







一、全0初始化
全0初始化最为简单,但不适合采用。因为如果将神经网络中参数全部初始化为0,那么每个神经元就会计算出相同的结果,在反向传播的时候也会计算出相同的梯度 ,最后导致所有权重都会有相同的更新。换句话说,如果每个权重都被初始化成相同的值,那么权重之间失去了不对称性。
tf.constant_initializer(value)
二、随机初始化
我们希望权重初始化的时候能够尽量靠近0,但是不能全都等于0 ,所以可以初始化权重为一些靠近0的随机数,通过这个方式可以打破对称性。这里面的核心 想法就是神经元最开始都是随机的、唯一的,所以在更新的时候也是作为独立的部分,最后一起合成在神经网络当中。
一般的随机化策略有高斯随机化 、均匀随机化等,需要注意的是并不是越小的随机化产生的结果越好,因为权重初始化越小,反向传播中关于权重的梯度也越小,因为梯度与参数的大小是成比例的,所以这会极大地减弱梯度流的信号,容易导致梯度消失问题。
1、均匀分布
tf.random_uniform_initializer
服从~U(a,b)U(a, b)U(a,b)
2、正态分布
#生成一组符合标准正太分布的tensor
tf.random_normal_initializer()
#生成一组符合截断正太分布的tensor
tf.truncated_normal_initializer()
服从~N(mean,std)N(mean, std)N(mean,std)
3、Xavier
#Xavier uniform initializer,个均匀分布(uniform distribution)来初始化数据。limit=sqrt(6 / (fan_in + fan_out))
tf.glorot_uniform_initializer()
#Xavier uniform initializer,由一个均匀分布(uniform distribution)来初始化数据。假设均匀分布的区间是[-limit, limit],则limit=sqrt(6 / (fan_in + fan_out))。其中的fan_in和fan_out分别表示输入单元的结点数和输出单元的结点数
tf.glorot_normal_initializer()
服从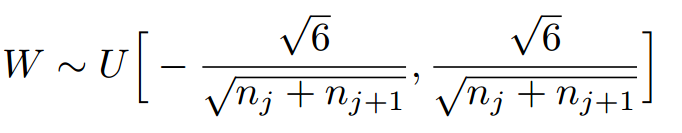
优点:输入和输出方差相同,包括前向传播和后向传播。解决了上文初始化aling_in方法,当初始化值很小,随着层数的传递,方差趋于0;初始值很大,随着层数传递,方差迅速增加。
缺点:只适用于关于0堆成、呈线性的激活函数。如sigmoid、tanh、softmax。对于ReLU可采用kaiming初始化
4、kaiming (He initialization)
Relu激活函数,基本都使用He initialization初始化
tensorflow没找到。pytorch版如下:
#均匀分布
torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
#正态分布
torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
三、稀疏初始化
另外一种初始化的方法就是稀疏初始化,将权重全部初始化为 0 。然后为了打破对 称性,在里面随机挑选一些参数附上一些随机值。这种方法的好处是参数占用的内存较少,因为里面有较多的0,但是实际中使用较少。
四、初始化偏置(bias)
通常使用0对偏置项b进行初始化。
五、批标准化
批标准化的核心想法是标准化这个过程是可微的,减少了很多不合理初始化的问题,所以可以将标准化过程应用到神经网络的每一层中做前向传播和反向传播,通常批标准化应用在全连接层后面 、非线性层前面。
实际中批标准化已经变成了神经网络中的一个标准技术,特别是在卷积神经网络 中,它对于很坏的初始化有很强的鲁棒性,同时还可以加快网络的收敛速度。另外,批标准化还可以理解为在网络的每一层前面都做数据的标准化预处理。
六、总结
实际应用中,对权重进行随机初始化、偏置全零初始化比较常用。
参考文献:
《深度学习之Pytorch》















 3802
3802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









