







核岭回归(KRR) [M2012]是使用了核技巧与 岭回归(使用L2范数正则化的线性最小二乘法)结合而成。也因此它是学习由相应的核和数据的空间中的线性函数。对于非线性核,这对应原始空间中的非线性函数。
KernelRidge 模型被证明为是支持向量回归(SVR)的。然而,可以使用不同的损失函数:KRR使用平方误差损失而支持向量回归使用 ε不敏感损失 ,并且他们都结合了L2正规化。相比于 SVR,其使用封闭形式来拟合 KernelRidge,并且对于中型数据集通常更快。在另一方面,因为经过学习后的模型是非稀疏的,所以在处理方面要比 SVR 慢,因为SVR在预测期间是在 ε > 0 情况下学习稀疏模型。
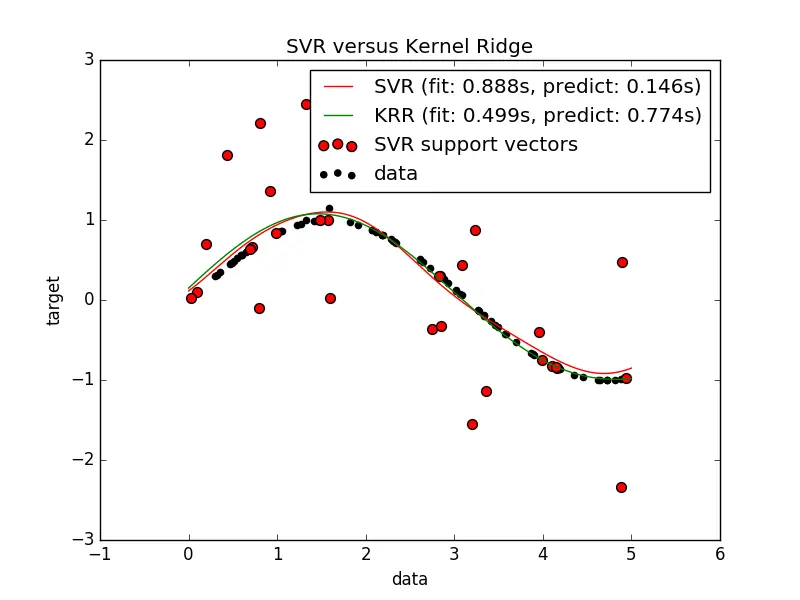
下面的图表比较了 KernelRidge 和 SVR 在一个人工数据集的预测,其份数据是由(符合)正弦函数的数据和每五个数据点中就加入强噪音组成的。在画出的 KernelRidge 和 SVR 模型图里,他们的复杂性/正则化和RBF核的频宽都已经通过网格搜索算法设置了最佳值。他们的学习函数十分相似,但是 KernelRidge 的拟合是近似的。(KRR)的拟合速度是拟合 SVR 的七倍(均使用了网格搜索)。然而在预测10万个目标值的时候只比 SVR 的拟合速度高出三倍,因为其只是使用了大概的稀疏模型。
在训练集中,每100个数据点中都有三分之一的数据为支持向量。
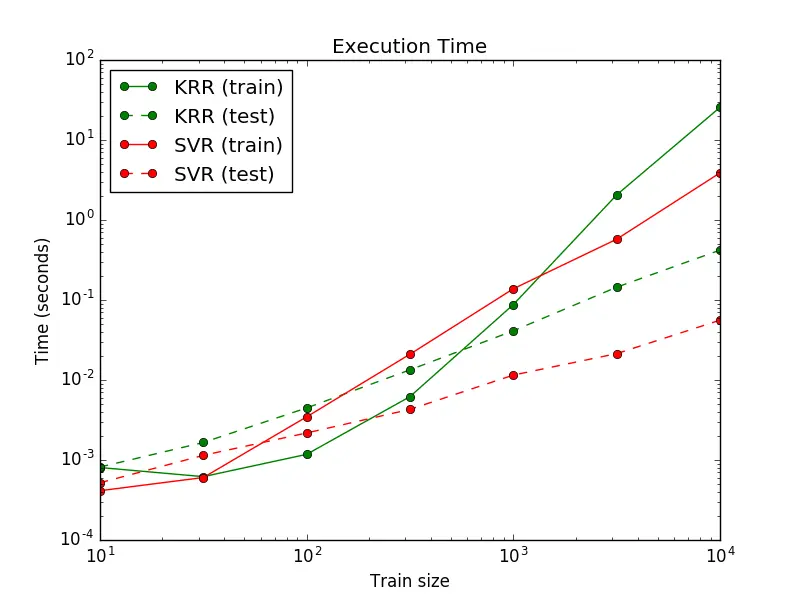
下一张图表比较了在不同的数据集规模中,KernelRidge 和 SVR 的拟合和预测耗时。在中等规模下的训练集(样本数量小于1000) KernelRidge 的拟合比起 SVR 要快;但是在大规模训练集时则是 SVR 要快。在预测时间方面,无论数据集有多大,SVR 要比 KernelRidge 快,因为其是使用了稀疏解。但是要注意的是,SVR 的稀疏度和预测时间都取决于其参数 ε 与 C 。当 ε = 0 时会代表其是个密集模型。
引用
M2012. “Machine Learning: A Probabilistic Perspective” Murphy, K. P. - chapter 14.4.3, pp. 492-493, The MIT Press, 2012
作者:HabileBadger
链接:http://www.jianshu.com/p/b74fefe497ab
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









