








由于高斯混合模型中参数数量非常大,因此本文提出了子空间高斯混合模型(subspace GMM),
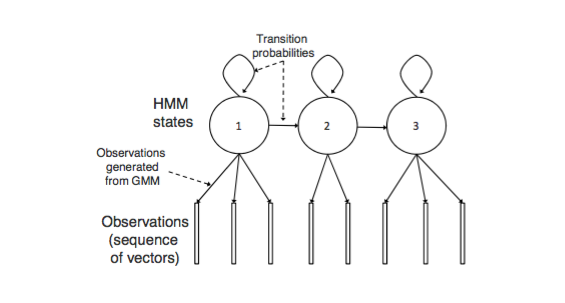
HMM在语音识别中的架构如上图所示,其中HMM状态j产生观测序列是由GMM表示:

其中:i 表示GMM模型中component个数,j表示状态
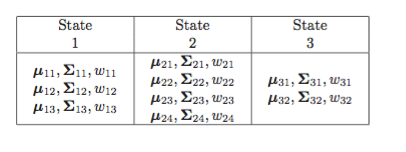
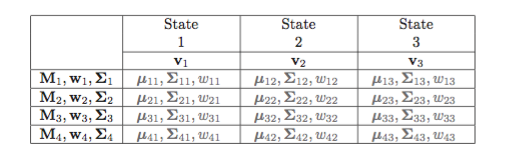
下表显示了每个状态pdfs对应的GMM参数
子空间高斯混合模型SGMM中对以上参数进行优化,公式如下:

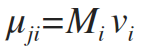
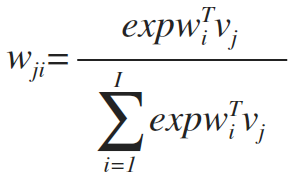
这里新增了一个向量Vj, Vj是一个S维的向量。
x为D维的特征向量,通常为39维MFCC,
j为trip-hone
Σi 为协方差,同一个高斯component中,状态之间共享同一个协方差。
这样参数可以简化成如下所示:
其中中间灰色部分为替换的部分。
由于状态j又有Mj 个子状态,则把状态j替换成jm的子状态对,则公式如下所示:
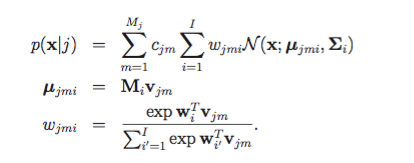
其中Cjm ≥ 0 且
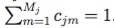
则现在每个状态是混合中的混合模型,即j是由Mj 个子状态,I个高斯components混合构成。
现在,我们再使用CMLLR特征变换,其中特征向量x变换为x'

其中上面s为说话人索引。同时对似然引入一个行列式因子| det A(s)|
为了增加说话人自适应,对每个高斯component i中的均值添加一个偏移Niv(s)
则SGMM改写为如下:
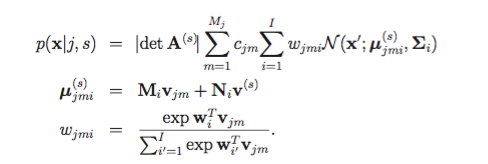
为了训练SGMM,首先需要一个通用的背景模型(UBM),训练过程如下所示:
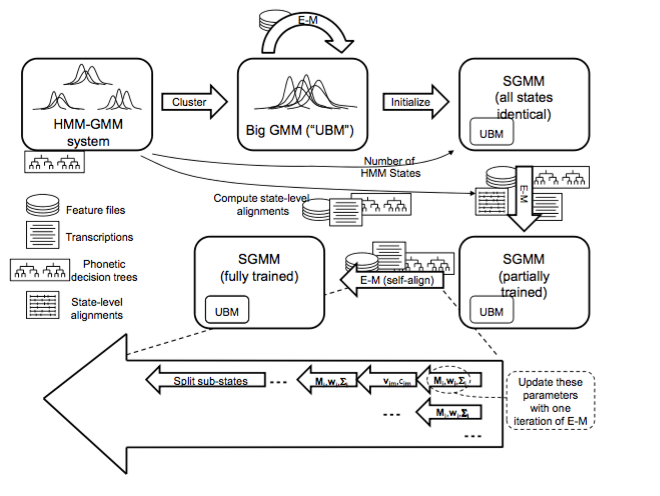
1)初始为一个HMM-GMM模型;
2)状态绑定,高斯聚类,来初始化一个UBM;
3)在训练数据上,用E-M算法来进行调优,这样我们就初始化完成一个SGMM模型;
4)接下来有2部E-M训练,第一步是用Viterbi状态对齐我们的HMM-GMM基线,第二步是用Viterbi对齐来得到SGMM模型(self-align过程),每步骤都是一个迭代的过程。
下一篇会详解初始化和训练的SGMM过程。
有了SGMM模型,我们再来看看SGMM的优势,看一下参数节省了多少:
如下表所示:

上表中,左侧为基线版参数个数共:2.1百万个,右侧为SGMM参数个数,为1.57百万个
优势明显。















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









