







 本文介绍了在语音识别中,如何利用HMM和GMM来计算观测最大似然,详细阐述了从单高斯模型到多元高斯模型,以及GMM在声学模型训练中的应用,包括Baum-Welch迭代算法的使用。
本文介绍了在语音识别中,如何利用HMM和GMM来计算观测最大似然,详细阐述了从单高斯模型到多元高斯模型,以及GMM在声学模型训练中的应用,包括Baum-Welch迭代算法的使用。
在上一章语音识别过程中提到的P(O|W )称做观测最大释然,由声学模型计算可得,本章就主要描述HMM+GMM来计算最大释然的过程。
首先回顾一下:在解码过程中
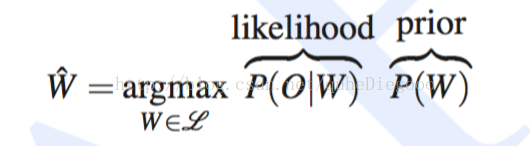
P(O|W )由声学模型训练得到,
P(O|W )是W的似然函数,结合之前讲述的声学特征也就是说,在给定的W情况,使得当前的特征向量(MFCC)的概率最大,结合HMM的概念,也就是说在在t时刻给定状态qi 的前提下,求输出O的概率,即p(ot|qi) ,即矩阵B,状态对应的是word,phone或者subphone,在LVCSR中对应的是subphone
在解码阶段,在固定观测向量ot 的前提下,我们需要计算每一个HMM状态可能产生的概率,然后找到最大可能的状态(subphone)序列,所以训练过程就是计算观测似然矩阵B的过程。
理想的方式计算MFCC的时候,可以把输入的帧映射为一些离散的量化符号方便计算,如下图所示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









