







一 CodeFormer 优秀的开源修复图片与视频的项目
1 下载
开源地址:https://github.com/sczhou/CodeFormer
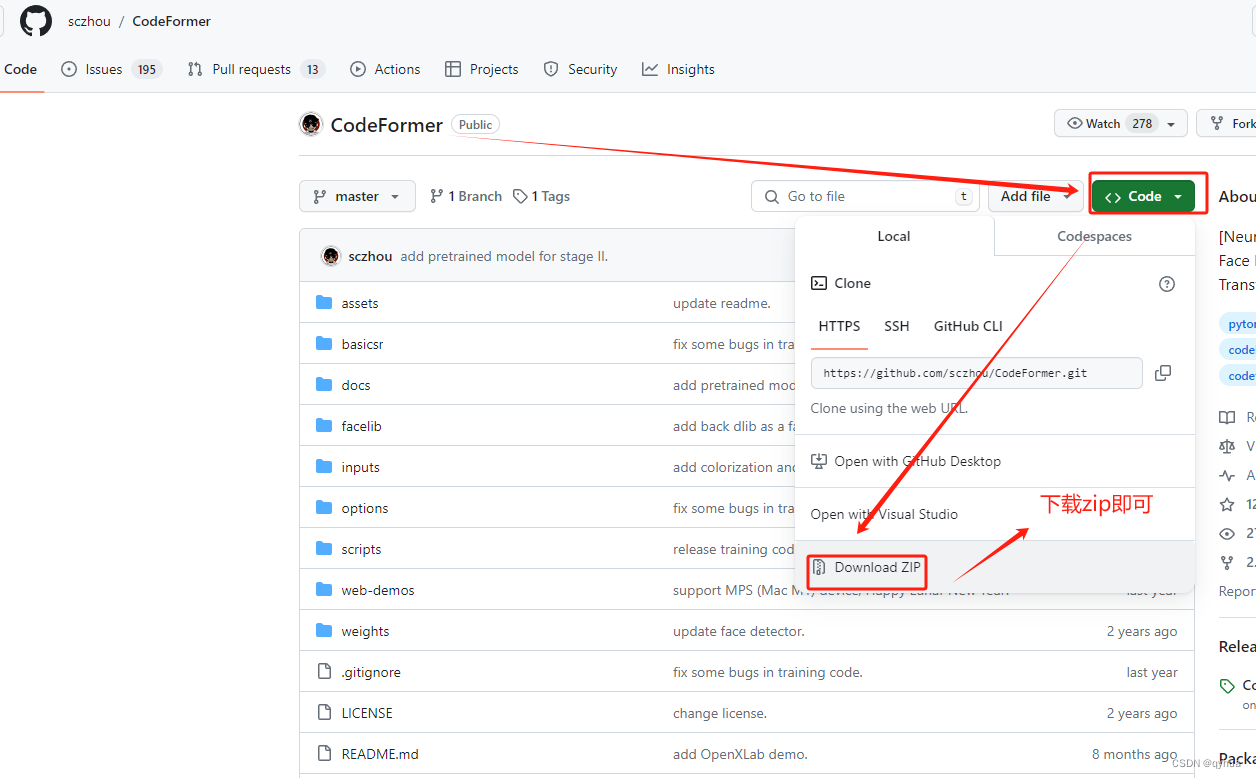
下载成功:
![]()
2 安装
解压进入目录

安装依赖
pip install -r requirements.txt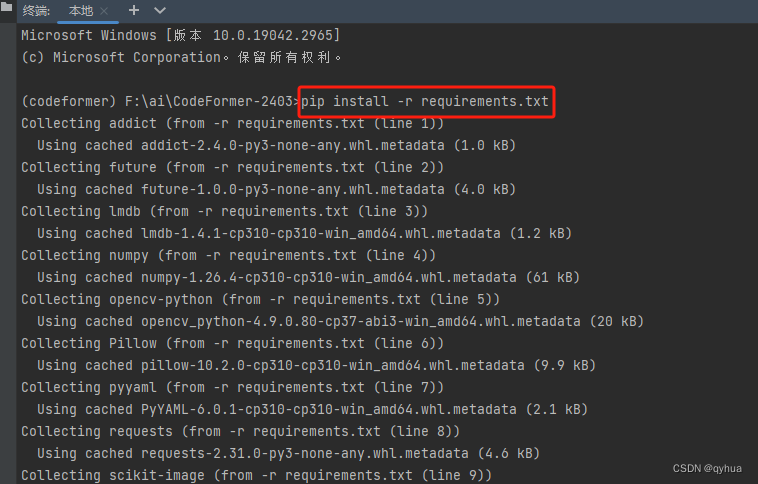 安装完成,测试运行,报了个错误如下:ModuleNotFoundError: No module named 'basicsr.version
安装完成,测试运行,报了个错误如下:ModuleNotFoundError: No module named 'basicsr.version

查看报错的代码位置只是一个引用,代码前后没有用到,直接注释处理如下图:
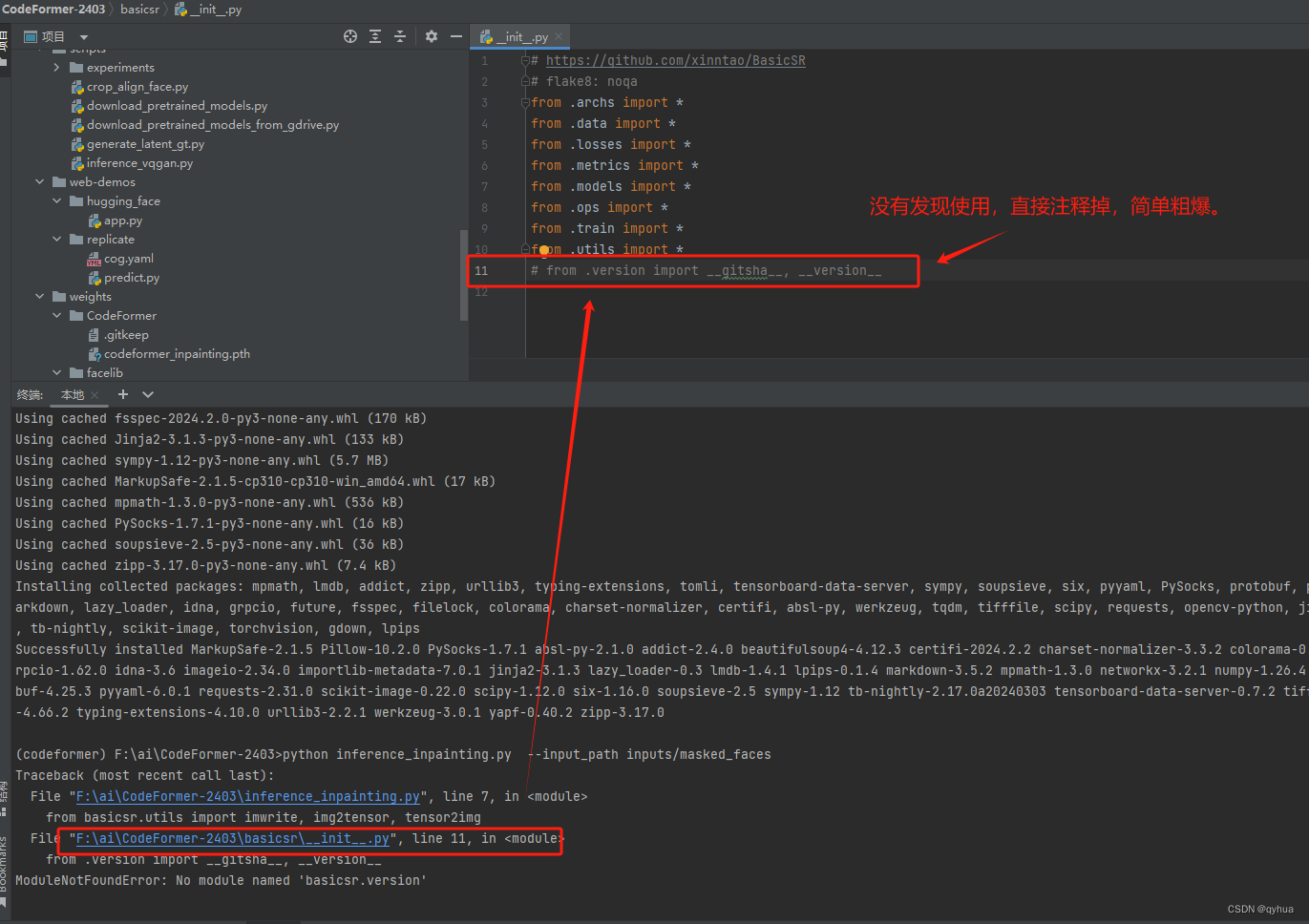 处理后可正常运行项目。
处理后可正常运行项目。
3 使用
a 修复破损图:
执行修复python inference_inpainting.py --input_path inputs/masked_faces 其中--input_path参数可以是要修复的图片目录或文件
python inference_inpainting.py --input_path inputs/masked_faces执行后如下图修复成功(首次执行会联网下载训练好的模型):

这里直接修复项目中示例的5张破损的图片:





执行修复后的效果:





b 模糊修复:
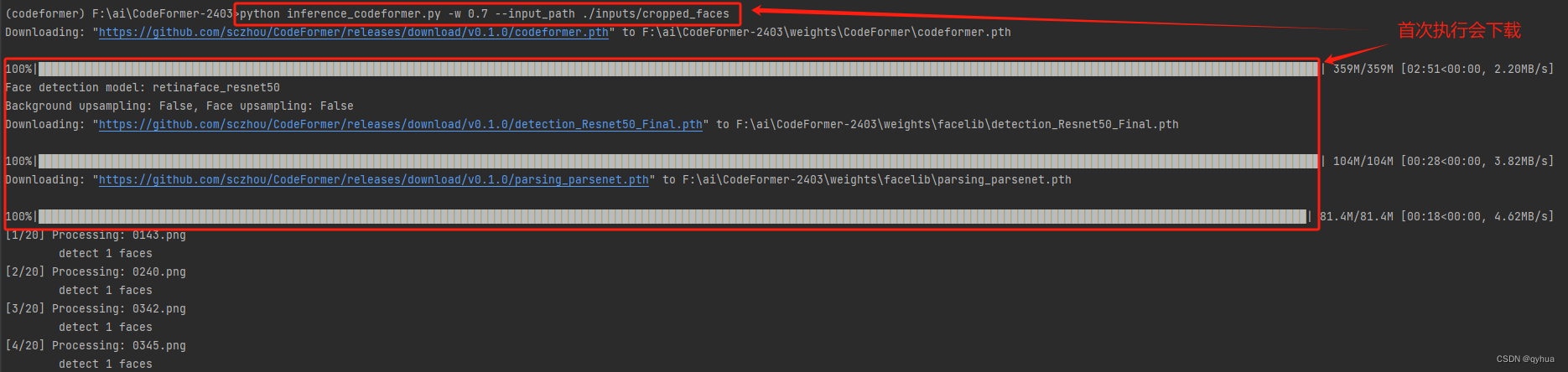
python inference_codeformer.py -w 0.7 --input_path ./inputs/cropped_faces
参数说明
-w 是权重参数
--input_path 输入目录或文件(可以是图片或视频)
python inference_codeformer.py -w 0.7 --input_path ./inputs/cropped_faces执行过程如下图:
修复前的项目示例图:





修复后的项目示例图:





c 灰图上色:
python inference_colorization.py --input_path ./inputs/gray_faces
上色处理前:




上色处理后:























 6489
6489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











