







梯度消失/梯度爆炸的解决方案
首先,梯度消失与梯度爆炸的根本原因是基于bp的反向传播算法

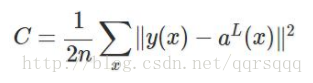


且上述的反向传播错误小于1/4
总的来说就是,更新w和b的时候,更新的步长与learningrate成正比,当所处的层数越浅,每层的w的值和反向传播错误的值乘的愈多,导致w和b更新的步长收到很大影响,最终导致梯度爆炸或者梯度消失。这时候深度网络并不能比千层网络性能好。后面基层学习情况好,而浅层网络则学不到东西。sigmoid网络中存在指数级的梯度消失。
策略大概有以下几种。
每层网络以不同的学习率进行学习
更换激活函数
使用relu激活函数,简化计算,且解决梯度消失问题,并且一部分神经元输出为0,可以使网络具有稀疏性,减少参数的依存关系,缓解过拟合的发生。
使用batch normolization
训练网络前需要对数据做归一化处理。用处在于:神经网络本质是学习数据分布,如果寻来你数据与测试数据分布不同,网络的泛化能力将降低,且在每一批训练数据不同的情况下,网络的训练速度会降低。
batch normolization可以解决梯度消失问题,使得不同层不同scale的权重变化整体步调更一致,也可以加快训练速度。放在每一层网络的非线性映射前,即放在激活函数之前。
局部最优解怎么办
模拟退火
加入momentum项
不收敛怎么回事,怎么解决
数据太少
learningrate过大
可能导致从一开始就不收敛,每一层的w都很大,或者跑着跑着loss突然变得很大(一般是因为网络的前面使用relu作为激活函数而最后一层使用softmax作为分类的函数导致)
网络结构不好
更换其他的最优化算法
我做试验的时候遇到过一次,adam不收敛,用最简单的sgd收敛了。。具体原因不详
对参数做归一化
就是将输入归一化到均值为0方差为1然后使用BN等
初始化
改一种初始化的方案
过拟合
增加训练集的数据量
图像的话可以平移反转加噪声
使用relu激活函数
dropout
每次迭代训练随机选取一部分节点进行训练和权重更新,另一部分权重保持不变。在测试时,使用mean network网络获得输出。
正则化
也是为了简化网络,加入l2范数
提前终止训练
怎样提升效果?/或许有欠拟合
增加特征数量
本来输入只有坐标位置,欠拟合后再增加一个颜色特征
减少正则化项的参数
参数初始化的研究
http://m.blog.csdn.net/shwan_ma/article/details/76257967















 1769
1769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









