







简介
- 来源:AAAI 2016
- 内容:采用了分层seq2seq架构来解决多轮对话问题。
- 关键词:open-domain, large corpus,generative model,non-goal-driven
背景
对话系统分为任务导向型和非任务导向型。任务导向型对话系统的目标是为用户完成特定的任务,而非任务导向的对话系统(也称为聊天机器人)专注于在开放的领域与人交谈。一般来说,聊天机器人是通过生成式模型(Generative Models)或基于检索的模型(Retrieval-Based Models)实现的。
生成式模型(Generative Models)不依赖于预先定义的回答集,它会产生一个新的回答。经典的生成式模型是基于机器翻译技术(seq2seq models)的,只不过不是将一种语言翻译成另一种语言,而是将问句“翻译”成回答(response)。
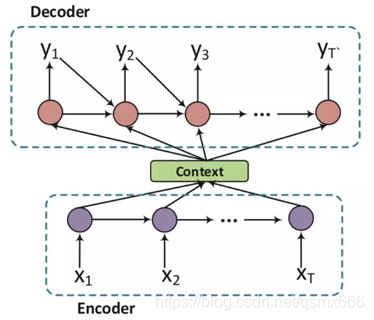
考虑对话的上下文信息的是构建对话系统的关键所在,它可以使对话保持连贯和增进用户体验。使用层次化的RNN模型,可以捕捉个体语句的意义,然后将其整合为完整的对话。
模型
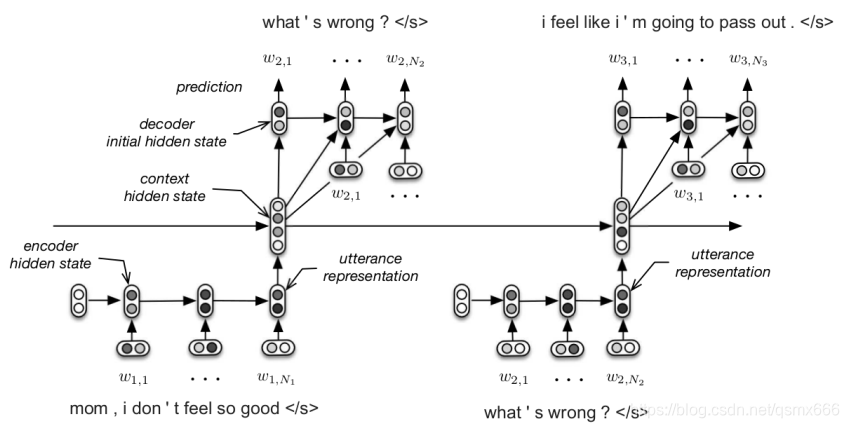
HRED模型是双层的RNN结构,一层对token-level 建模,一层对 utterance-level 建模。对对话进行分层,对话可以看做是 utterance的序列,utterance可以看做是token的序列。在每轮对话中,encoder RNN(token-level)将utterance表示成向量输入到context RNN(utterance-level)中。context RNN的hidden state就可以保留之前的对话信息,所以成为上下文向量。encoder RNN以context RNN的hidden state作为输入,输出下一个utterance 的token序列的概率分布。在encode和decode阶段,处理每个utterence的RNN结构完全相同而且共享参数。
预训练
预训练分为两个部分,第一部分是对词向量进行预训练,第二部分是在大规模问答语料上进行训练,其话题和类型相似。
实验结果
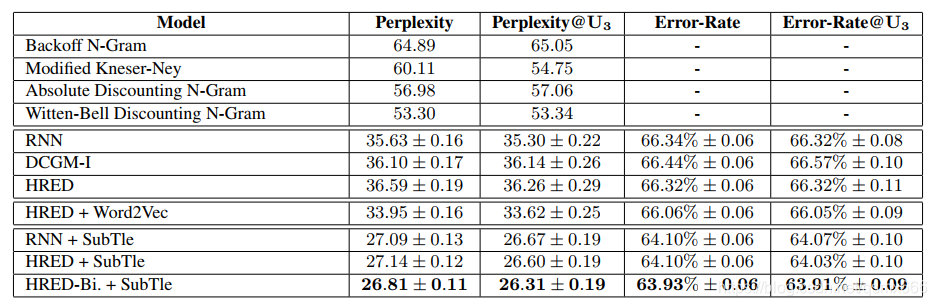
评估指标为困惑度。相比原始的seq2seq模型,HERD模型的效果并没有较大改善。而在Word2vec和在数据集Subtle上的预训练对模型的准确度提升有显著效果。
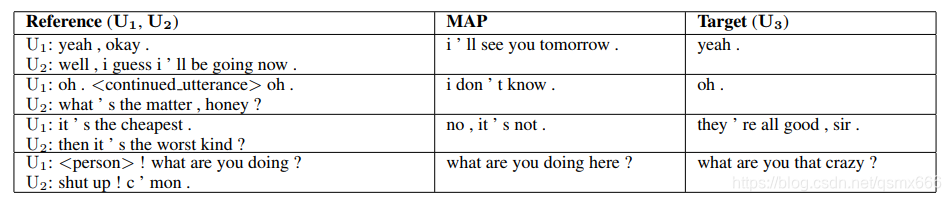
表格中第二列是前一张表最优模型(双向HERD+Subtle预训练)的输出,即根据U1和U2产生的回复。可以看到还是该模型是可以产生有意义的回复的。但是产生的回复总体上趋于同质化,质量不高。“I don’t know”或“I’m sorry”之类的句子出现较为频繁。作者分析了可能的原因一是数据量较少,二是句子中代词和标点符号过多,占了较大权重,因此建议探索将语义和句法结构分开的架构,还有就是只有三轮对话,长对话的效果可能会更好。














 1273
1273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









