







内容来自Andrew老师课程Machine Learning的第二章内容的Multivariate Linear Regression部分。
一、Multiple Features(多特征)
1、名词
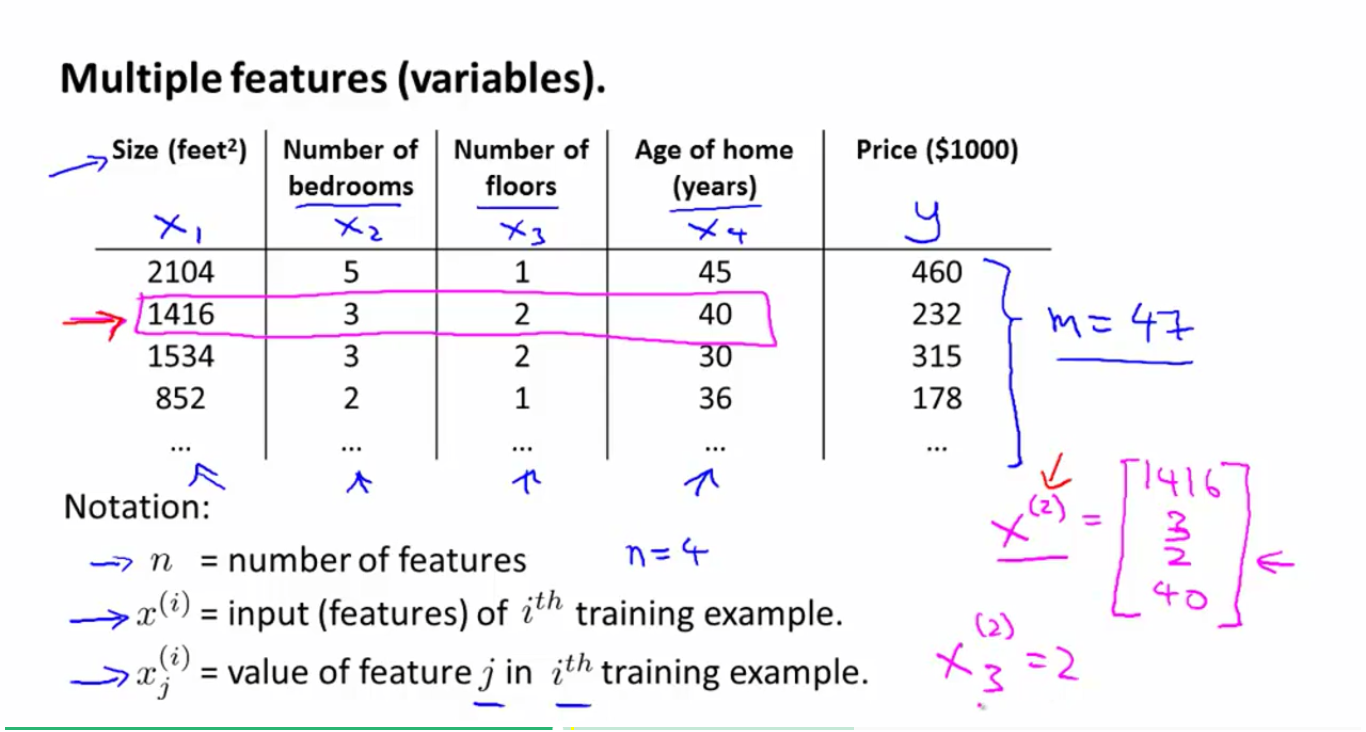
(1)
m
m
:样本的数量,上例中m=4
(2):特征数目,上例中n=4
(3)
x(i)
x
(
i
)
:第i个训练样本的所有特征值
上例中,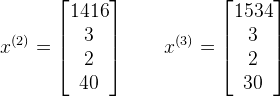
(4)
x(i)j
x
j
(
i
)
:第i个训练样本的第j个特征值
上例中,
x(2)3=2,x(3)1=1534
x
3
(
2
)
=
2
,
x
1
(
3
)
=
1534
.
2、之前含有一个特征值的假设函数已经不足满足多特征向量预测的要求,多特征值的假设函数为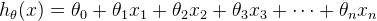

3、怎样把多特征值的假设函数转化为矩阵和矩阵相乘?如下图:

(1) 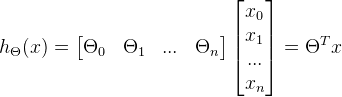
(2)为了表述方便,令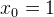
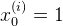
二、Gradient Descent for Multiple Variables(多变量线性回归的梯度下降)
如何用梯度下降算法来解决多特征的线性回归问题?
1、多特征的假设、代价函数和梯度下降函数如下图:

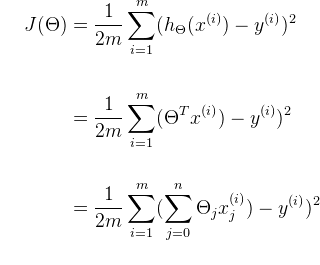
2、将h(x)代入梯度下降算法,如下图:

其实多参数线性回归和单参数线性回归的梯度下降算法是一致的,多参数线性回归是单参数线性回归的推广。
三、Gradient Descent in Practice I - Feature Scaling(实践中梯度下降I:特征缩放)
有两种方法可以提高梯度下降算法运行的效率,特征缩放和均值归一化。
1、特征缩放的定义和示例:
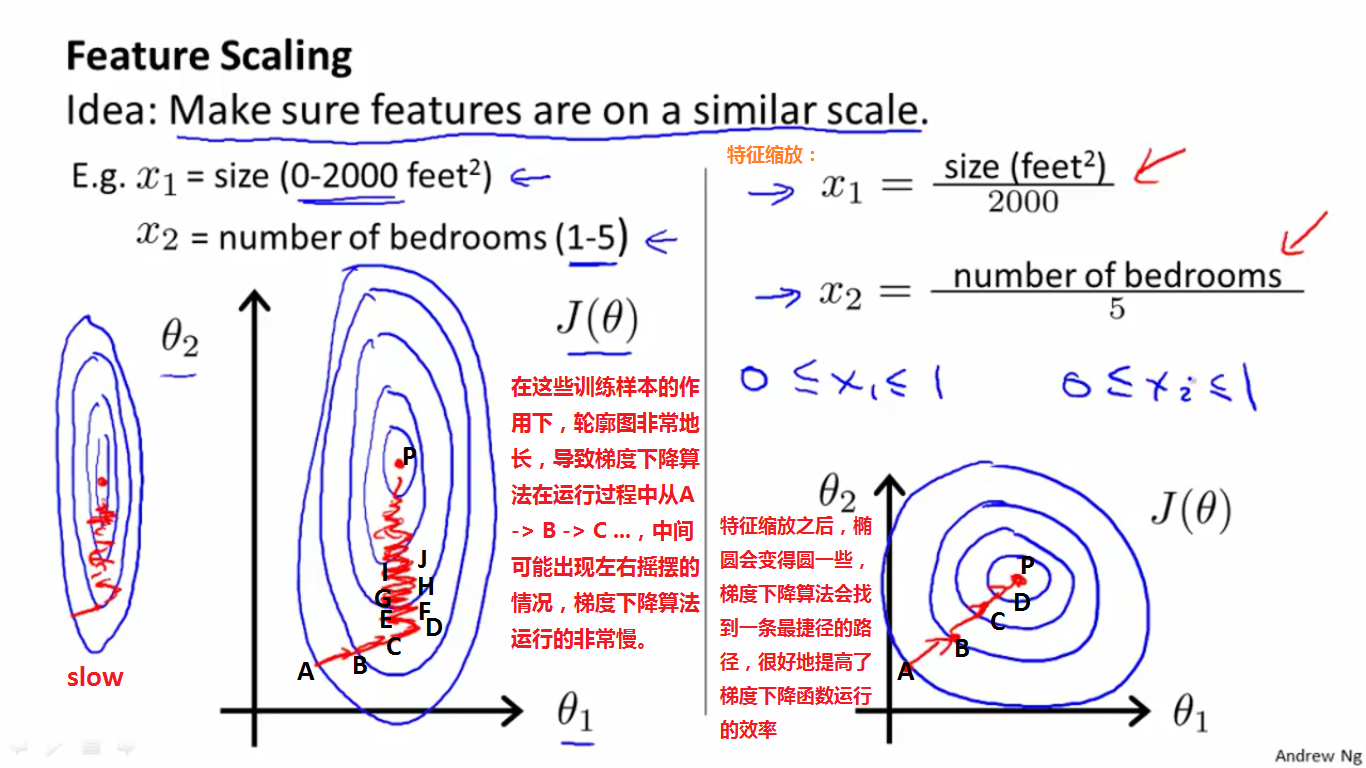
左半部分是没有进行特征缩放之前的轮廓图,梯度下降算法运行的比较慢。右半部分是进行特征缩放之后的轮廓图,趋于圆,在这些数据的作用下,梯度下降算法运行地比较快。
2、特征缩放到什么程度?
一般情况下,让每一个特征变量都大概在[-1,1]范围内(注:1只是一个特例,不一定非要是1)
例如:
[0,3]可以
[-2,0.5]可以
[-100,100]不可以,数据变化范围太大
[-0.00001,0.00001]不可以,数据变化范围太小
[-3,3]可以
[-1/3,1/3]可以
3、均值归一化

举例:
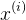
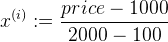
通过特征缩放,可以让梯度下降算法运行地更快,让梯度下降收敛所需的循环次数更少。
四、Gradient Descent in Practice II - Learning Rate(实践中梯度下降II:学习速率)
本节内容主要是如何选取学习率α。
1、下图是α大小合适情况下对应的J(theta)的图形。

2、下图是α过大情况下对应的J(theta)的图形。
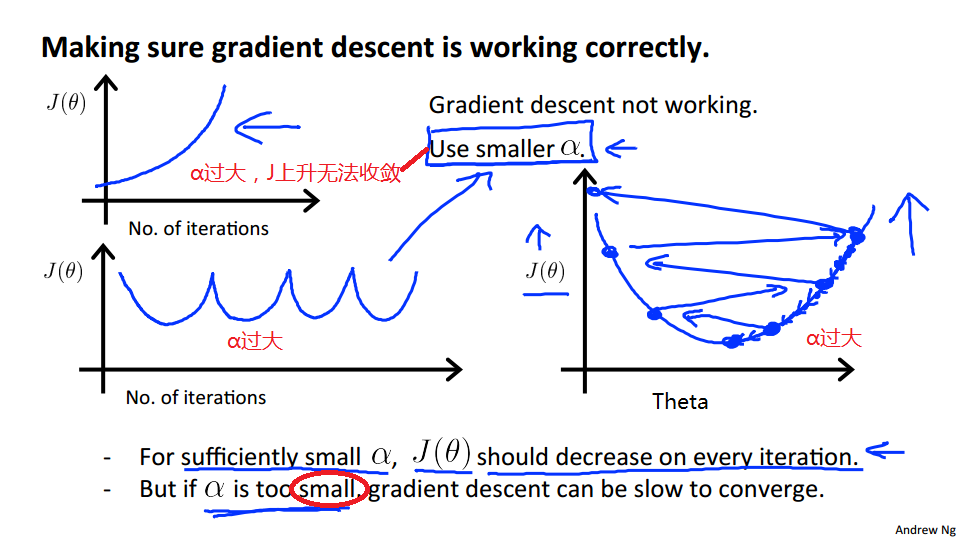
如果α下降的比较慢,则是因为α的值过小。
3、一个练习题,在α正常、过小和过大情况的图如下:

4、总结:如何选择合适的α值?

五、Features and Polynomial Regression(特征和多项式回归)
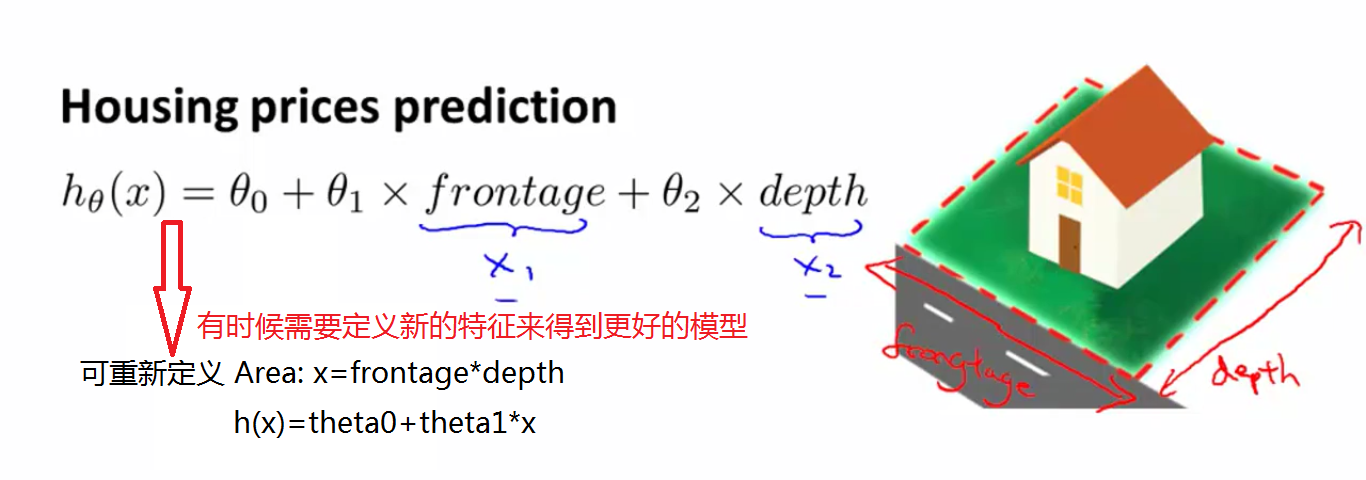
1、以房子价格为例,来说明有时候可能需要构造新特征来得到更好的预测模型。如下图:
2、多形式回归
以下是一个住房价格的数据集,为了训练预测模型,先假设是二次函数,发现虽然二次函数能拟合但是超过最高点之后,price的值会下降,所以再假设拟合函数是三次函数,但是三次函数也存在问题,price会一直增大,如下图:
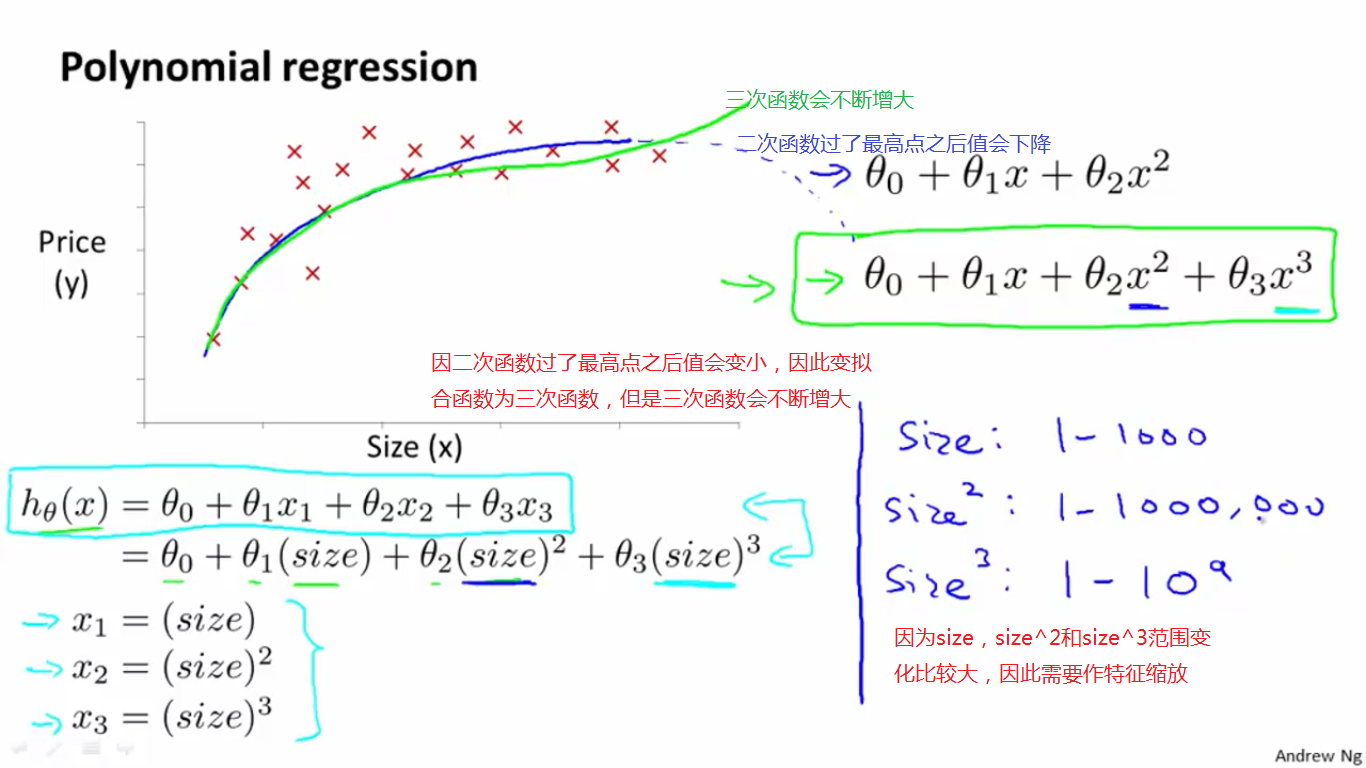
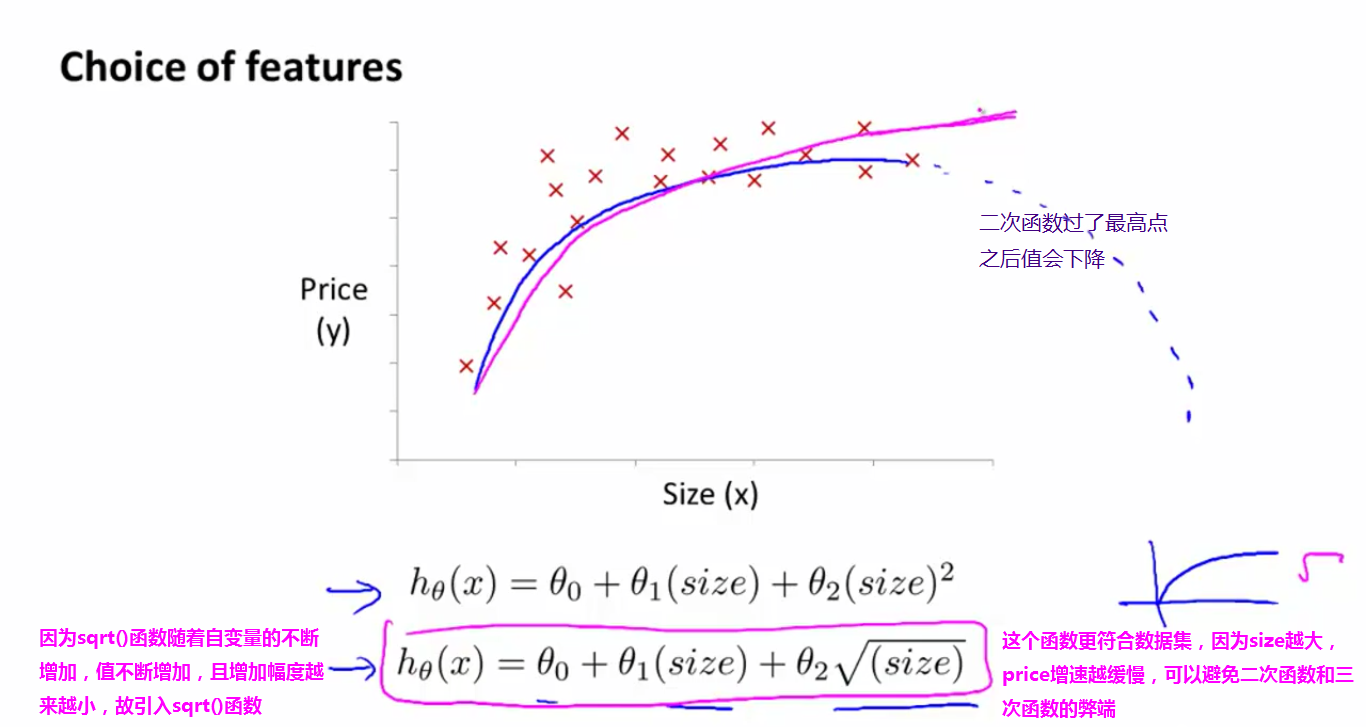
如何选出合适的拟合函数,如下图,这里选择一个与sqrt有关的函数,与二次函数和三次函数相比,这个函数的拟合性更好,如下图:















 3520
3520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









