







文章目录
前言
本篇文章主要讲解了Scrapy库的基本使用,使用Scrapy库提取黑马程序员“软件测试自学全套课程”模块的视频名称、学习人数、课程等级和视频评分。
一、实验目的
- 了解Scrapy框架的原理;
- 掌握Scrapy各组成部分及运行流程;
- 掌握如何使用Scrapy框架爬取网站数据。
二、实验内容
本次实验使用Scrapy对网站数据进行收集,通过本实验掌握Scrapy项目的创建、运行及具体使用。
三、实验原理
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
四、 Scrapy库提取“软件测试自学全套课程”信息
1. 安装Scrapy框架;
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
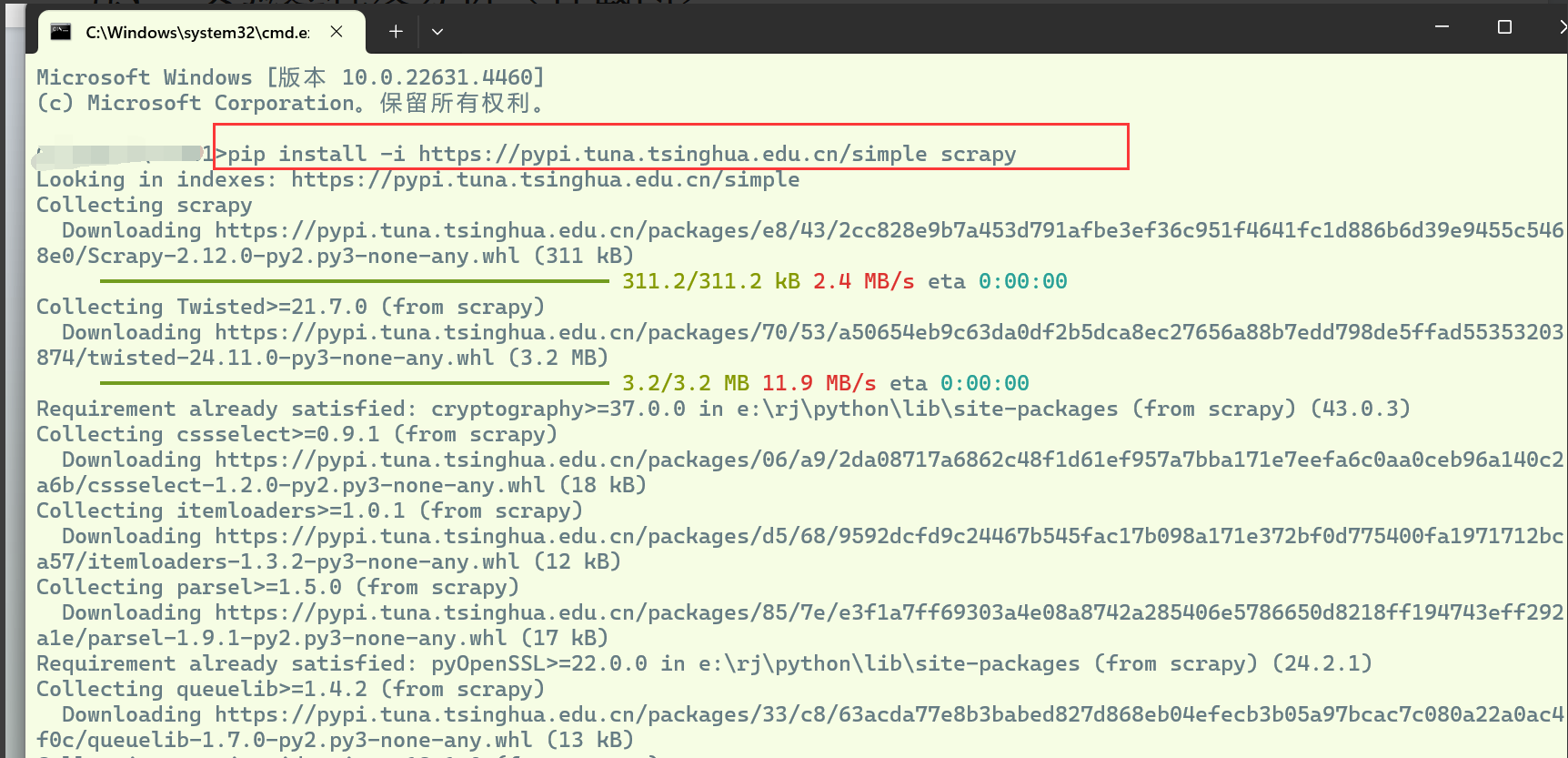
安装成功,查看scrapy的版本信息为:Scrapy2.12.0

2. 创建Scrapy项目;
创建Scrapy项目名为:qxx,项目路径在 C:\Users\17181\qxx,为了方便操作,改一下路径放在桌面
scrapy startproject qxx

Scrapy项目的目录结构
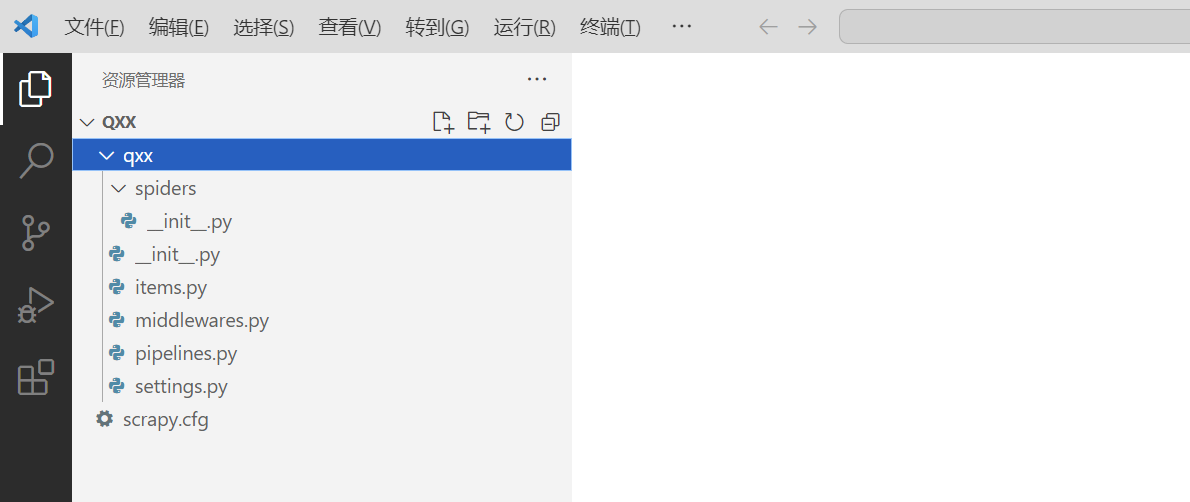
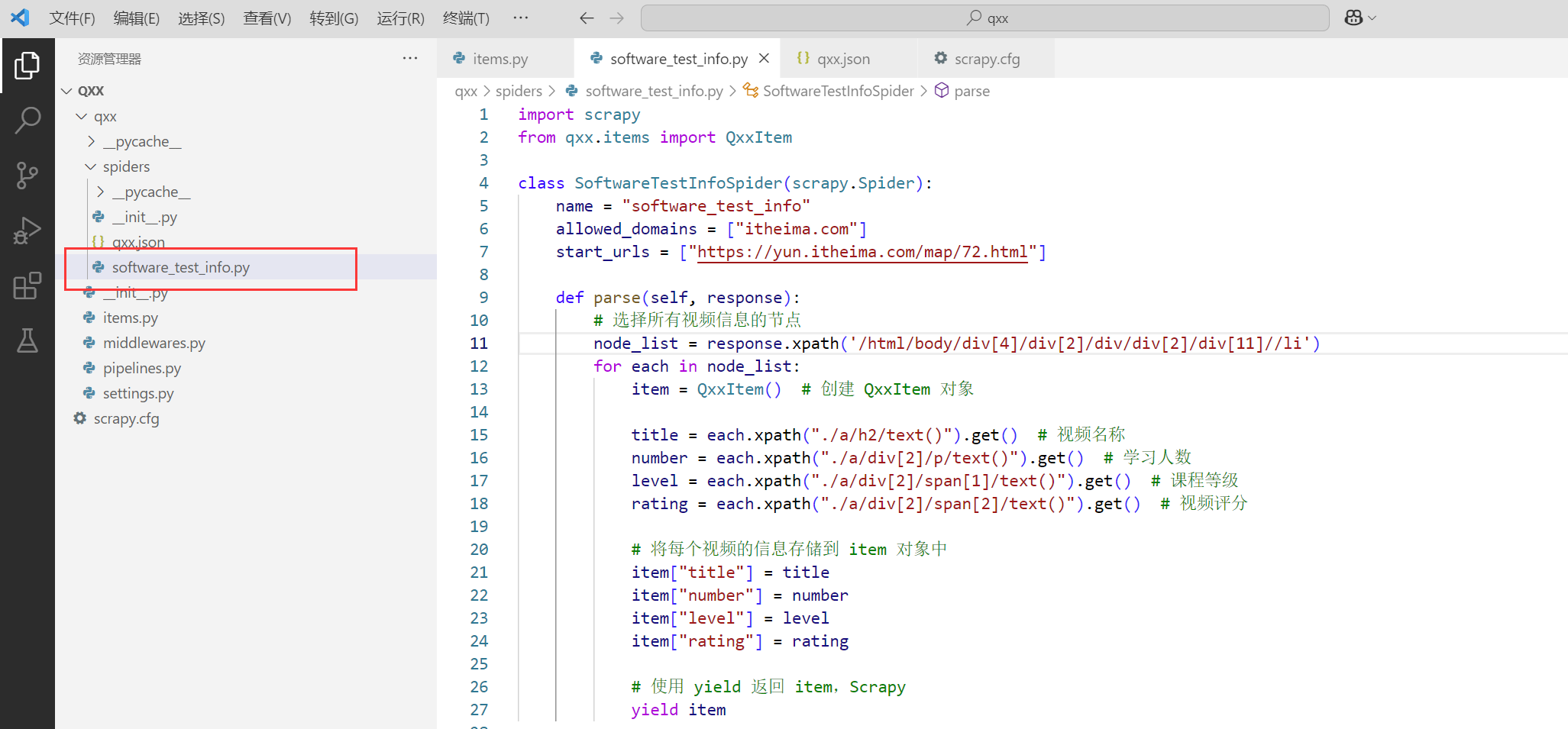
3. 分析网页,实现爬取逻辑;
软件测试自学全套课程:https://yun.itheima.com/map/72.html
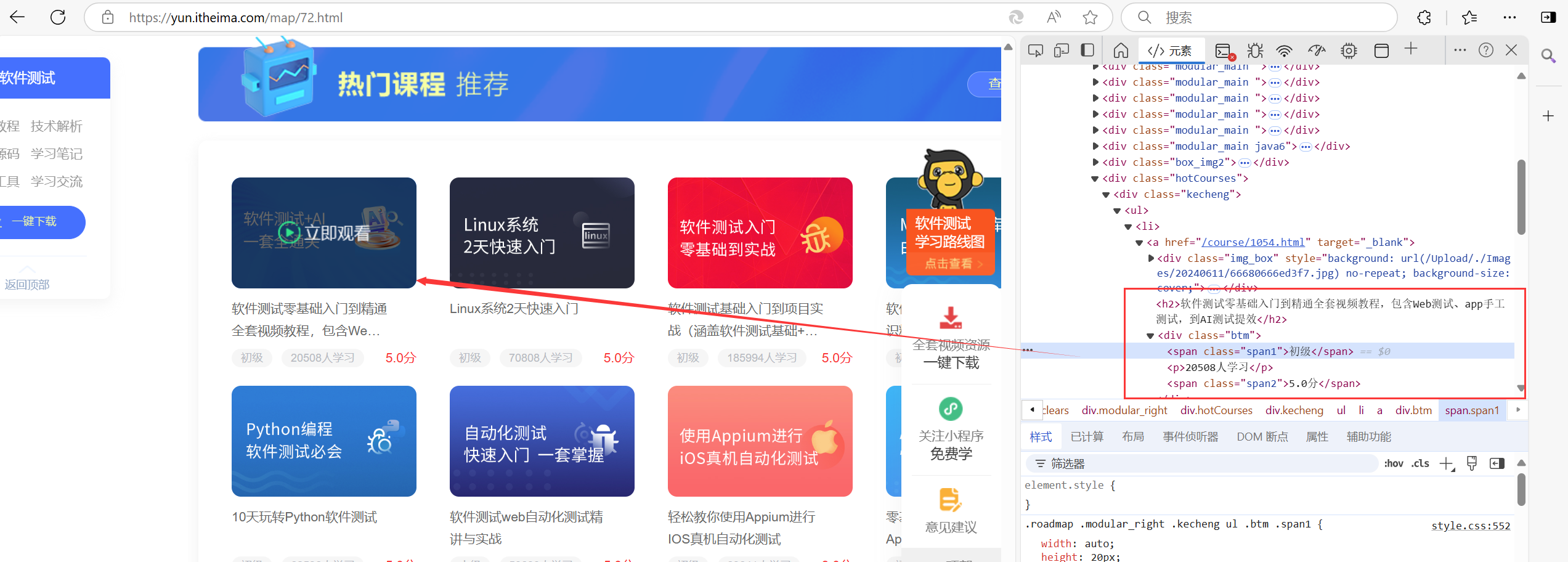
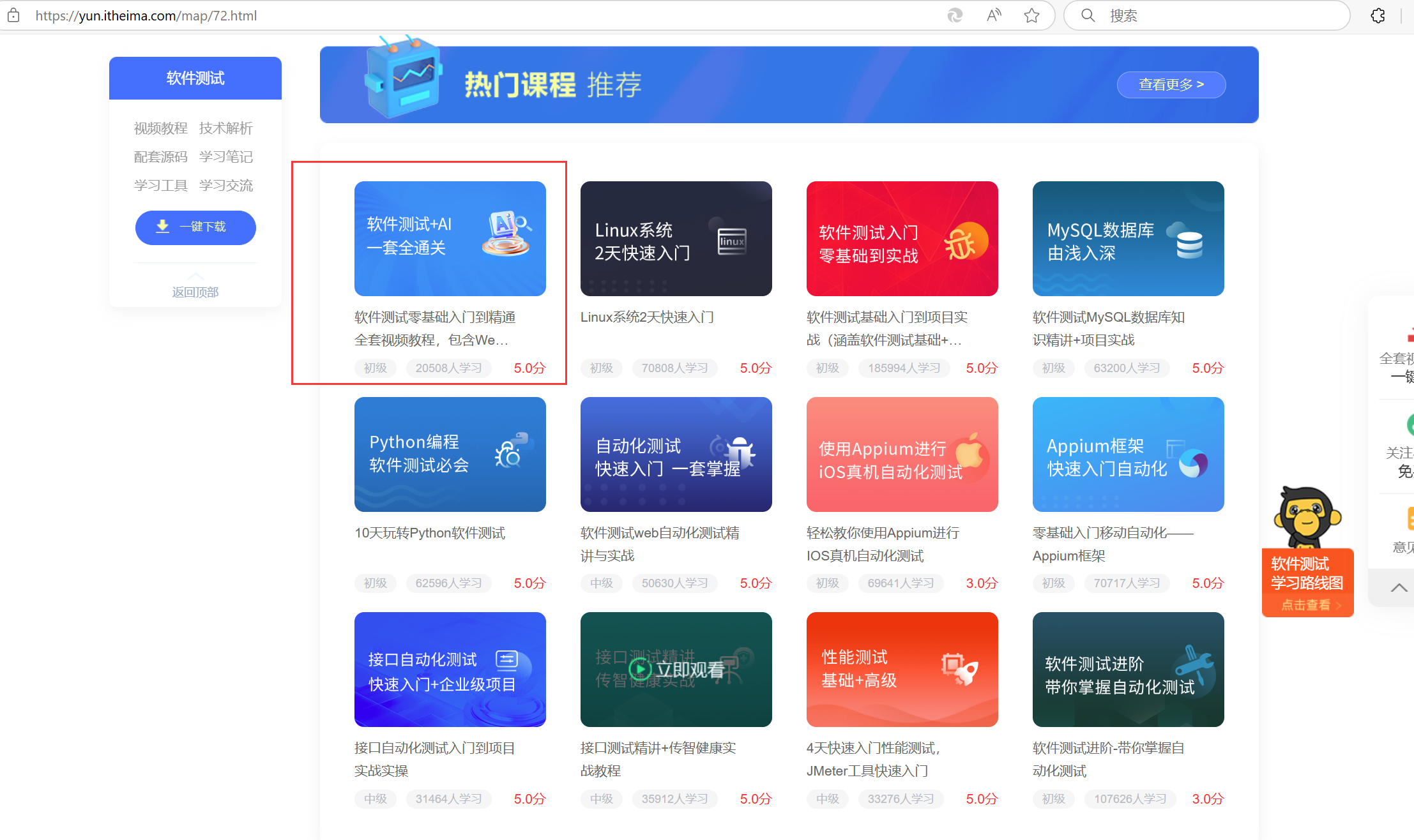
浏览器显示了软件测试视频的相关信息,包括视频名称、学习人数、课程等级、视频评分。通过浏览器开发者工具还可看到视频对应的链接地址。这里的视频名称、学习人数、课程等级、视频评分就是我们需要抓取的目标数据。
4. 定义Item容器;
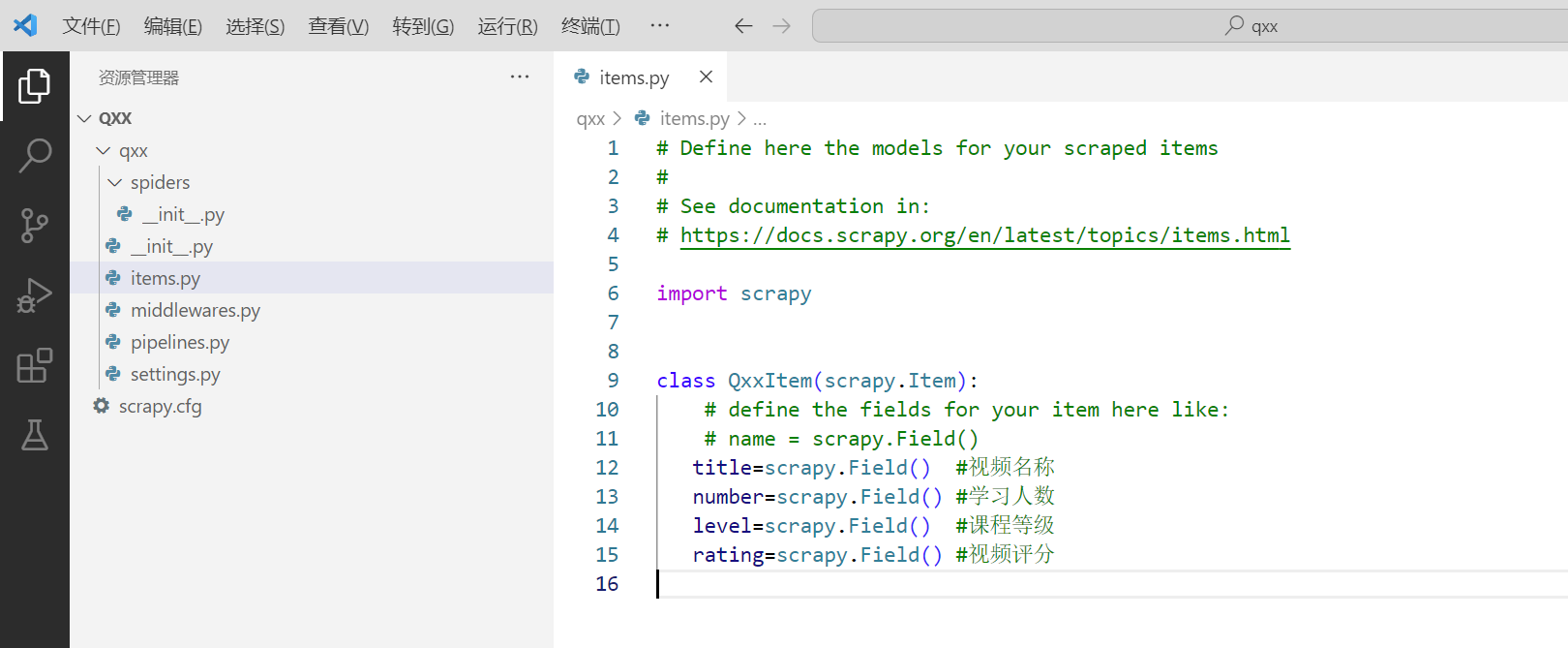
接下来通过 scrapy genspider 命令来创建一个爬虫:
scrapy genspider software_test_info itheima.com
注意:
- itheima.com是黑马程序员官方网站的域名。
- software_test_info 是爬虫的名称。这个名称有以下几点讲究:
唯一性:爬虫名称在项目中必须是唯一的,不能与项目中的其他爬虫名称重复。
命名规范:通常使用小写字母和下划线组合,避免使用大写字母和特殊字符,以符合 Python 的命名规范。
描述性:名称应尽量描述爬虫的功能或目标,以便于理解和管理。例如,software_test_info 表示这个爬虫可能是用于爬取软件测试相关信息的。

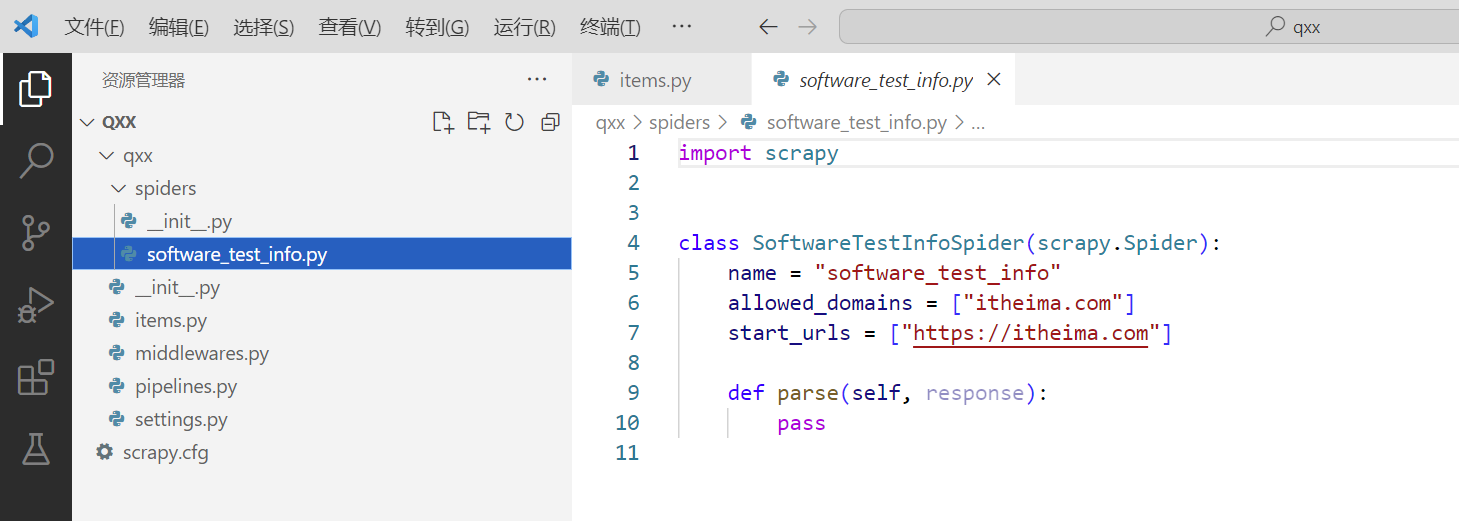
5. 运行Scrapy项目。
import scrapy
from qxx.items import QxxItem
class SoftwareTestInfoSpider(scrapy.Spider):
name = "software_test_info"
allowed_domains = ["itheima.com"]
start_urls = ["https://yun.itheima.com/map/72.html"]
def parse(self, response):
# 选择所有视频信息的节点
node_list = response.xpath('/html/body/div[4]/div[2]/div/div[2]/div[11]//li')
for each in node_list:
item = QxxItem() # 创建 QxxItem 对象
title = each.xpath("./a/h2/text()").get() # 视频名称
number = each.xpath("./a/div[2]/p/text()").get() # 学习人数
level = each.xpath("./a/div[2]/span[1]/text()").get() # 课程等级
rating = each.xpath("./a/div[2]/span[2]/text()").get() # 视频评分
# 将每个视频的信息存储到 item 对象中
item["title"] = title
item["number"] = number
item["level"] = level
item["rating"] = rating
# 使用 yield 返回 item,Scrapy
yield item
确保 QxxItem 类在 qxx.items 模块中定义
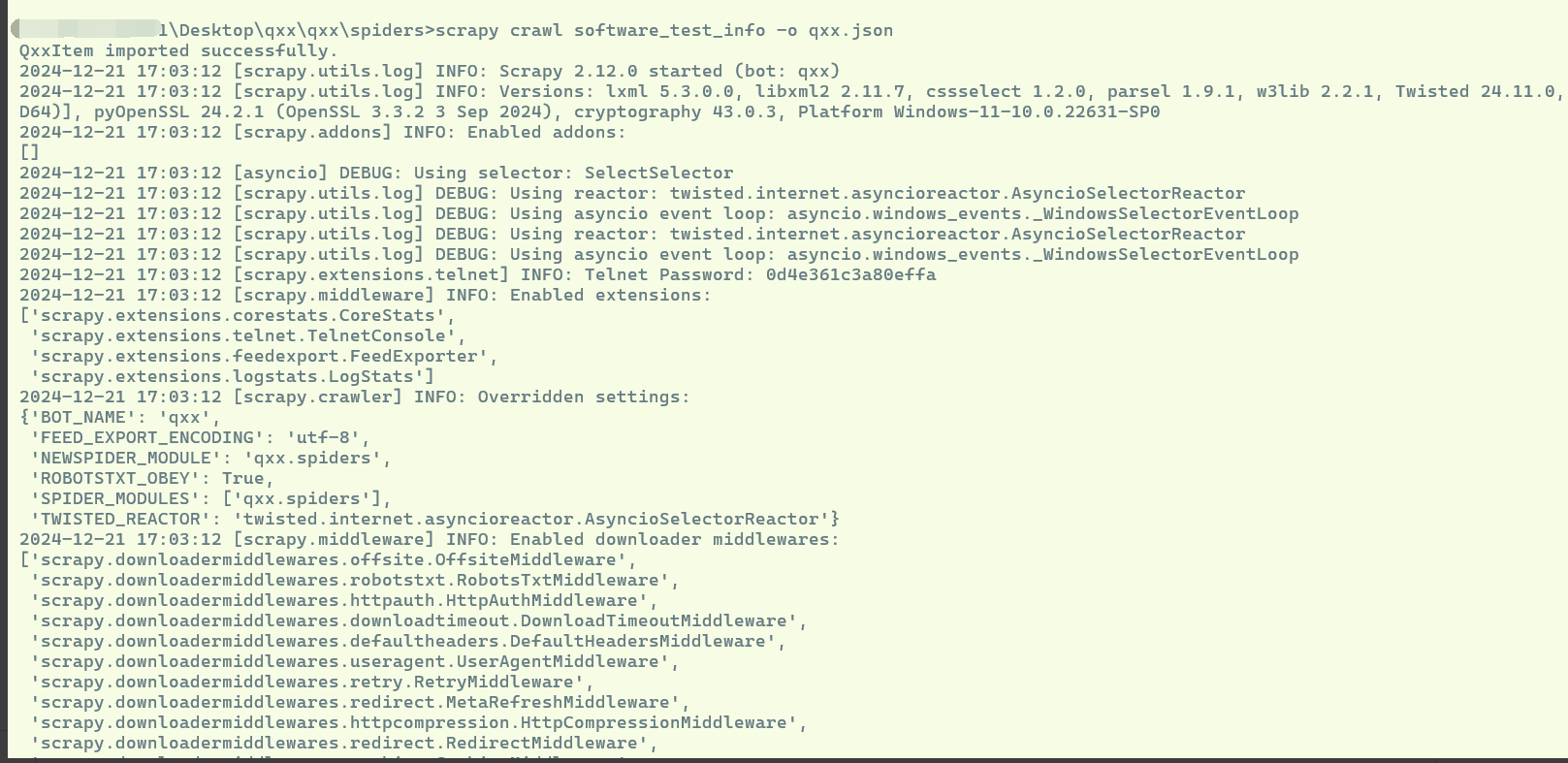
在命令行中运行以下命令来启动爬虫:
scrapy crawl software_test_info -o qxx.json
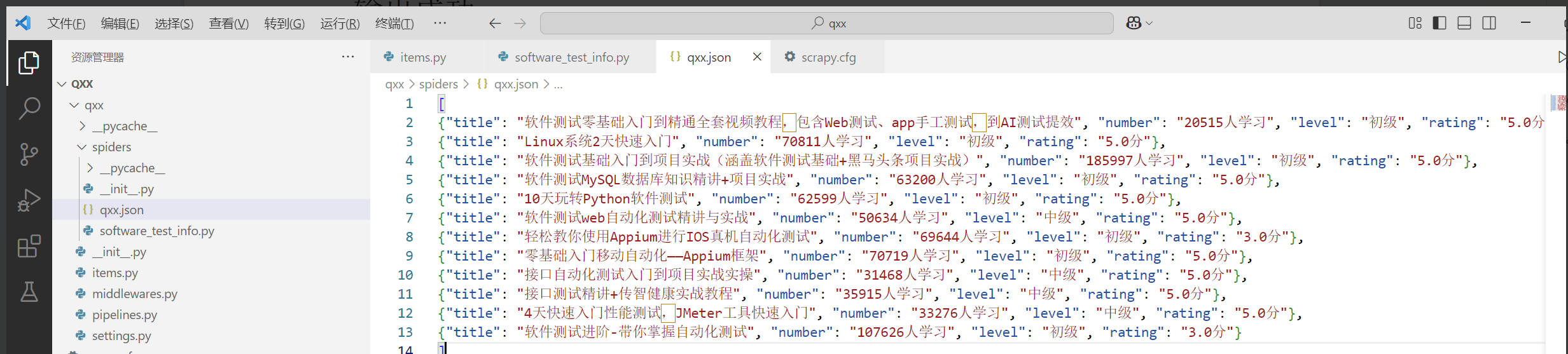
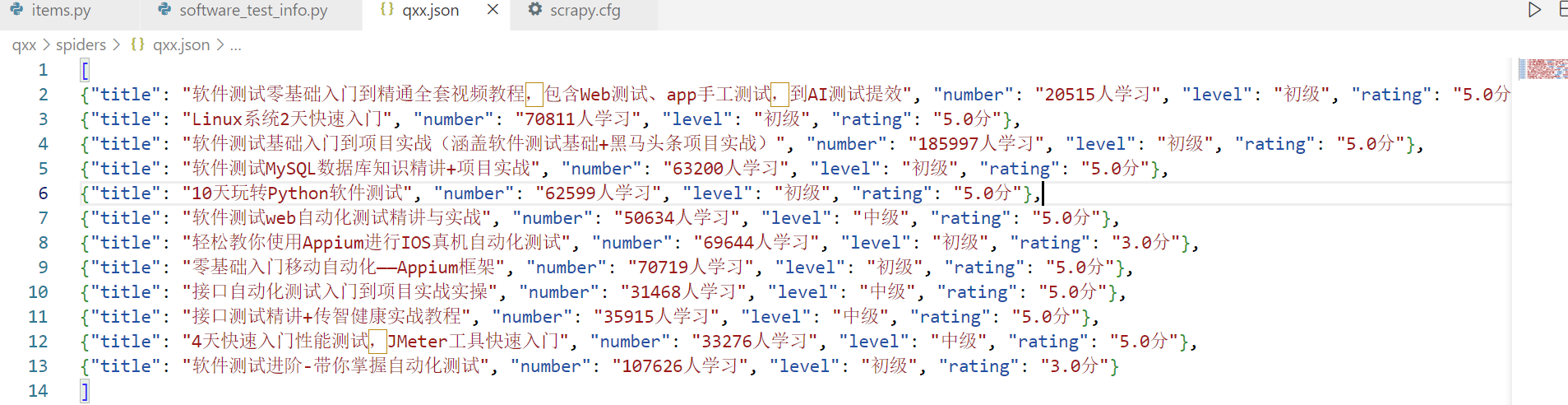
这将启动爬虫并将提取的数据保存到qxx.json文件中。

输出成功


















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









