







权重初始化是为了缓解深层神经网络中产生的梯度消失和梯度爆炸问题,加快收敛速率。它主要有以下几种方式。
零值初始化
这是一种非常不可取的初始化方式。因为这样一来,所有的隐藏单元都是一样的(对称性),也就意味着它们计算的是同样的函数,对输出单元有同样的影响。无论经过多少次迭代,所有隐藏单元学习到的内容都是相同的,这样的神经网络效果和简单的线性分类器无异。
随机初始化
随机初始化打破了对称性,效果远优于零值初始化,一般用np.random.randn()方法实现。一般来说,初始化参数不宜过大。
Xavier 初始化
Xavier初始化适用于tanh激活函数,是在随机初始化的基础上再乘上一个参数 n p . s q r t ( 1 n [ l − 1 ] ) np.sqrt(\frac{1}{n^{[l-1]}}) np.sqrt(n[l−1]1)( n [ l − 1 ] n^{[l-1]} n[l−1]是第 l − 1 l-1 l−1层的隐藏单元个数)。
He 初始化
与Xavier初始化类似,He初始化是在随机初始化的基础上乘上 n p . s q r t ( 2 n [ l − 1 ] ) np.sqrt(\frac{2}{n^{[l-1]}}) np.sqrt(n[l−1]2),适用于relu激活函数。
初始化方式不同,训练结果也会有很大的不同。
以下是三种初始化方式应用于一个3层神经网络上的效果,可以看到准确率的差异是很大的。
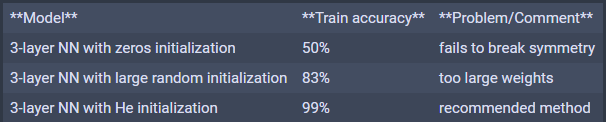
(来源:吴恩达深度学习课程作业)















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









