







 本文探讨了Attention模型在语音识别中的应用,从机器翻译中的起源开始,详细解释了Attention的工作原理和计算方式。通过分析Jan Chorowski的论文,展示了Attention如何在Encoder-Decoder架构中提升性能。同时,介绍了Dzmitry Bahdanau的改进,包括加窗、GRU结构和n-gram支持。尽管Attention存在对长句子识别的不足和训练不稳定性,但与CTC结合的方法如Suyoun Kim的文章所示,能提高模型收敛速度和性能。此外,Facebook和Google的最新研究进一步展示了Attention在CNN和MNT领域的创新应用。
本文探讨了Attention模型在语音识别中的应用,从机器翻译中的起源开始,详细解释了Attention的工作原理和计算方式。通过分析Jan Chorowski的论文,展示了Attention如何在Encoder-Decoder架构中提升性能。同时,介绍了Dzmitry Bahdanau的改进,包括加窗、GRU结构和n-gram支持。尽管Attention存在对长句子识别的不足和训练不稳定性,但与CTC结合的方法如Suyoun Kim的文章所示,能提高模型收敛速度和性能。此外,Facebook和Google的最新研究进一步展示了Attention在CNN和MNT领域的创新应用。
从2014年Attention mode在机器翻译或起来以后,attention model逐渐在语音识别领域中应用,并大放异彩。因此本篇文章就对Attention进行总结和说明。
首先要确定的是Attention是一种权重向量或矩阵,其往往用在Encoder-Decoder架构中,其权重越大,表示的context对输出越重要。计算方式有很多亚种,但是核心都是通过神经网络学习而得到对应的权重。通常其权重aij和Decoder中的第i-1个隐藏状态,Encoder中的第j个隐藏状态相关[1]。
接下来跟进一篇论文来具体了解Attention的用法和构成。第一篇文章是Jan Chorowski 的《Attention-Based Models for Speech Recognition 》[2].
Encoder端是一个BiRNN结构,第i步的输出Yi和hi和Attention的权重相关,具体架构如下图所示:
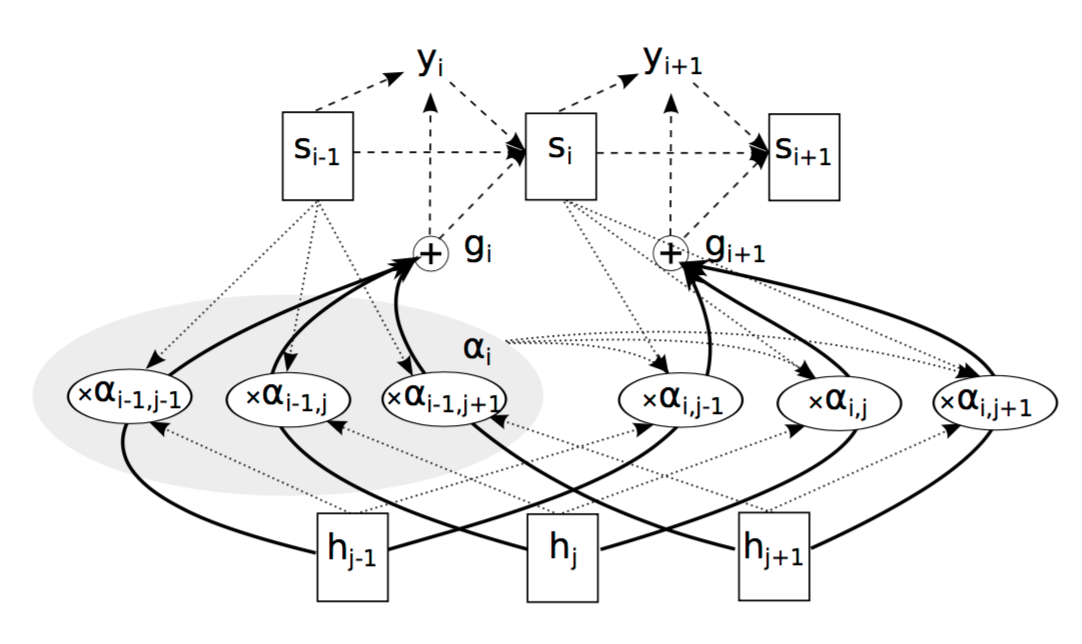
其输出Yi为:
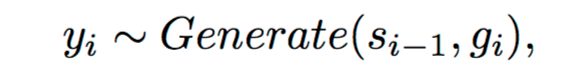
其中,Generate为RNN的Decoder结构,Si-1表示Decoder中的第i-1个状态,gi表示glimpse,即Attention和隐藏层H相乘之后的结果,
glimpse为:
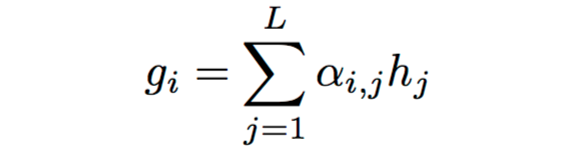
上式中,aij即为Attention的权重,hj为encoder中第j个隐藏状态。
si为Decoder中的因此状态,依赖si-1和gi和yi,如下所示:
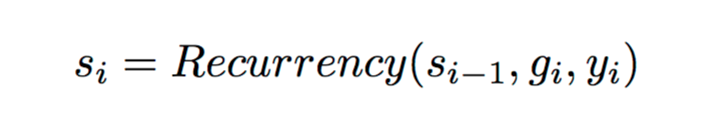
以上为Attention的用法,解析来看一下Attention中aij是如何进行得到的。
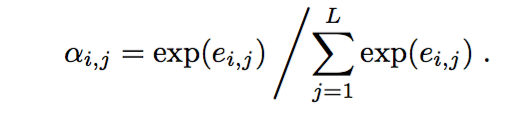
aij是eij经过softmax的结果,eij计算如下(content-basedAttention ):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









