







 语音识别声学模型DNN训练通常用cross-entropy(CE)作为损失函数进行训练,CE可以看做是KL散度的一种形式 ,用来评价期望分布和当前训练模型概率分布的差距。方便计算,所以常常被用来作为损失函数广泛使用。然而基于帧识别的语音识别中,往往用WER或者CER,PER来作为评价语音识别的准确率。损失函数和训练目标不一致,因此本文对基于序列区分度(Sequence Discriminative training)目标函数来进行训练进行了介绍和总结
语音识别声学模型DNN训练通常用cross-entropy(CE)作为损失函数进行训练,CE可以看做是KL散度的一种形式 ,用来评价期望分布和当前训练模型概率分布的差距。方便计算,所以常常被用来作为损失函数广泛使用。然而基于帧识别的语音识别中,往往用WER或者CER,PER来作为评价语音识别的准确率。损失函数和训练目标不一致,因此本文对基于序列区分度(Sequence Discriminative training)目标函数来进行训练进行了介绍和总结
语音识别声学模型DNN训练通常用cross-entropy(CE)作为损失函数进行训练,CE可以看做是KL散度的一种形式 ,用来评价期望分布和当前训练模型概率分布的差距。方便计算,所以常常被用来作为损失函数广泛使用。然而基于帧识别的语音识别中,往往用WER或者CER,PER来作为评价语音识别的准确率。损失函数和训练目标不一致,因此[1]提出了基于序列区分度(Sequence Discriminative training)目标函数来进行训练,sequence discriminative training在训练过程中结合了发音词典和语言模型,以序列进行区分训练,使得相近的句子识别概率更大,其他的概率尽量小,使得训练的模型识别率更加提升。sequence discriminative training训练前往往先使用CE训练对齐[2],产生lattice,然后再通过lattice进行sequence discriminative training[3][8][10][11]。当然近期也有用过lattice-free来进行sequence training[4]。本篇文章就主要介绍sequence discriminative training通过lattice进行训练的过程。lattice-free进行sequence discriminative training会在后面的文章进行介绍。接下来我们会把sequence discriminative training简称为sequence training(需要注意的是sequence to sequence training和本文无关,seq2seq training是机器翻译中的encode-Decoder模型,逐渐应用到语音识别中,文章中已经有了详细的介绍)
当前比较流行的sequence training目标函数有最大互信息Maximum Mutual Information (MMI), boosted MMI(BMMI), 和最小贝叶斯风险 sMBR。MMI目标函数公式如下[5]:
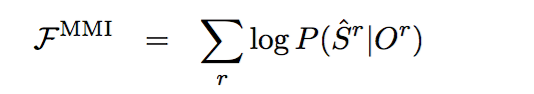
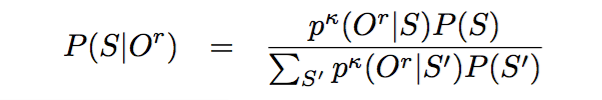
BMMI和MBR目标函数如下所示[5]:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









