







【引言】
最近,不少开发者在社区里吐槽:“怎么市面上量化版本五花八门,Q2、Q4_0、Q4_K_M、Q5_K_M、FP8、UD 系列……眼都花了,该怎么选?”与此同时,也有人抱怨自己只想跑个中小模型,结果显存还是不够,或者速度慢到离谱。实际上,这就是当下 AI 模型量化的典型“纠结”:如何在低比特表示与业务需求之间找到平衡?本篇文章将以 DeepSeek 为例,先梳理各种量化版本的特点,再在量化原理部分深入探讨一些细节,最后用实际示例代码演示如何进行简单的量化流程。
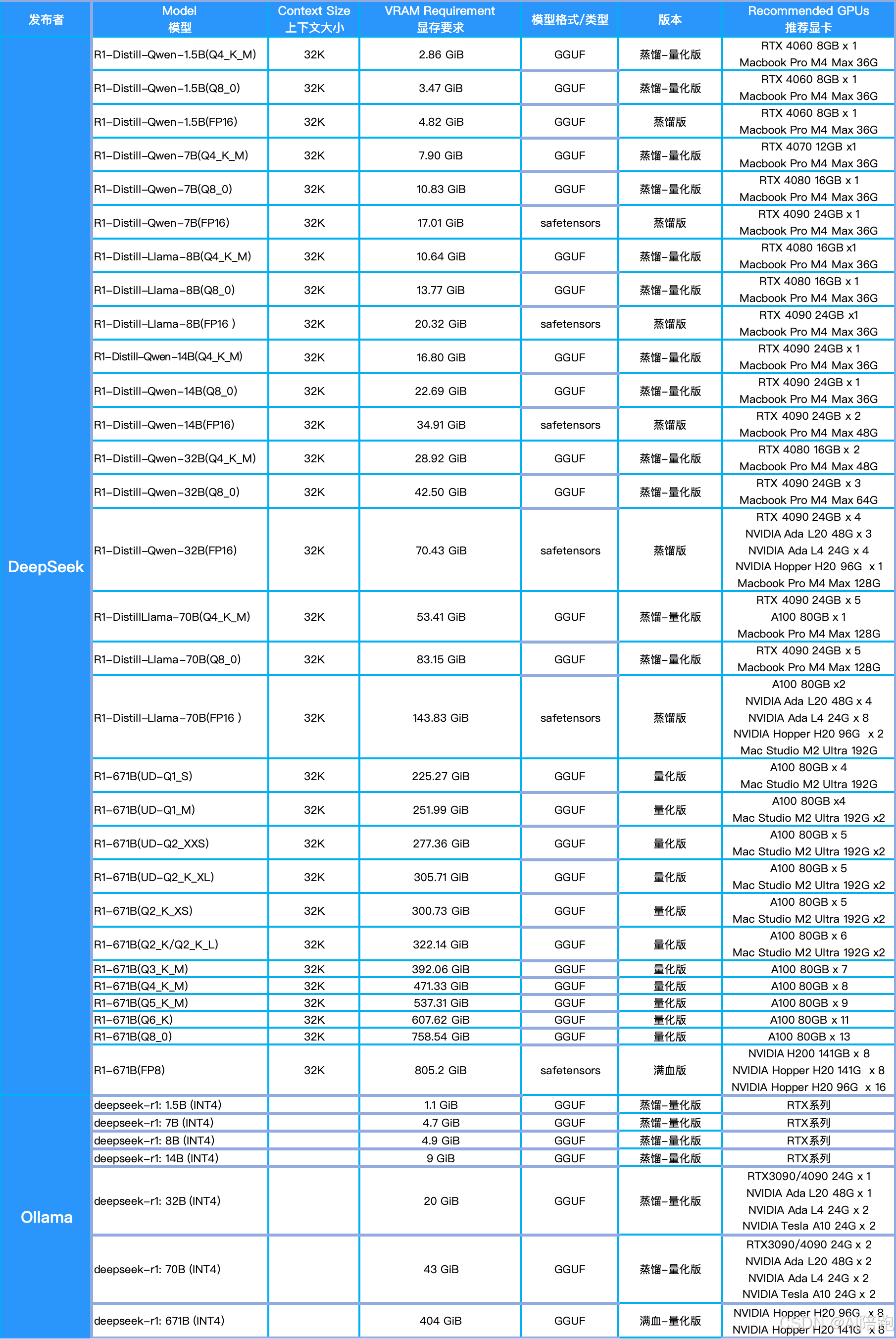
第一章:什么是 DeepSeek 量化?——你可能见过的版本表
DeepSeek 模型的量化版本很多,如果只看名称,很容易看得眼花缭乱。这里先给大家一张简单对照表,帮助入门理解。
| 量化类型 | 位数 | 显存占用(7B模型) | 速度(tokens/s) | 典型特征 |
|---|---|---|---|---|
| Q2 | 2 位整数 | 约 3.2GB | 4 - 6 | 极端压缩比例,对精度有明显影响 |
| Q4_0 | 4 位整数 | 4GB | 6 - 8 | 基础 4 位量化,普适性较高 |
| Q4_K_M | 4 位整数 | 4.5GB | 8 - 10 | 在块量化基础上做优化,精度更稳定 |
| Q5_K_M | 5 位整数 | 5GB | 7 - 9 | 提升精度,牺牲少量显存 |
| FP8 | 8 位浮点 | ~5GB | 10 - 12 | 硬件支持前提下速度快,精度可接受 |
| FP16 | 16 位浮点 | 6GB | 12 - 15 | 原生半精度计算,精度无损,硬件友好 |
| UD 系列 | 动态混合精度 | 3~5GB | 4 - 8 | 根据分布动态调节,硬件适配要求较高 |
之所以出现这么多选择,是因为量化本身是一门“牺牲精度,换取资源与速度”的艺术。同样是 4 位量化,不同的量化方式、块大小和后处理策略,都可能对精度和推理速度造成显著影响。大家在部署 DeepSeek 模型时,需要根据自己的显存、延时、业务容忍度等多维度来做决策。
第二章:量化原理剖析——从浮点到低比特的“瘦身”秘诀
2.1 缩放因子与零点
量化其实就是把原先的高精度浮点数“映射”到一个较小范围的整数。常用的做法是引入 缩放因子(Scale) 和 零点(Zero Point)。其中,
- Scale 决定了“一个整数单位”在浮点数域中对应多少值;
- Zero Point 相当于在整数域里的“基准点”,用来对准浮点域的 0。
比如,对一段浮点权重 [−0.8,0.8][-0.8, 0.8][−0.8,0.8] 进行 4 位对称量化,整数范围为 [−8,7][-8,7][−8,7]。我们可以这样计算:

若是非对称分布(浮点数在 [0, 2.5] 范围),我们可能引入零点让最小值对应整数 0,这样误差会更小。
2.2 对称 vs 非对称
- 对称量化:最常见、实现简单;适用于权重分布较平衡的场景。
- 非对称量化:会多储存一个零点,适合输出有明显偏置的激活数据;能降低量化误差,但实现稍复杂。
2.3 动态范围与直方图截断
在实际应用中,权重或激活数据常常具有一些离群值。为避免离群值拉大量化区间,可以采取 直方图截断 或 KL 散度 校准,让模型的大部分主体分布映射到 integers 里,把极端数据忽略或单独处理。
2.4 量化感知训练 (QAT)
纯推理阶段的量化可能会产生较高误差,因此使用 QAT 思路,在训练过程中就“模拟量化”去更新权重,让模型逐步适应低比特运算。QAT 实践虽复杂,但对高风险行业(如金融、医疗)模型的精度尤为重要。
一个简易的 PyTorch 量化示例
以下是一段简单Python代码,用于演示如何对一个张量进行对称量化和反量化(示例不涉及QAT或网络结构,仅做演示):
import torch
def naive_quantize(x, num_bits=4):
# 1. 找到绝对值最大值
max_val = torch.max(torch.abs(x))
# 2. 计算量化级别
# 对称量化,范围是 [-(2^(num_bits-1)), 2^(num_bits-1)-1]
qmin = -(2**(num_bits-1))
qmax = (2**(num_bits-1)) - 1
# 3. 得到 scale (缩放因子)
scale = max_val / qmax
# 4. 量化
q = torch.round(x / scale)
# 裁剪到合规范围
q = torch.clamp(q, qmin, qmax)
# 5. 反量化
x_dequant = q * scale
return q, x_dequant
# 测试
if __name__ == "__main__":
torch.manual_seed(42)
w = torch.randn(5)
q_vals, x_recovered = naive_quantize(w, num_bits=4)
print("Original:", w)
print("Quantized ints:", q_vals)
print("Recovered:", x_recovered)
这段小脚本让你可以感受一下,原始浮点值被“挤压”成了整数,再通过 scale 恢复到近似的浮点范围,但必然带来一定量化误差。
第三章:DeepSeek常见量化版本——显存与速度如何平衡?
3.1 Q2、Q4_0、Q4_K_M……都在玩什么花样?
- Q2:采用 2 位整数量化,想要的是极限压缩和超低显存占用,但推理速度未必就快,需要硬件对低比特运算有良好支持,且精度可能下滑明显。
- Q4_0:是最普通的 4 位量化,小白也能迅速上手,把显存从 FP16 的 6GB 缩减至 4GB。
- Q4_K_M:相比 Q4_0,多了块量化(Blockwise Quantization)策略,在一定程度上降低量化误差,对提升精度有帮助,但需要更多额外的元信息来存储块统计数据。
3.2 FP8 与 FP16
- FP8:如果你的硬件(如新一代 GPU)原生支持 FP8,那么选择 FP8 会让你在速度、精度、显存占用三者间得到更好的折中。对硬件的依赖是唯一门槛。
- FP16:老牌方案,“满血版”半精度。对于算力资源相对宽裕、对精度要求较高、又想要极致推理速度的场景,仍是主流之选。
3.3 UD(Unified Dynamic)系列
- UD_Q1_S / UD_Q2_XXS 等:这类方法往往在训练或推理时根据激活的分布,动态选择量化级别或者块大小。对底层实现要求较高,如果部署环境能适配,则可获得惊人的显存压缩比。否则可能会带来一系列兼容性问题。
第四章:具体选型与实战心得
很多人纠结“该如何选量化版本”?其实有个简单思路:先看硬件,再看容错,再测速度。
- 硬件限制
- 如果 GPU 显存不高(如消费者常用的 RTX 3060),最好首选 4 位量化(Q4_0 或 Q4_K_M);
- 如果有顶配 GPU 或者专门支持 FP8,那么 FP8 带来的速度和精度都很诱人。
- 容忍度
- 聊天对话场景对精度容忍度相对高,可以优先省显存,改用 4 位甚至 3 位模式;
- 金融、科研需要严谨输出,尽量用 FP16 或 Q5_K_M以上的版本。
- 性能测试
- 不同量化版本在不同框架、不同算力平台下,表现千差万别。最稳妥做法是拉个 Benchmark 手动测。此外,DeepSeek 社区常有人分享测试结果,值得参考。
第五章:一个关于“长夜扛机”的分享
前不久,社区里有位老朋友说,他想把 DeepSeek-7B 用于实时推荐场景,可惜手头只有两块老旧的 2070S 显卡,显存各 8GB。最初用 FP16 跑,结果中途频繁触发 OOM(Out Of Memory)。他尝试了 Q4_0,虽然显存够用,但速度不太理想。
后来换成 Q4_K_M,并调大了 batch size,配合 Flash Attention 优化,终于让系统在忙时也保持每秒 10+ 条推荐请求处理,勉强踩在老板要求的延迟线之下。虽然量化带来的“模型口语化程度”稍有弱化,但总算解决了燃眉之急。那段时间,他天天通宵加班“扛机”,却也收获了宝贵实践经验。
结语:破局之道——拥抱多样量化,驶向真实落地
DeepSeek 量化技术的异彩纷呈,正是行业“降本增效”大潮的真实写照。看似眼花缭乱的量化版本,其实都是力图在精度、速度和硬件资源之间探寻一个“KPI 之上的最优解”。
或许,你在自己项目里也遇到过类似难题:显存不够、速度卡顿、对话系统不够灵活……不妨试试挑一个合适的 DeepSeek 量化版本,多做几次实验,或许就能抓住那条“性能与成本”之间的平衡线。毕竟,真实的生产环境没有绝对的标准答案,只有不断试错和实战积累,才能驾驭量化引擎,跑出属于你的极速之路。
愿每位开发者都能在 DeepSeek 的量化海洋中,发现最适合自己的方向,乘风破浪,一往无前!


















 6175
6175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











