







本代码基于《动手学深度学习》Pytorch版,第四章多层感知机,第一节多层感知机,第二部分激活函数。对代码进行修改,增加注释,供学习使用。
导入相关库
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False设置变量
x = torch.arange(-10, 10, 0.1, requires_grad = True)ReLU函数
y = torch.relu(x)
plt.title('ReLU函数')
plt.xlabel('x')
plt.ylabel('relu(x)')
plt.plot(x.detach(), y.detach())
# .detach()从计算图中分离张量,以便在后续计算中不再跟踪梯度
plt.show()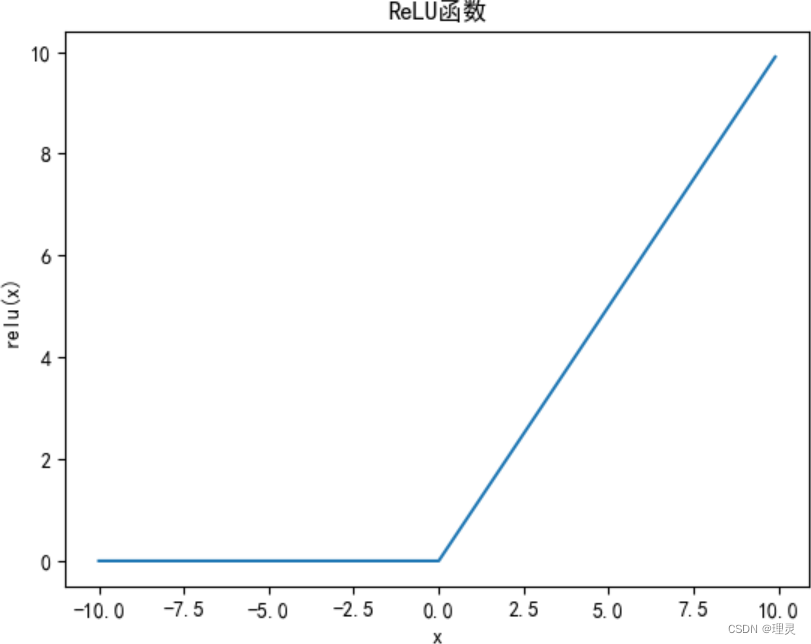
y.backward(torch.ones_like(x), retain_graph = True)
# retain_graph = True是backward()的参数,指示是否在计算梯度后保留计算图,以便在后续计算中重复使用计算图
# 保留计算图会占用内存,在训练大型神经网络时要谨慎使用此选项
# 可在计算梯度后释放计算图以节省内存,可使用.grad.zero_()将梯度清零或使用torch.no_grad()上下文管理器来阻止梯度计算
plt.title('ReLU函数梯度')
plt.xlabel('x')
plt.ylabel('grad of relu')
plt.plot(x.detach(), x.grad)
plt.show()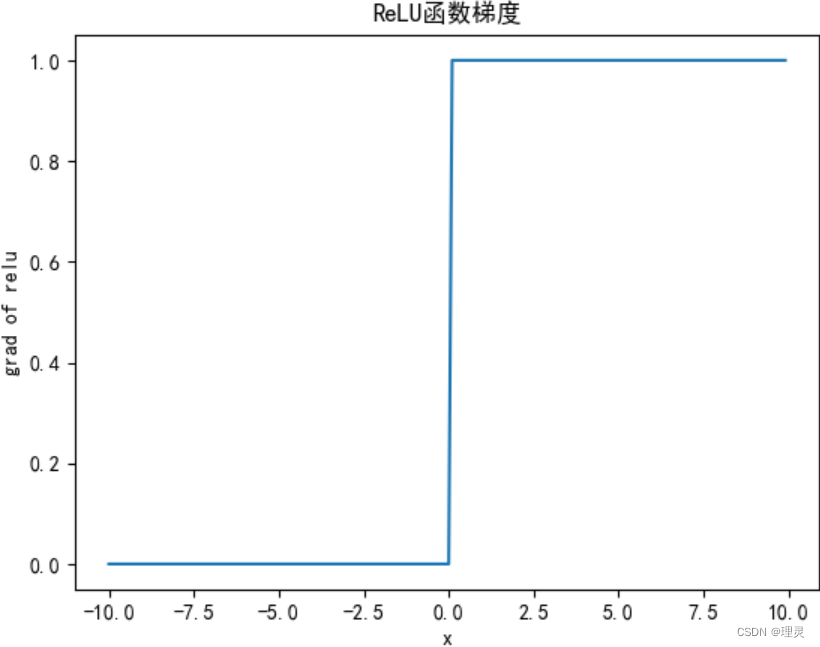
sigmoid函数
y = torch.sigmoid(x)
plt.title('sigmoid函数')
plt.xlabel('x')
plt.ylabel('sigmoid(x)')
plt.plot(x.detach(), y.detach())
plt.show()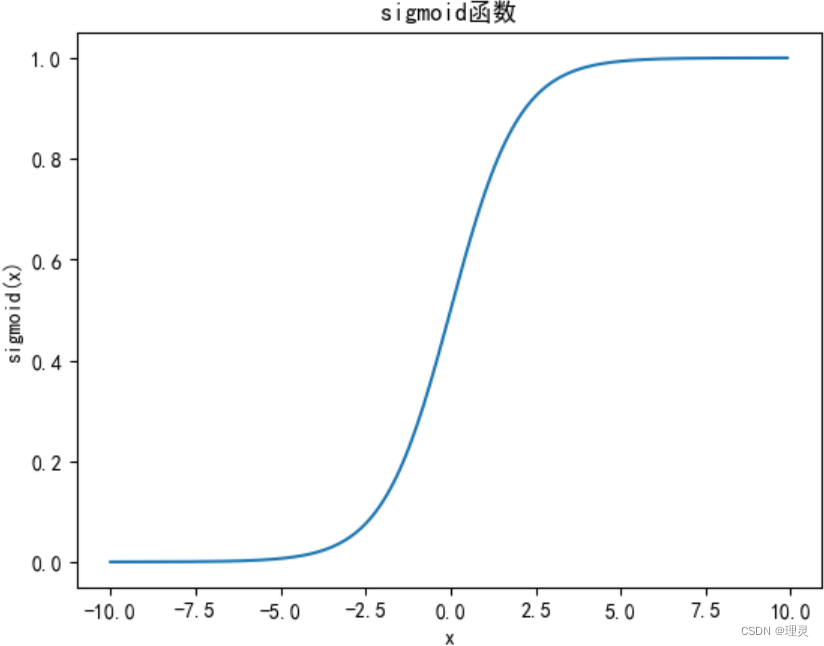
x.grad.data.zero_()
# 在PyTorch中,.grad.data.zero_()与.grad.zero_()将梯度清零
# .grad.data.zero_()在.grad.data上调用zero_()
# 当对一个张量进行求导时,.grad会记录该张量的梯度,.data是指向存储梯度的张量的引用
# .grad.data.zero_()将张量的所有元素设置为零,通常用于清除历史梯度信息,以便进行下一轮的梯度累积或更新权重
# .grad.zero_()在.grad上直接调用zero_()
# .grad是一个张量,记录了张量的梯度信息,zero_()会原地将张量的所有元素设置为零,这意味着不返回新的张量,而直接修改原始张量
y.backward(torch.ones_like(x), retain_graph = True)
plt.title('sigmoid函数梯度')
plt.xlabel('x')
plt.ylabel('grad of sigmoid')
plt.plot(x.detach(), x.grad, )
plt.show()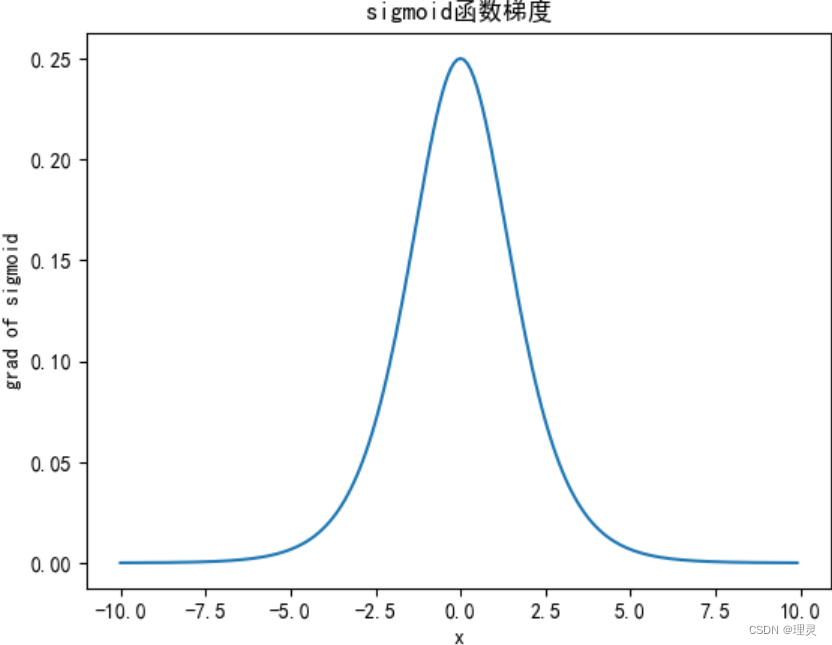
tanh函数
y = torch.tanh(x)
plt.title('tanh函数')
plt.xlabel('x')
plt.ylabel('tanh(x)')
plt.plot(x.detach(), y.detach())
plt.show()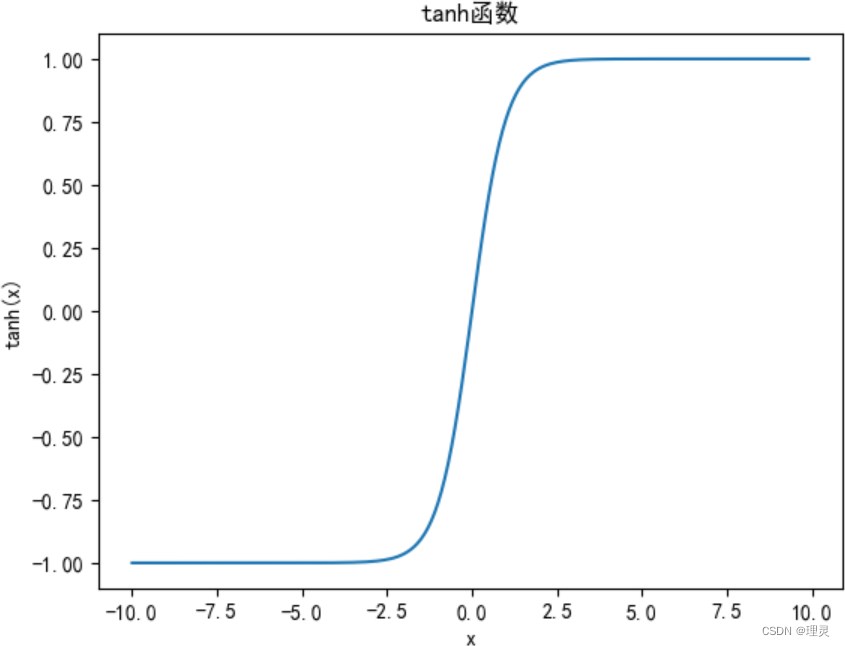
x.grad.data.zero_()
y.backward(torch.ones_like(x), retain_graph = True)
plt.title('tanh函数梯度')
plt.xlabel('x')
plt.ylabel('grad of tanh')
plt.plot(x.detach(), x.grad, )
plt.show()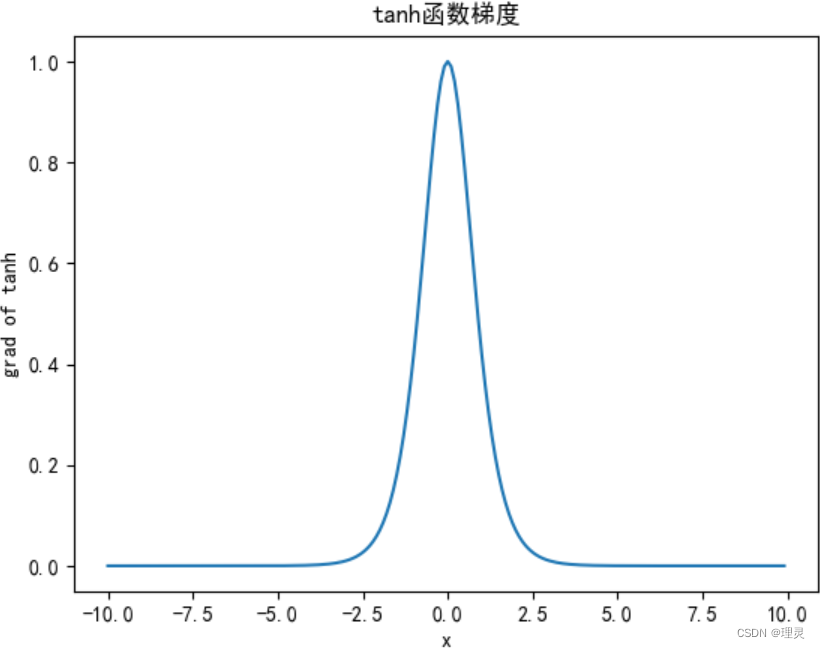















 1277
1277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









