






目录
一、理论准备
1.PCA的作用
最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。
PCA可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。主成分能够尽可能保留原始数据的信息。
2.PCA的步骤
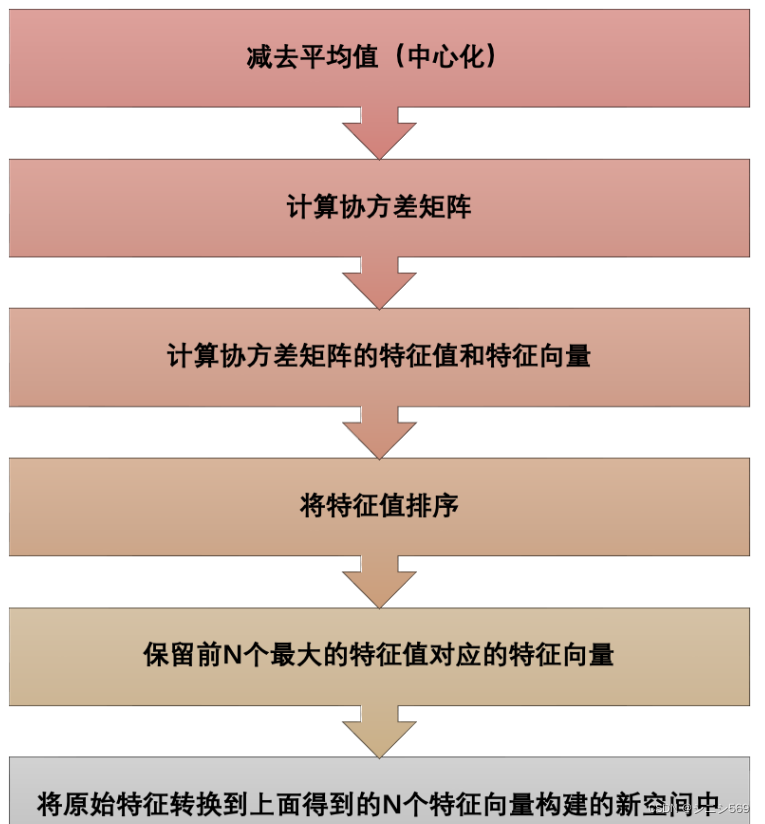
二、源码
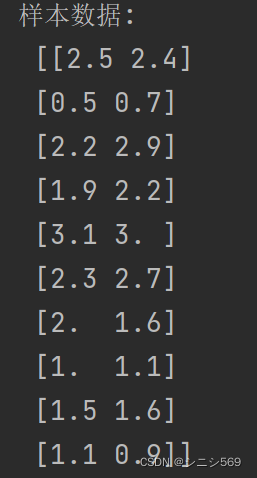
1.数据准备
x = np.array([[2.5, 0.5, 2.2, 1.9, 3.1, 2.3, 2, 1, 1.5, 1.1],
[2.4, 0.7, 2.9, 2.2, 3.0, 2.7, 1.6, 1.1, 1.6, 0.9]])
x = x.T # 输入数据,样本数为10,特征数为2;行数为样本数,列数是特征数输出结果:
2.数据中心化
# -----按列中心化-----#
raw = len(x) # 行数
col = len(x[0]) # 列数
x_new = x - np.mean(x, axis=0)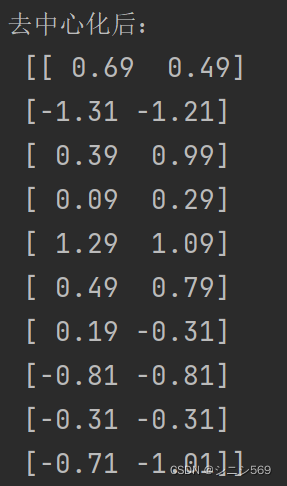
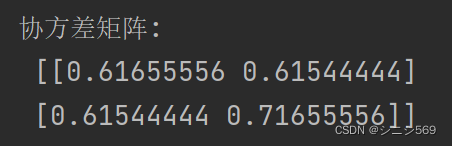
3.协方差矩阵
# -----求协方差矩阵-----#
x_cov = np.cov(x_new.T) # Python里cov()函数是按照行向量来计算协方差的
print('协方差矩阵:\n', x_cov)输出结果:
4.特征矩阵和特征向量
# -----求协方差矩阵的特征值和特征向量
feature_value, feature_vector = np.linalg.eig(x_cov) # 由特征值、特征向量组成的元组,第一个元素是特征值,第二个是特征量
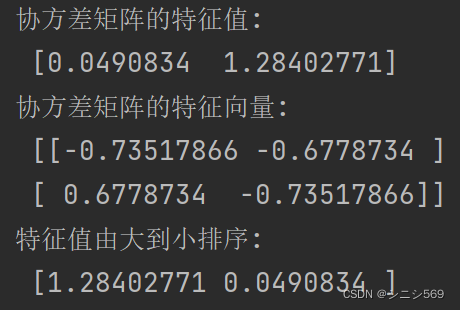
print('协方差矩阵的特征值:\n', feature_value)
print('协方差矩阵的特征向量:\n', feature_vector)
# -----特征值由大到小排序-----#
index = np.argsort(feature_value)[::-1] # 获取特征值从大到小排序前的索引
feature_value_sort = feature_value[index] # 特征值由大到小排序
feature_vector_sort = feature_vector[:, index] # 特征向量按照特征值的顺序排列
print('特征值由大到小排序:\n', feature_value_sort)输出结果:
5.得到降维后数据
for i in range(len(feature_value_sort)):
if sum(feature_value_sort[0:i + 1]) / np.sum(feature_value_sort) > 0.9: # 累积贡献率大于90%的主成分
k = i + 1 # 主成分个数
break
main_component = feature_vector_sort[:, 0:k] # k维向量
# -----将样本点映射到k维向量上-----#
final_data = np.dot(x_new, main_component) # n维数据变成k维数据
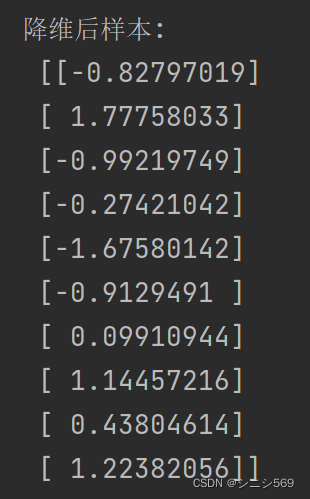
print('降维后样本:\n', final_data)输出结果:
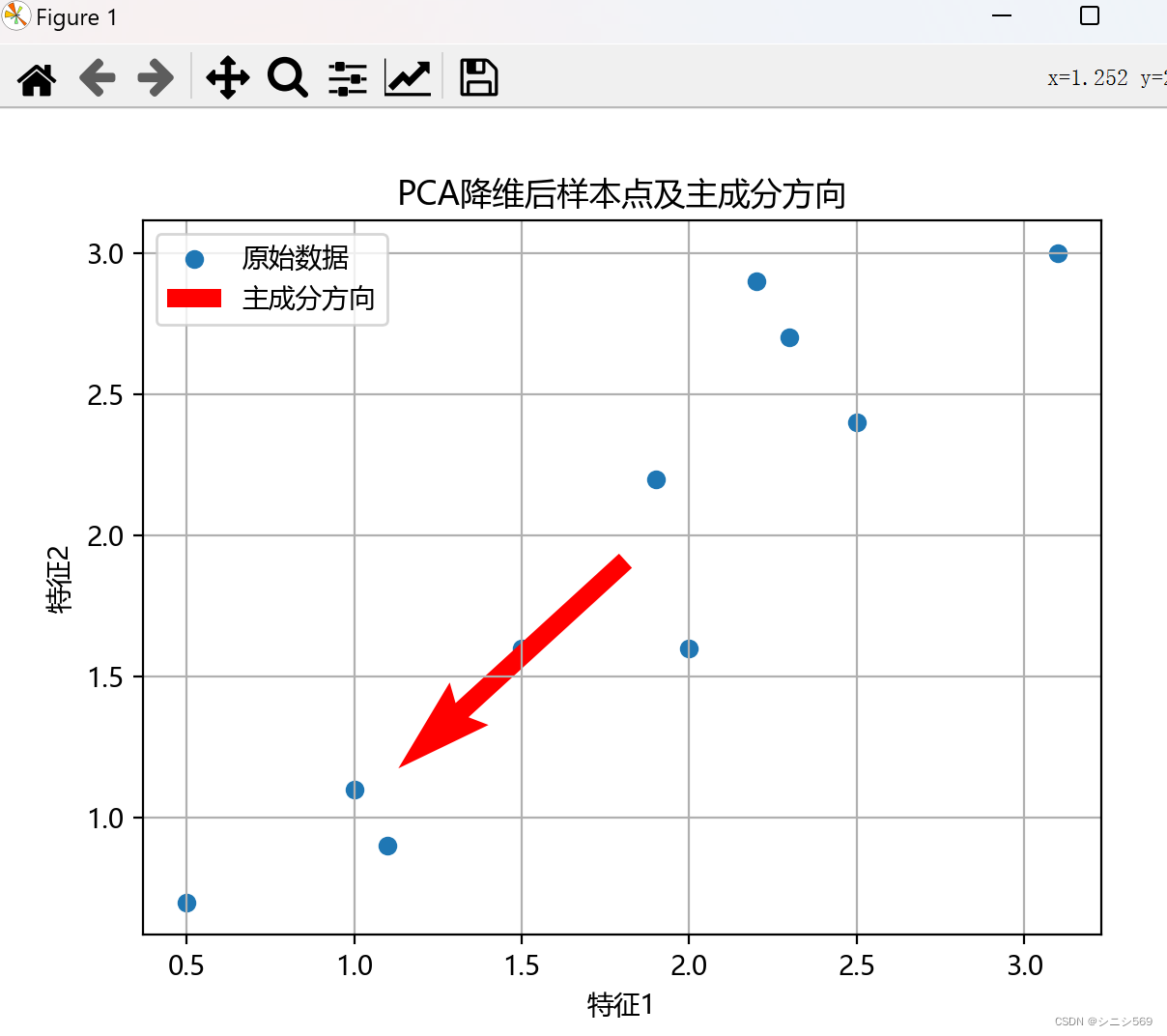
6.可视化结果
三、总结
通过本次PCA降维实验,学习了PCA的基本理论和方法,掌握了如何实现PCA降维,并了解了在实际应用中可能遇到的问题和解决方案。
代码实现中的错误:在编写PCA算法的代码实现时,可能会遇到索引错误、维度不匹配等问题。这要求仔细检查代码并进行调试。
性能考量:对于大规模数据集,PCA的计算可能会很耗时,特别是特征值和特征向量的计算。这可能需要使用更高效的算法或并行计算。















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









