







我们目前学习的都是被打开的文件,文件都在内存之中,那么没有被打开的文件在哪里呢? - - 在磁盘等外设中放着
接下来我们来学习下磁盘中的文件的存储
磁盘的物理结构
磁盘是计算机中常见的存储设备,用于存储和读取数据。它的物理结构由多个关键组件组成,包括盘片、磁头、磁道、扇区和柱面。让我们逐个介绍这些组件及其作用。
-
盘片(Platters):磁盘通常由一个或多个盘片组成,每个盘片都是一个圆形、薄而平坦的金属或玻璃盘。盘片的表面被涂覆上磁性材料,用于存储数据。
-
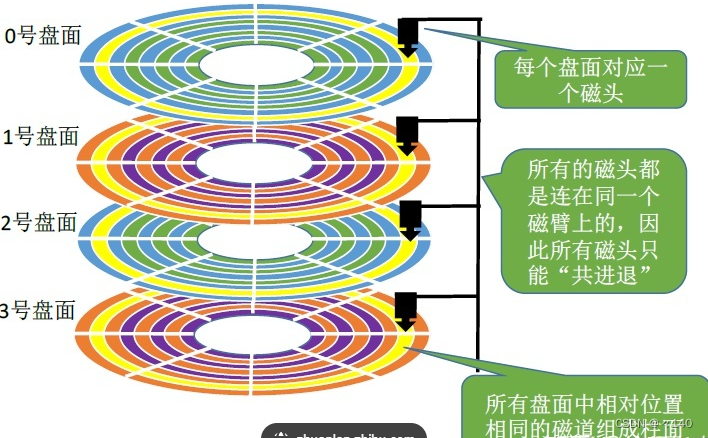
磁头(Read/Write Heads):磁头是位于磁盘上方和下方的电磁设备。每个盘面上都有一个独立的磁头。磁头负责读取和写入数据到磁盘表面。它们可以在不接触盘片的情况下感应和操纵磁场。
-
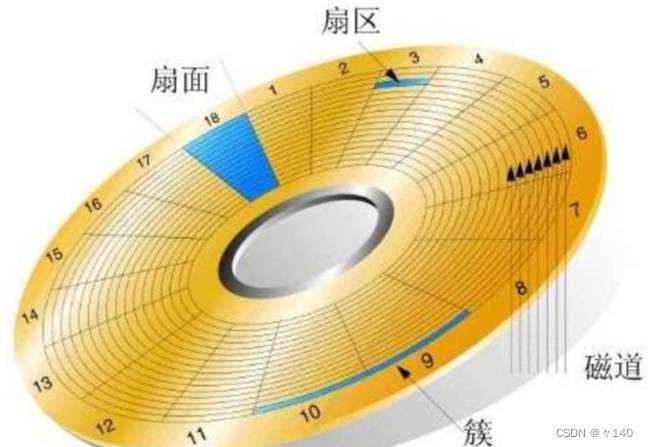
磁道(Tracks):盘片表面被划分为多个同心圆,每个同心圆称为一个磁道。每个磁道上的数据被划分成等长的扇区。磁道号用于标识磁盘上的特定磁道。
-
扇区(Sectors):磁道上的数据被划分为多个扇区,每个扇区都有固定的大小(通常为512字节或4KB)。扇区是磁盘上最小的可寻址单位,操作系统可以直接读取或写入单个扇区。
-
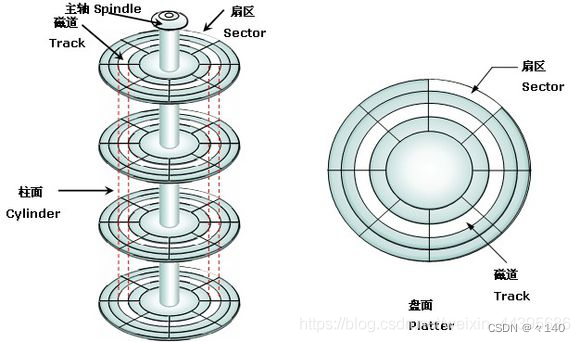
柱面(Cylinders):磁盘的柱面是指位于不同盘片上的相同磁道号的集合。例如,所有盘片上的第10个磁道组成一个柱面。柱面号用于唯一标识磁盘上的特定柱面。
当计算机需要读取或写入数据时,磁头会定位到正确的柱面上,然后移动到目标磁道。一旦到达目标磁道,磁头会等待正确的扇区旋转到磁头下方,然后进行数据的读取或写入操作。
上述介绍是基于传统的机械硬盘(HDD)的物理结构。现代固态硬盘(SSD)采用了不同的工作原理,没有盘片、磁头和旋转机制,因此其物理结构与传统机械硬盘有所不同。
磁头 - - 一面一个磁头,一个磁头负责一面的读取


磁头可以通过马达转的,所有磁头一起转动,读取盘片上的数据
磁头和盘面是挨着的,没有接触,两者距离极近,但是还有一点点
的距离

盘片上都是由磁铁构成的,这些磁铁由南极北极,硬盘就是由南极北极来表示0和1的,所以我们向磁盘写入就是给磁盘做磁化,由N -> S,删除数据就是S -> N
对数据写入和读取根本上就是改变其南北极,读取南北极
磁盘的存储结构
磁盘的物理存储结构
磁盘中存储的基本单元:扇区(512字节或4kb,一般所有扇区都是512字节)
同半径的所有扇区(sector) 构成了磁道,所有面的同半径的磁道构成了柱面(cylinder)
我们定位一个扇区的步骤:CHS定位法(H-head[磁道],C-cylinder[柱面],S-sector[扇区])
- 先定位在哪个面,确定了哪个磁头读取就可以确定在哪个面
- 再定位在哪一个磁道 - - 半径决定
- 在确定在该磁道,在哪一个扇区 - - 根据扇区的编号,定位一个扇区
一个普通文件内容是属性和数据,在二进制中都是0和1,就是占用一个或者多个扇区,来存储数据的
我们现在知道了可以用CHS来定位一个扇区,所以操作系统是直接使用CHS地址的吗? - - 不是的
- 因为如果你换了一个新硬盘,那么操作系统不是也要跟着改变吗?而且操作系统要和硬件做好解耦合,所以不能直接使用CHS地址
- 扇区512字节,每次IO的数据很小,OS进行IO的基本单位是4kb(可调),操作系统一次会操作8个扇区,磁盘也是块设备,操作系统需要一套新的地址来操作块设备

磁带,已经是很久远的东西了,现在应该没有了,我小时候玩过,我们可以借助磁带来理解,磁带现在卷起了一圈一圈的,我们可以认为就是磁盘,扇区,我们将磁带拉出来,这时候就由圆的变成线性的了,我们可以将磁道”拉出来“,逻辑抽象成线性的结构

我们将一个扇面的所有磁道拉出来,这样我们可以看作是一个数组,数组元素是一个个扇区,数组有下标,我们就可以通过数组下标定位一个扇区了
操作系统是以4kb为单位进行IO的,所以,一个OS级别的文件块要包括8个扇区,在操作系统角度是不关心扇区的
就比如说一个int类型,访问一个int类型一次就是4个字节,我们知道一个int类型的变量的首地址,我们就可以用偏移量来访问这个变量,同样,OS要对文件进行IO的时候,只要知道这个这个8个扇区的第一个扇区首地址,再加上偏移量就可以访问这8个扇区的内容,这是块类型,我们可以将数据块看作一个类型

我们可以将一个块(8个扇区组成)看作一个基本单位,这样组成的数组,我们可以通过下标N来表示一个块,我们可以通过下标来定位任意一个块了,这样我们就可以得到OS->N->LBA(逻辑块地址),所以经过我们的逻辑抽象,我们只要让LBA和CHS互相转换,就可以得到一个块地址了,所以操作系统对磁盘的管理变成了对数组的管理,这是先描述在组织
磁盘虽然非常大,但是在OS系统看来,都是块,都是在磁盘上,所以我们分区管理,只要管好一个区,其他区也这样管,那么就所有都管好了,但是一个区还是太大了,不好管,我们再分组,分成一个个组之后,我们只需要研究怎么管好一个组,就可以管理好磁盘了
以上的推导的核心就是管理好组,我们就是要学会组的管理就行了
组
-
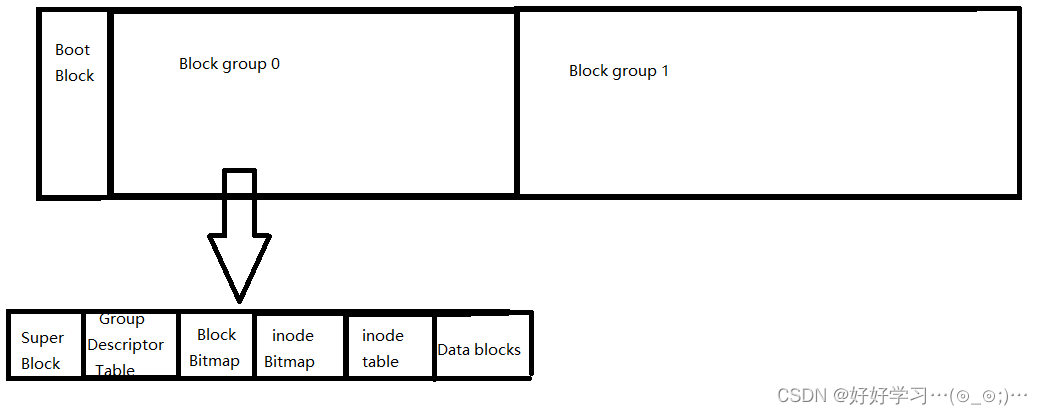
启动块(Boot Block):一个分区的最开始的位置,保存与操作系统启动相关的内容,如分区表,操作系统镜像的地址
-
Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。政府管理各区的例子
-
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。
Super Block的信息被破坏,可以说整个分区就被破坏了。所以super block很重要,因此在每个组里可能都会存在,并且是一起更新内容的,如果一个坏掉了,那么会去其他组里找没有坏掉了,将完好的super block覆盖过来
-
组描述符(GDT - Group Descriptor Table):描述块组属性信息
-
块位图(Block Bitmap):Block Bitmap中每个比特位记录着0或1,1表示Data Block中已经被占用,0表示数据块没有被占用
-
inode位图(inode Bitmap):每个比特位表示一个inode是否可以被使用,1表示一个inode已被使用,0表示未被使用。
-
inode表(inode table):存放所有inode节点
- inode:一个文件内部所有属性的集合,一个文件对应一个inode,一个inode128字节,存放文件属性 如 文件大小,所有者,最近修改等
在Linux下查找文件,要先找到inode,然后通过inode找到Data blocks,所以inode和Data blocks是存在映射关系的
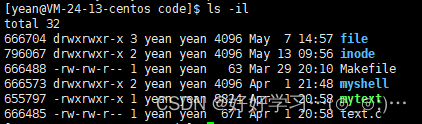
第一列数字就是inode,我们在输入ls命令的时候,只要加上-i选项就可以查看文件的inode -
数据区(Data blocks):存放文件内容,一个Data bolcks占4kb,整个块中大部分内容都是Data blocks
磁盘中的文件
Linux下,OS只认识inode,不认识文件名,文件名是给用户用的,文件的inode里面没有文件名,在目录的Data blocks里才有文件的文件名
深刻认识一下目录
目录也是文件,有inode,任何一个文件一定在目录中,目录的数据块里存放的是该目录下文件名和文件inode编号对应的映射关系,在目录内,文件名和inode互为key值
我们来解读一下命令cat log.text的过程
首先我们找到log.text所在的目录,然后在该目录下根据文件名对应区得到该文件的inode值,然后找到该inode所对应的区,再找到对应的组,然后在组中找到inode表,在inode表中找到文件的inode节点,找到了文件的inode节点就可以通过文件的inode节点找到文件的Data blocks,就可以将文件的内容加载到内存,然后打印到显示器了
文件的增删查改
-
增
创建一个文件,首先一定是在一个目录下创建,然后目录所处的分组当中,找到inode bitmap,然在inode bitmap中从低到高找到一个为0的比特位,将该比特位置1,然后就得到了对应的inode值,用该inode值在inode table中找到inode节点,然后填入该文件的属性,然后再用文件inode值再目录的Data blocks中加入文件inode值和文件名的映射关系,这样一个文件就创建好了 -
删
我们解读了命令cat log.text,大家知道了找文件的过程,想必有人会想,是不是删文件就是在inode表找到文件的inode节点,然后对应Data blocks,再将文件的Data blocks清0实际上并不是这样,这样太慢了,我们在用Windows的时候,大家应该都试过拷贝文件和删除文件,想必都知道拷贝一个文件很慢,但是删除一个文件特别快,如果是向刚刚那样操作来删除文件,那么删除文件不是和找文件一样慢吗,甚至更慢
在Linux下删除文件,首先根据文件名在该文件的目录的Data blocks下用文件名去找该文件的inode值,然后根据inode值在inode bitmap和block bitmap中将对应的比特位设置为0,这样该文件就被删除了
-
查
我们解读cat log.text的时候就是查文件的过程 -
改
改就是先查文件,找到文件的Data blocks然后修改
软硬链接
软链接和硬链接是操作系统中用于创建文件链接的两种不同方式。它们允许在不同的位置创建指向同一文件的链接,从而可以在多个位置访问和操作同一个文件。
-
软链接(Symbolic Link):
- 软链接是一个指向文件或目录的特殊文件。它创建了一个新的文件,其中包含了指向源文件或目录的路径。软链接文件本身只包含源文件的路径信息,不实际存储文件数据。
- 软链接可以跨越不同的文件系统,可以链接到文件或目录。软链接可以在文件系统中的任何位置创建,可以链接到不存在的文件或目录。
- 删除软链接不会影响源文件本身,但如果删除源文件,则软链接将指向一个不存在的目标。
-
硬链接(Hard Link):
- 硬链接是使用同一个索引节点(inode)来创建一个文件的多个链接。索引节点是操作系统内部用于跟踪文件元数据和数据块的数据结构。
- 硬链接与原始文件具有相同的文件名和文件内容。无论通过哪个链接修改文件内容,所有链接都会反映出修改后的内容。
- 硬链接只能在同一个文件系统中创建,并且不能链接到目录。硬链接不能跨越文件系统边界,因为每个文件系统都有自己独立的索引节点。
-
区别:
- 软链接相对于硬链接更加灵活,因为它可以跨越文件系统边界,并且可以链接到目录。软链接允许创建指向目录的链接,使得在不同位置访问同一目录成为可能。
- 硬链接在文件系统中只有一个实际的文件,因此删除任何一个链接都不会影响其他链接或源文件。硬链接常用于创建文件的备份或在系统中创建多个访问入口。
- 软链接的路径可以是相对路径或绝对路径,而硬链接的路径必须是相对路径,因为它们都与源文件位于同一个文件系统中。
总结起来,软链接和硬链接都是用于创建文件链接的方式。软链接是一个指向源文件或目录路径的特殊文件,而硬链接是使用相同索引节点的多个文件链接。软链接可以跨越文件系统边界和链接到目录,而硬链接只能在同一文件系统中创建。软链接更加灵活,而硬链接更加稳定。每种链接类型都有各自的应用场景,根据需求选择适当的链接类型。
软链接
类比理解,软链接就是指针,但是不可以混为一谈
- 软链接生成的文件是独立于原文件的
- 软链接内容的放着的时所指向的文件的路径
输入命令ln -s 文件名 形成的软链接文件的文件名就可以创建软链接文件了
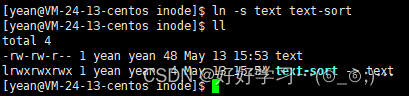
我们可以看到,文件类型以l开头,表示link链接文件
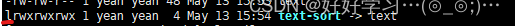
我们cat查看文件内容,照样可以看到
我们vim进去也可以看到文件内容确实是这些
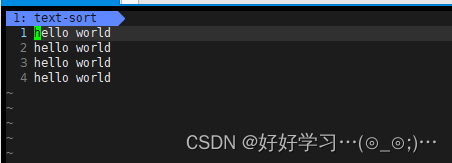
我们可以看到text和text的软链接文件的inode值不一样,表示text和text的软链接文件时两个不同的文件,独立的文件,text的软链接文件有着自己的属性和内容

软链接内容的放着的时所指向的文件的路径
软链接就类似windows下的快捷方式,我们在windows下的软件经常创建快捷方式放到电脑桌面上,然后双击即可访问,实际上不就是软件的软链接吗
硬链接
类比理解,硬链接就像是浅拷贝,原文件的引用,但是不可以混为一谈
- 硬链接生成的文件和原文件共用同一个inode节点,也就是说两者是同一个文件,只不过文件名不一样
命令行输入ln 文件名 想要形成硬链接文件的文件名

硬链接文件创建好了,我们可以看出和软链接文件有很大的不同,首先硬链接文件和原文件的inode值时一样的,还有创建完硬链接文件后原文件的第三列数字由1变成了2 (第三列数字叫做硬链接数)
硬链接数就是引用计数,表示有几个文件名指向inode节点,只有硬链接数为0,对应文件的才真正被删除
硬链接和目标文件共用同一个inode编号,硬链接和目标文件共用同一个inode节点,表示硬链接并不是一个独立的文件
硬链接实际时做了一件事,得到原文件的inode,然后在该文件所在的目录的Data blocks下增加一个该inode与硬链接文件名的映射关系
我们将原文件删除的时候,硬链接文件照样可以正常使用,而软链接文件不能使用
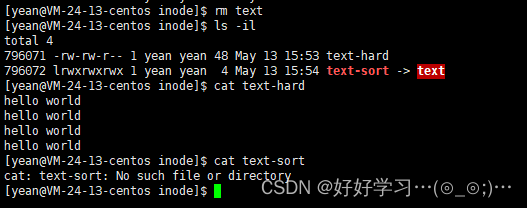
目录的硬链接
- 目录里面的隐藏文件.是目录自己的硬连接,…是上级目录的硬连接
- OS不允许用户创建目录的硬连接
我们创建一个新目录,我们可以发现新目录的硬链接数一开始就是2
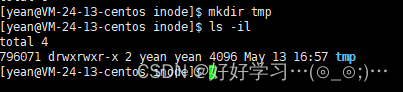
首先我们可以推断,目录是文件,有自己的inode,所以其中一个肯定是目录自己,但是另一个文件时谁?
我们记住目录的inode值796071,再进入目录里看看
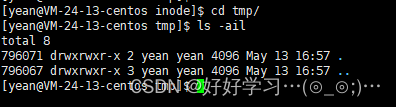
我们可以看到我们创建的新目录下有两个隐藏文件.和…,而且.的inode和我们创建的tmp目录的inode时一样的,这下找到了另一个文件
以前我们一直都说.代表的时当前路径,现在我们知道为什么了,.就是当前目录的硬链接,…是上级路径,也就是上级目录的硬链接
我们可以看到我们当前路径是/home/yean/code/inode/tmp,tmp目录下只有.和…,上级目录inode下只有tmp和.和…,inode目录的硬链接数为3,一个是inode目录文件自己,一个是inode目录文件里的.,另一个是inode目录文件里面的tmp目录文件里面的…
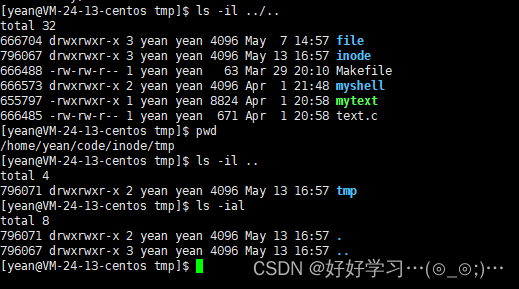
所以我们通过目录的硬链接数,就可以算出该目录下的目录数量为该目录的硬链接数减2
这个公式想必大家可能会怀疑是否正确,因为可能有人会想既然创建一个目录之后,会自动再该目录下创建.和…,一个该目录的硬链接,一个上级目录的硬链接
那我不是可以自己给目录创建一个硬链接,其实不可以的,OS并没有放出这个接口供我们使用,我们想想不让我们自己给目录创建硬链接也是正常,因为我们知道Linux下所有目录构成了一个多叉树,如果我们随意的创建目录的硬链接,那么这个多叉树的结构就可能形成环路,那么就出问题了,所以OS是不允许用户给目录创建硬链接的,所以该公式是正确的
stat查看三个和文件相关的时间
- Access:最后访问时间
- Modify:文件内容最后修改的时间
- Change:属性最后修改的时间
以前的Linux是每次访问之后都会更新Access,但是查询文件时最频繁操作,所以每次访问文件都要更新时间就要进行的IO次数太多,浪费太多时间,所以现在的版本下,一般时访问几次后才会更新Access,Modify和Change每次修改都会更新

















 2572
2572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









