。RoI Align 用于将提取的特征与输入对齐。
- 主干神经网络通过提取第四阶段的最终卷积层使用 ResNet-50 或 -101。
- 训练图像被重新缩放,使得较短的边缘为 800 像素。每个 mini-batch 每个 GPU 有两个图像,正负样本的比例为 1:3。训练继续进行 160,000 次迭代,学习率0.02高达 120,000 次迭代,然后下降到0.002. 使用权重衰减0.0001和动量0.9。
Mask R-CNN 图像分割演示是用 Google Colab 编写的,可在https://github.com/PacktPublishing/Mastering-Computer-Vision-with-TensorFlow-2.0/blob/master/Chapter10/Chapter10_Mask_R_CNN_Image_Segmentation_Demo.ipynb找到。
笔记本加载示例图像并通过激活 TPU 创建 TensorFlow 会话。然后它加载一个预训练的模型掩码 R-CNN,然后执行实例分割和预测。该笔记本取自 Google Colab 站点,仅进行了一项修改——图像加载功能。下图显示了 Mask R-CNN 的输出:

Mask R-CNN 在前面概述的 Coco 数据集上进行了训练。所以, human,car和traffic light已经是为此预定的类。使用边界框检测每个人、汽车和交通灯,并使用分割绘制形状。
开发对象跟踪器模型以补充对象检测器
对象跟踪从对象检测开始,为每个检测分配一组唯一的 ID,并在对象四处移动时保持该 ID。在本节中,将详细描述不同类型的对象跟踪模型。
基于质心的跟踪
顾名思义,基于质心的跟踪涉及跟踪使用阈值开发的图像集群的质心。在初始化时,ID 被分配给边界框质心。在下一帧中,通过查看两帧之间的相对距离来分配 ID。此方法在物体相距很远时有效,但在物体彼此非常接近时无效。
排序跟踪
SORT 是由 Alex Bewley、Zongyuan Ge、Lionel Ott、Fabio Ramos 和 Ben Upcroft 在他们题为Simple Online and Realtime Tracking ( https://arxiv.org/abs/1602.00763 )的论文中介绍的。本文使用 Faster R-CNN 进行检测,而卡尔曼滤波器和匈牙利算法用于实时多目标跟踪( MOT )。可以在GitHub - abewley/sort: Simple, online, and realtime tracking of multiple objects in a video sequence.找到跟踪实现的详细信息。
深度排序跟踪
在 CVPR 2017 上,Nicolai Wojke、Alex Bewley 和 Dietrich Paulus 在他们题为Simple Online and Real-Time Tracking with a Deep Association Metric的论文中提出了 DeepSORT 跟踪。该论文的详细信息可以在https://arxiv.org/abs/1703.07402找到。
DeepSORT 是 SORT 的扩展,并使用经过训练以区分行人的 CNN 在边界框内集成外观信息。可以在https://github.com/nwojke/deep_sort找到跟踪实施的详细信息。
架构的细节概述如下:
- 跟踪场景定义在八维状态空间(u, v, γ, h, x, y, γ, h)上,其中(u, v) 是边界框中心位置,γ是纵横比,并且 h 是高度。
- 卡尔曼滤波器根据当前位置和速度信息预测未来状态。在 DeepSORT 中,使用基于位置和速度的卡尔曼滤波器来寻找下一个跟踪位置。
- 对于每个轨迹k,帧数在卡尔曼滤波器预测期间被计数并递增,并0在对象检测期间重置。删除前三帧内超过阈值或与检测无关的轨迹。
- 预测的卡尔曼状态和新到达的测量值之间的关联通过两个状态(预测的和新的测量值)之间的马氏距离和外观描述符之间的余弦相似度的组合来解决。
- 引入了匹配级联,优先考虑更常见的对象。
- IoU 关联的计算是为了解释场景中的突然消失。
- 一个宽的 ResNet 神经网络,它减少了深度并增加了宽度,已被用于提高薄残差网络的性能。宽 ResNet 层有两个卷积层和六个残差块。
- DeepSort 使用在 1251 个行人的 110 万张人类图像上训练的模型,并为每个边界框提取一个 128 个暗淡向量用于特征提取。
OpenCV 跟踪方法
OpenCV 有许多内置的跟踪方法:
- A BOOSTING 跟踪器:基于 Haar 级联的旧跟踪器。
- A MIL 跟踪器:比 BOOSTING 跟踪器具有更好的准确性。
- A Kernelized Correlation Filters ( KCF) 跟踪器:这比 BOOSTING 和 MIL 跟踪器更快。
- CSRT 跟踪器:这比 KCF 更准确,但跟踪可能更慢。
- MedianFlow 跟踪器:当对象有规律的移动并且在整个序列中可见时,该跟踪器工作。
- TLD 跟踪器:不要使用它。
- MOSSE 跟踪器:一个非常快速的跟踪器,但不如 CSRT 或 KCF 准确。
- GOTURN 跟踪器:基于深度学习的对象跟踪器。
上述方法在 OpenCV 中的实现如下:
tracker = cv2.TrackerBoosting_create()
tracker = cv2.TrackerCSRT_create()
tracker = cv2.TrackerKCF_create()
tracker = cv2.TrackerMedianFlow_create()
tracker = cv2.TrackerMIL_create()
tracker = cv2.TrackerMOSSE_create()
tracker = cv2.TrackerTLD_create()基于连体网络的跟踪
基于 Siamese 网络的对象跟踪由 Luca Bertinetto、Jack Valmadre、Joao F. Henriques、Andrea Vedaldi 和 Philip HS Torr 在其具有里程碑意义的论文Fully-Convolutional Siame se Networks for Object Tracking中提出。论文的详细信息可以在https://arxiv.org/abs/1606.09549找到。
在本文中,作者训练了一个深度卷积网络以离线开发相似度函数,然后将其应用于实时对象跟踪。相似度函数是一个 Siamese CNN,它将测试边界框与训练边界框(ground truth)进行比较并返回一个高分。如果两个边界框包含相同的对象且得分较低,则对象不同。
Siamese 网络通过相同的神经网络传递两个图像。它通过删除最后一个全连接层来计算特征向量,这在第 6 章,使用迁移学习的视觉搜索中进行了描述。然后它比较两个特征向量的相似性。使用的连体网络没有任何全连接层。因此,仅使用卷积滤波器,因此网络相对于输入图像是完全卷积的。全卷积网络的优点是它与大小无关;因此,任何输入大小都可以用于test和train图像。下图解释了 Siamese 网络的架构:

在图中,网络的输出是一个特征图。该过程通过 CNN ( fθ ) 重复两次,测试 ( x ) 和训练 ( z ) 图像各一次,产生两个互相关的特征图,如下所示:
g θ (z, x) = f θ (z) * f θ (x)
跟踪开始如下:
- 初始图像位置 = 先前的目标位置
- 位移 = 步幅乘以最大分数相对于中心的位置
- 新位置 = 初始位置 + 位移
因此,使用矩形边界框来初始化目标。在随后的每一帧,它的位置是使用跟踪估计的。
基于 SiamMask 的跟踪
在 CVPR 2019 上,Qiang Wang、Li Zhang、Luca Bertinetto、Weiming Hu 和 Phillip HSTorr 在他们的论文Fast Online Object Tracking and Segmentation: A Unifying Approach中提出了 SiamMask 。有关该论文的更多详细信息,请访问https://arxiv.org/abs/1812.05050。
SiamMask 使用单个边界框初始化并以每秒 55 帧的速度跟踪对象边界框。
在这里,将 Siamese 网络的简单互相关替换为深度相关,以生成多通道响应图:
- 使用简单的两层 1 x 1 卷积神经网络hf设计一个w x h二进制掩码(每个特征图一个) 。第一层有 256 个通道,第二层有 63 x 63 个通道。
- ResNet-50 用于 CNN,直到第三阶段结束,以 1 x 1 卷积层结束。请注意,ResNet-50 有四个阶段,但只考虑前三个阶段,并对用于将输出步幅减小到 8 的步幅 1 的卷积进行了修改。
- DeepLab中使用了扩张(atrous)卷积(详细描述见第 8 章,语义分割和神经风格迁移)增加感受野。ResNet 第三阶段的最终输出附加了一个具有 256 个输出的 1 x 1 卷积。
SiamMask 也可以使用 Google Colab 在 YouTube 视频文件上运行,网址为https://colab.research.google.com/github/tugstugi/dl-colab-notebooks/blob/master/notebooks/SiamMask.ipynb。
请注意,为了成功运行,视频文件必须以人物图像开头。
概括
在本章中,您从头到尾深入了解了各种对象检测器方法和使用您自己的自定义图像训练对象检测器的实用方法。学习的一些关键概念包括如何使用 Google Cloud 评估对象检测器、如何使用labelImg创建注释文件、如何将 Google Drive 链接到 Google Colab 笔记本以读取文件、如何生成 TensorFlowtfRecord文件.xml和.jpg文件,如何开始训练过程并在训练期间监控读数,如何创建 TensorBoard 以观察训练准确性,如何在训练后保存模型,以及如何使用保存的模型进行推理。使用此方法,您可以选择对象类别并创建用于推理的对象检测模型。您还学习了各种对象跟踪技术,例如卡尔曼滤波和基于神经网络的跟踪,例如 DeepSORT 和基于连体网络的对象跟踪方法。下一步,您可以将对象检测模型连接到跟踪方法以跟踪检测到的对象。
在下一章中,我们将通过在边缘设备(例如手机)中优化和部署神经网络模型来了解边缘计算机视觉。我们还将学习使用 Raspberry Pi 进行实时对象检测。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}