






一、理论知识
1.什么是支持向量机(SVM)
线性支持向量机(Linear Support Vector Machine,简称线性SVM)是一种常用的机器学习算法,用于二分类和多分类问题。它的目标是找到一个最优的超平面,将不同类别的样本分隔开来,并尽可能地使两个类别之间的间隔最大化。
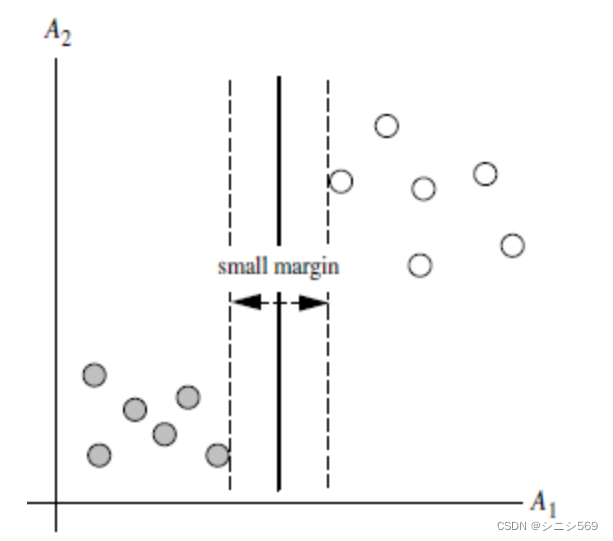
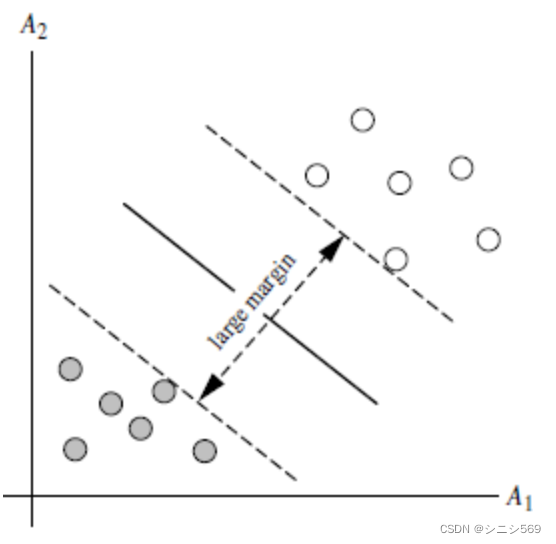
图二确定的直线与样本点的距离更近,间隔更大,所以更好。
2.什么是支持向量
支持向量是指在支持向量机(SVM)算法中,被划分为不同类别的数据点中,离分类超平面最近的一些点。这些点被称为支持向量,因为它们对于分类超平面的位置和方向起到了重要的支持作用。

二、代码实现
1.导入基本库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
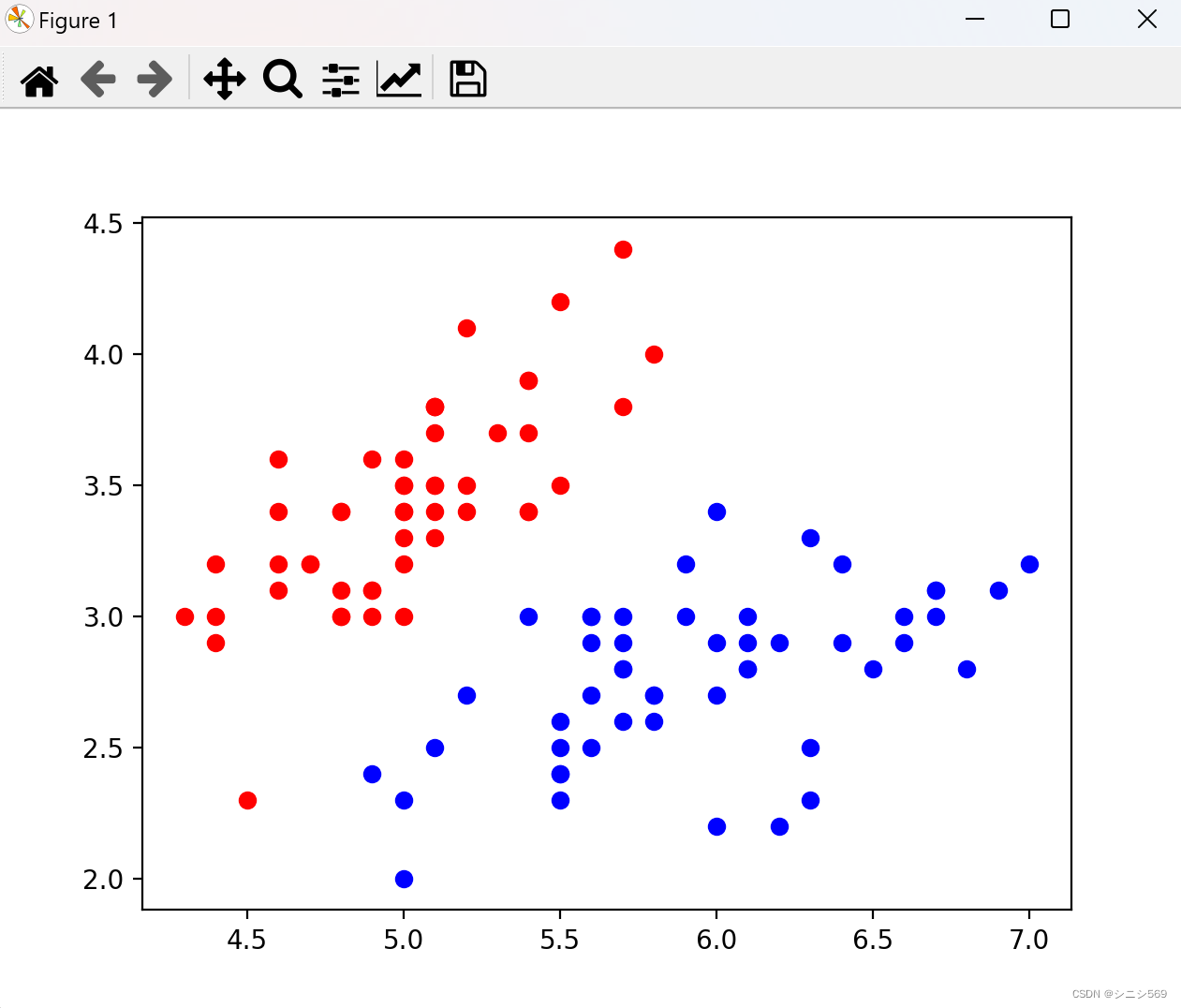
2.选取鸢尾花的两个特征
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X [y<2,:2] #只取y<2的类别,也就是0 1 并且只取前两个特征
y = y[y<2] # 只取y<2的类别
# 分别画出类别0和1的点
plt.scatter(X[y==0,0],X[y==0,1],color='red')
plt.scatter(X[y==1,0],X[y==1,1],color='blue')
plt.show()
可视化结果展示:
3.训练SVM数据
# 标准化
standardScaler = StandardScaler()
standardScaler.fit(X) #计算训练数据的均值和方差
X_standard = standardScaler.transform(X) #再用scaler中的均值和方差来转换X,使X标准化
svc = LinearSVC(C=1e9) #线性SVM分类器
svc.fit(X_standard,y) # 训练svm
使用StandardScaler对特征进行标准化处理,使得特征具有零均值和单位方差。这有助于提高模型的性能和收敛速度。
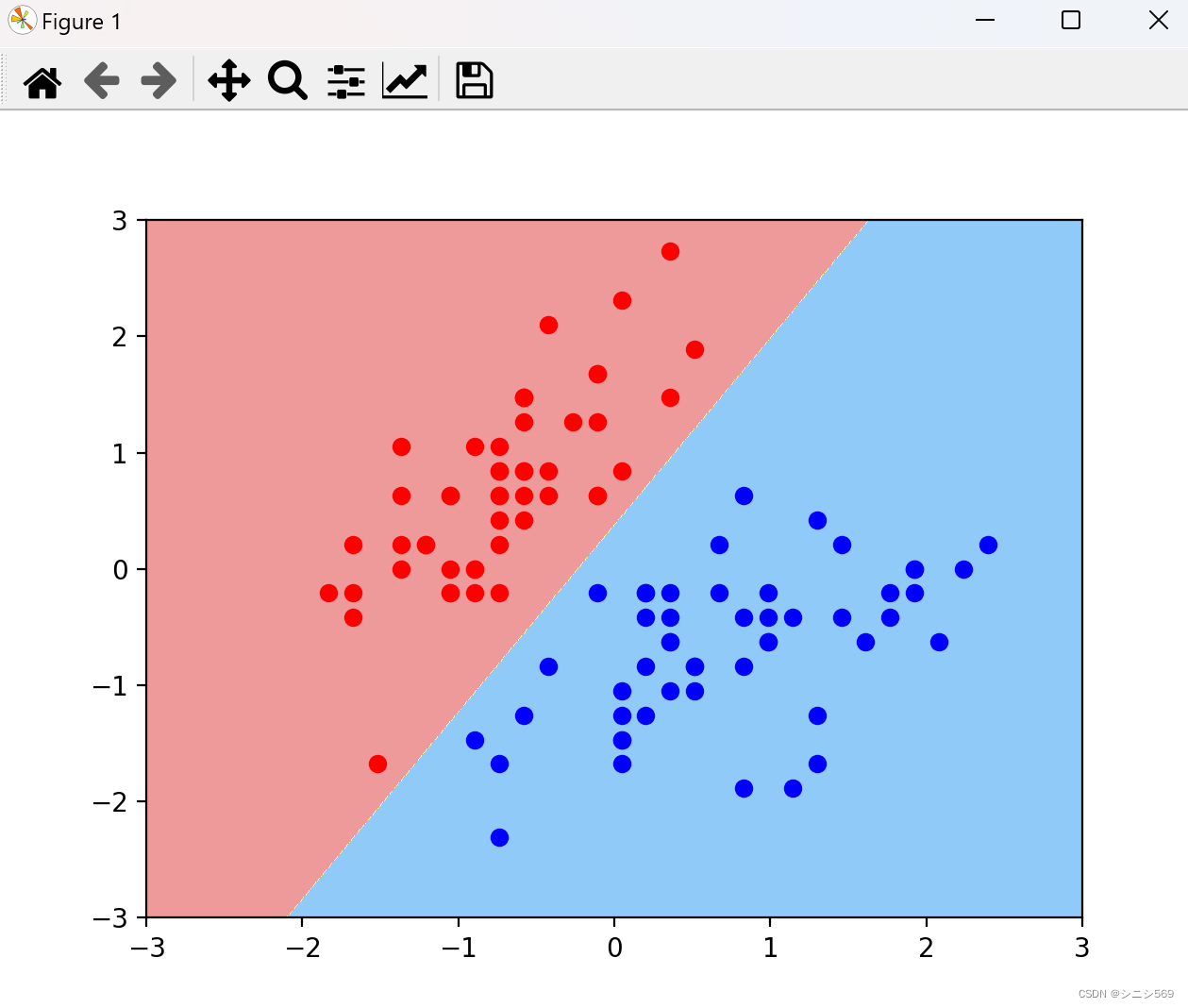
4.决策边界函数
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
# 绘制决策边界
plot_decision_boundary(svc,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
可视化结果展示:
5.调参数C
svc2 = LinearSVC(C=0.05)
svc2.fit(X_standard,y)
plot_decision_boundary(svc2,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
在支持向量机中,C参数用于调整正则化的强度。正则化是一种用于控制模型复杂度的技术,它可以帮助防止过拟合。 较小的C值会导致更强的正则化,使得模型更趋向于选择边界简单的分类器。较大的C值会降低正则化的强度,使得模型更趋向于选择更复杂的分类器。
C值为0.05时:
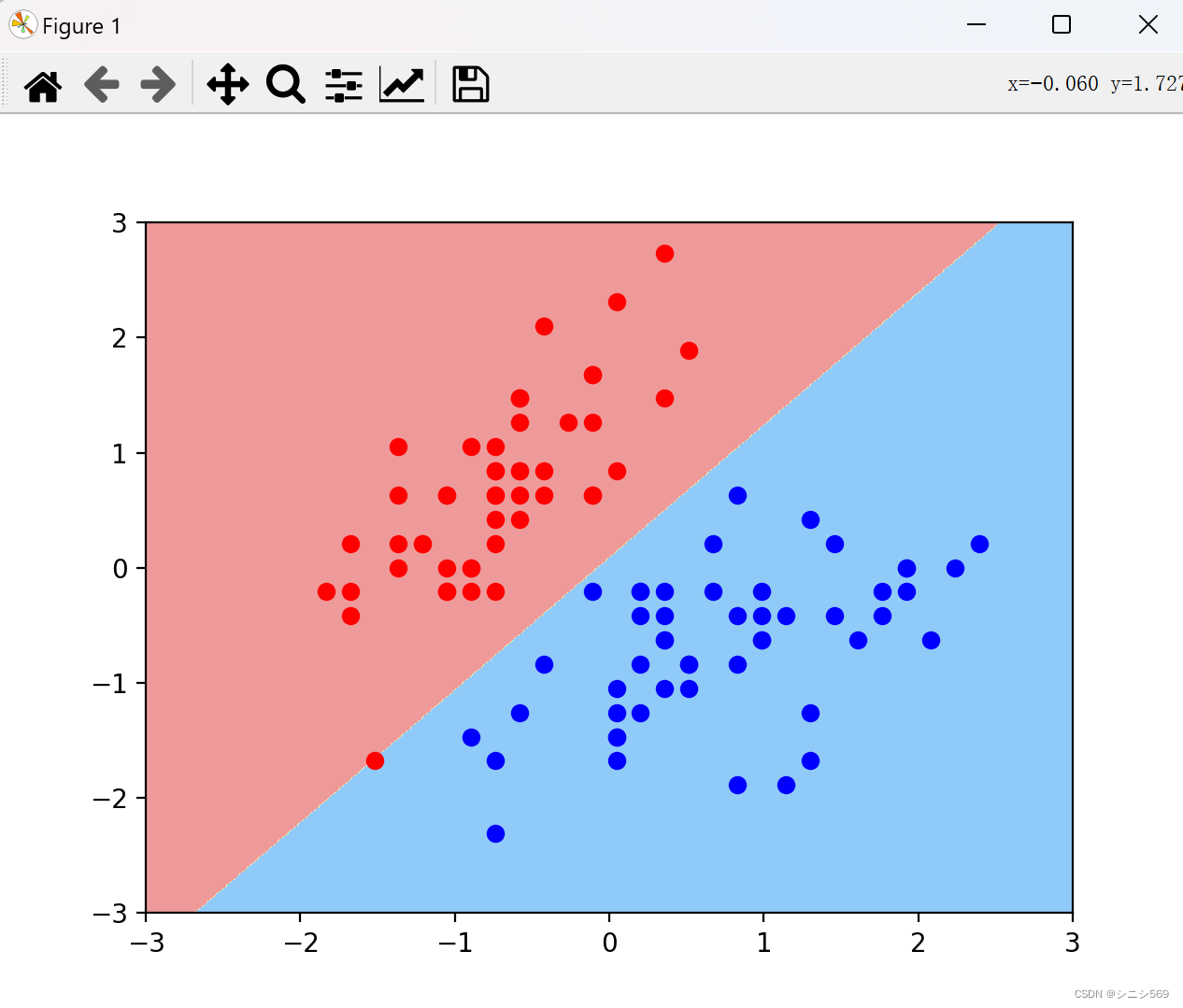
C值为100000时:
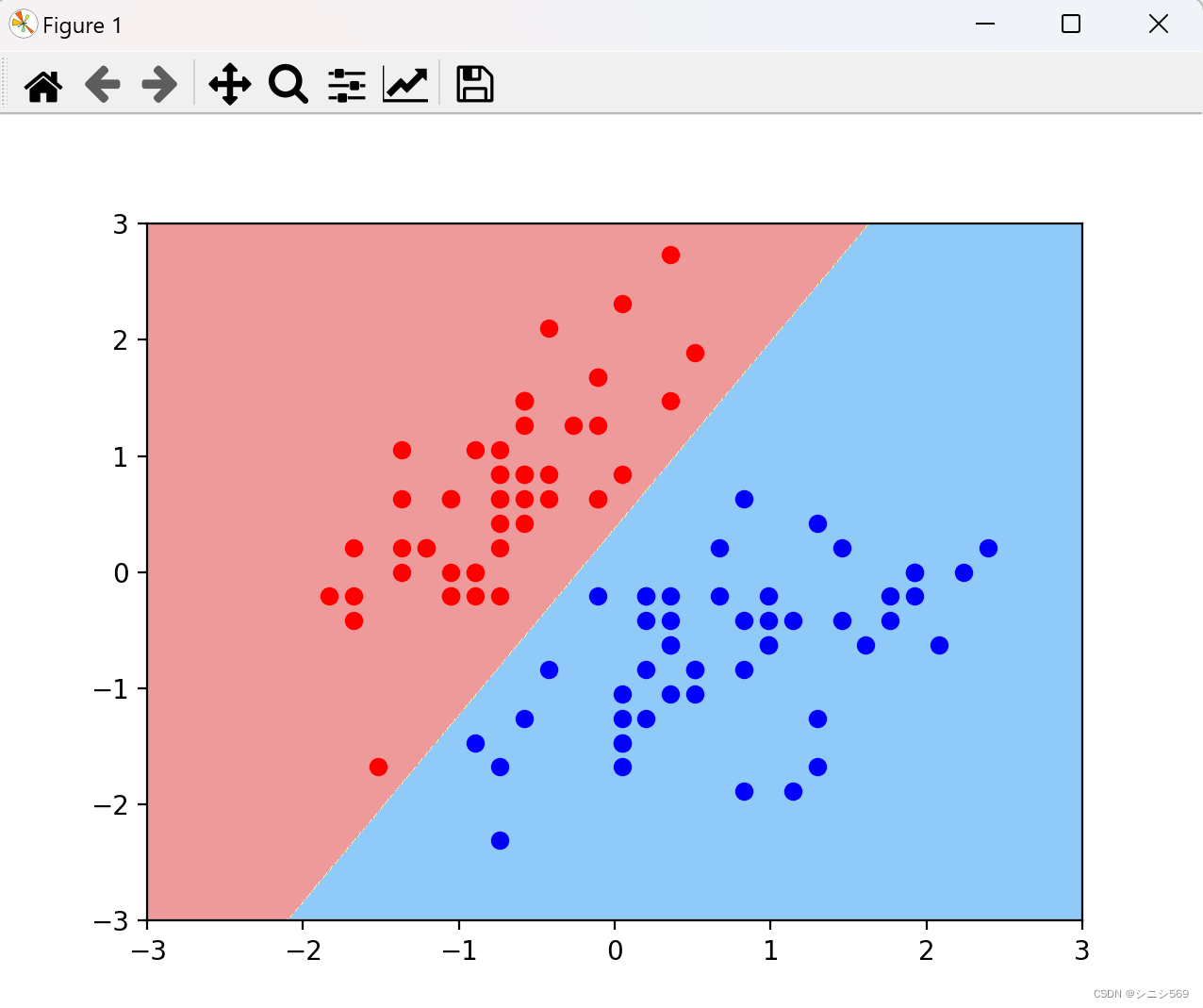
实验结论:很明显的看到和第一个决策边界的不同,在第一个决策边界汇总,有一个红点是分类错误的。
这可证得:C值越小容错空间越大,越容易出现错误。
三、总结
- SVM是一种强大的机器学习算法,特别适用于具有明显类别间隔的数据集。
- 核函数的选择取决于数据的线性可分性,线性核适用于线性问题,而非线性核适用于更复杂的数据结构。
- 参数C的调整可以平衡模型的复杂度和错误惩罚,需要根据具体问题进行优化。
- 可视化工具(如matplotlib)可以更好地理解模型的决策过程和性能。
通过这个实验,不仅可以学习如何使用SVM进行分类,还理解了数据预处理和参数调整的重要性。 此外,还进一步认识了到在实际应用中需要平衡模型的复杂度和泛化能力,以避免过拟合或欠拟合的问题。















 2364
2364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









