






作者:徐晗曦
原文:写给大家看的机器学习书(第四篇)—— 机器学习为什么是可行的(上)
本次转载已获得作者授权,尊重原创,若需转载请联系作者本人。相关文章:
写给大家看的机器学习书【Part1】什么是机器学习?机器学到的到底是什么?
写给大家看的机器学习书【Part2】训练数据长什么样?机器学到的模型是什么?
写给大家看的机器学习书【Part3】直观易懂的感知机学习算法PLA这个系列文章,我将试着为开发工程师,产品经理、设计师、所有希望了解学习机器学习的人,介绍机器学习的原理、方法和实战技巧。
1. 你敢跟着机器学习投资吗?
系列文章学到这里,我们已经理解了机器学习的概念,也掌握了一个具体的学习算法 (Learning Algorithm)。似乎机器学习的大门已经打开,以后了解更深的模型,学习更多的技法,一帆风顺的样子。
不过稍等一会,让我们再回顾一下到目前为止我们所学到的机器学习概念:根据训练数据,从假设集合 (Hypothesis Set) 中挑出一个最优的假设 g 作为学得的模型。
有没有人在学习的过程中有过这么一丝疑虑:
这个由训练数据也就是历史日志学得的模型,真的能在未来的预测中表现的一样好吗?
如果你还记得图1左上角的那个”上帝真相”(Ground Truth),那个只有上帝才知道的完美模型 f ,我想问:
我们学到的模型 g 真的能像 f 一样完美地预测未来吗?
不妨再具体一些,股市中我们根据历史数据学到了一个表现很不错的模型,你敢按照模型对未来的预判操作真金白银的投资吗?
你是否也有过那么一时三刻的不自信,所谓“以史为鉴,可以知兴亡”,从历史中总结出的规律,是否真的能在未来的预测中被信赖?为了做一个对未来负责的机器学习专家,从这一篇开始的上下两篇,我们将试着解答这个疑惑,即
模型对未来的预测真的是可信的吗?
图1:

2. 没有人可以预测未来
别傻了,没有人可以预测未来。
——《来自未来》
我们先来看下面这个例子。
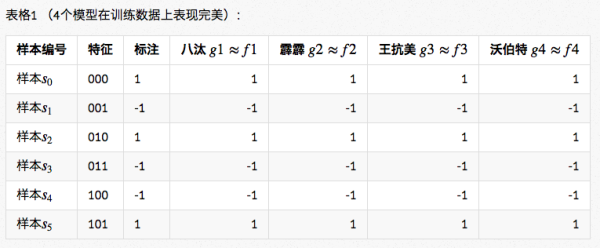
也不知是谁从哪儿搞来了这么几条数据,整理成表格1的前三列所示( | 样本编号 | 特征 | 标注 | ),希望我们找出特征和标注之间的规律。
于是,八汰、霹霹、王抗美、沃伯特 4 位算法工程师对这个问题进行了学习,最终得到了4个模型。
- 据说八汰使用了PLA学习算法,学得了模型g1。他把g1所逼近的 Ground Truth 记作f1。
- 据说霹霹使用了强化学习算法,学得了模型g2。他把g2所逼近的 Ground Truth 记作f2。
- 据说王抗美使用了深度学习算法,学得了模型g3。他把g3所逼近的 Ground Truth 记作f3。
- 而沃伯特则没有透露他的算法,总之得到了模型g4。他把g4所逼近的 Ground Truth 记作f4。
这 4 个模型学得怎么样呢?我们来看看表格1的后4列,这4列记录了模型的输出。比照第三列的样本标注可以看到,在训练数据上模型的输出和样本标注完全一致,4个人的模型都表现的相当好。
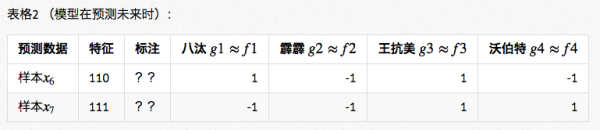
不过我们也知道,在训练数据上表现得好那不是真的好,模型最终是希望对未知数据进行可靠地预测,预测得准才是真的准。于是找来了表格2中的两条数据,这两条数据的标注是未知的,让4个人的模型预测一下标注会是什么。
结果如表格2的后4列所示,棘手的情况发生了! 4个人的模型竟然给出了完全不同的预测。
- 八汰的模型:预测的结果是 1和 −1。
- 霹霹的模型:预测的结果是 −1和 −1。
- 王抗美的模型:预测的结果是 1和 1。
- 沃伯特的模型:预测的结果是 −1和 1。
这可就懵圈了,4 个人用 4 种不同的算法,学得的模型都在训练数据上获得了完美的表现,但是预测的结果却完全不同。
那到底应该相信谁的算法呢?谁的预测才是准确的呢?
很抱歉,让大家走了那么远,现在要告诉您一个可能有点颠覆的结论:
机器学习中有个非常著名的 No Free Lunch (NFL) 定理 告诉我们,在这个例子描述的情况下,这些算法的期望水平是一样的。
更要命的是,沃伯特这个时候说他根本没有用什么机器学习算法,他的预测是靠瞎猜决定的。如果他说的是真的,这也就意味着 No free Lunch 定理告诉我们,那些高深算法得到的模型竟然跟瞎猜是同等水平的。
怎么可能??这个人说谎的吧!!
他没有说谎,沃伯特,原名 David H. Wolpert,他就是提出并证明了 No Free Lunch 定理的科学家本人。No Free Lunch,即天下没有白吃的午餐,是所有机器学习专家求学路上的一记板砖。
3. 在 No Free Lunch 之后的世界观重塑
No Free Lunch,这顿难以下咽的午餐一下摧毁了我们对于机器学习的信念。各种学习算法竟然都跟瞎猜差不多!那机器学习根本是不可能的吧,怎么可能信任瞎猜算法去投资呢?
是不是遗漏了什么啊?!
是的,确实遗漏了很重要的一个前提。让我们闪回到上一小节的这段话
“机器学习中有个非常著名的 No Free Lunch (NFL) 定理告诉我们,在这个例子描述的情况下,这些算法的期望水平是一样的。”
注意这句:“在这个例子描述的情况下”!也就是说 NFL 定理有个很重要的前提,只有在像上面这个例子描述的情况下才会导致各种精巧的机器学习算法跟瞎猜差不多,而在许多具体的实际应用场景中,并不满足这个前提。
那到底“上面这个例子描述的情况”是指什么呢?好好记住它:
NFL定理在阐述的过程中假设了 f 的均匀分布,即所有潜在的可能性发生的概率是一样的。
具体来说,在上面的例子中,在这批不知从哪儿来的训练数据的情况下,可能产生训练数据的 Ground Truth f 有多个,但又因为没有具体的场景,导致这多个 f 是真正产生这批训练数据的 Ground Truth 的概率是一样的。
而无论哪种学习算法必定最终倾向了其中的某个 f ,因此最终这些算法的期望水平就是一样的。(学习算法的这种倾向,称为学习算法的归纳偏好(inductive bias),简称“偏好”。)
后面我们会看到,在具体的实际场景中,某些 f 代表的可能性发生的概率大,某些 f 代表的可能性发生的概率小,某些可能性则根本不会发生。它们的概率不是均等的,因此不再满足NFL定理的前提。举个例子,比如有一个不透明的存钱罐,里面有几百颗硬币。你随机抓出一把发现抓上来的全都是1元的硬币。这时让你预测再捞一次发生的情况,很显然捞上来全部是1角的概率,就会远远的低于全部是1元的概率。
这个时候的黑色罐子,在我们看不见的上帝真相之间,世界发生了倾斜。
于是,在具体的现实问题中,那些归纳偏好与问题本身匹配的算法就能取得很好的效果,从而另学习是可行的。
最终总结一句,我们花了那么大的力气,绕了一大圈连蒙太奇都用上了,就是希望你能理解NFL定理背后所表达的哲学,即:
脱离具体问题讨论机器学习算法的好坏,是没有意义的。
如果有人声称XX学习算法就是比YY学习算法厉害,多半不是骗子,就是坏人。
4. 预告和其它
由于业余时间和精力的有限,未能在一周之内完成这个主题——“机器学习为什么是可行的”,只好分成上、下两篇。这个系列的写作能够进入到第四篇甚至是第五篇,已经超出我最初的想象。感谢所有给予我鼓励的阅读者,每周一篇的写作对于我来说是考验却也收获颇多,希望自己能坚持下去,也希望这个系列文章能给您带去一点点价值。
再次感谢您的阅读,这里是《写给大家看的机器学习书》,我是八汰。如果您希望收到后续文章的更新,可以考虑关注我。或者关注这个同名专栏,文章将会在您的通知中心推送更新。
祝开心 :)

















 4901
4901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









