







SSD训练自己的数据集
1、pytorch环境安装即SSD-pytorch代码下载
下载SSD代码:https://github.com/amdegroot/ssd.pytorch
下载模型: https://s3.amazonaws.com/amdegroot-models/vgg16_reducedfc.pth
pyhton3.6
pytorch1.5
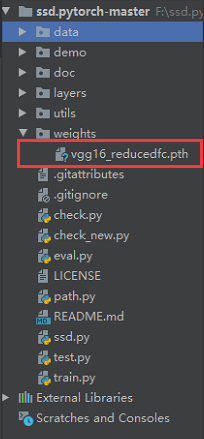
在目录下创建weights文件夹将下好的模型放进去
2、训练集存放
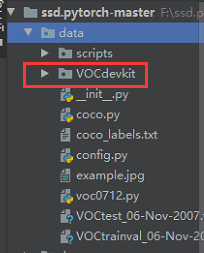
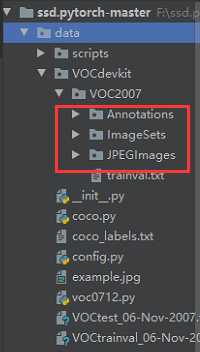
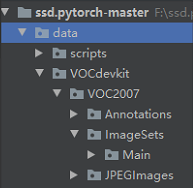
(1)在data下创建VOCdevkit文件夹,在VOCdevkit文件夹下创建VOC2007,再在VOC2007下分别创建Annotations、JPEGImages、ImageSets三个文件,在ImageSets下创建Main文件夹。
(2)选出含有objcet的标签,并将文件名写入trainval.txt中。
import os.path
import xml.etree.ElementTree as ET
import sys
pathh = "F:\\UnderwaterDetection_roundA\\train-A\\box"
for filenames in os.walk(pathh):
filenames = list(filenames)
print(filenames)
filenames = filenames[2]
for filename in filenames:
tree = ET.parse(pathh+'/'+filename)
root = tree.getroot()
obj = root.find('object')
if obj != None:
print(filename)
filename = os.path.splitext(filename)[0]
with open("F:\\UnderwaterDetection_roundA\\train-A\\image\\trainval.txt", 'a') as f:
f.write(filename + '.jpg'+'\n')
f.close()
trainval.txt文件

3、修改数据集相关文件
(1)修改config.py

修改为自己数据集类别数加背景即自己数据集类别数+1,修改你需要迭代的次数。
(2)修改VOC0712.py


将VOC_CLASSES中官方的数据集类别改为自己的数据集的类别。


4、训练与测试评估
(1)修改train.py


(2)修改test.py

(3)修改eval.py
与test.py相同

5、错误
(1)IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python
train_loss += loss.data[0] 是pytorch0.3.1版本代码,在0.4-0.5版本的pytorch会出现警告,不会报错,但是0.5版本以上的pytorch就会报错,总的来说是版本更新问题.
解决办法:修改train.py中的代码

loc_loss += loss_l.data[0]
改为loc_loss += loss_l.item()
conf_loss += loss_c.data[0]
改为conf_loss += loss_c.item()
print('iter ' + repr(iteration) + ' || Loss: %.4f ||' % (loss.data[]), end=' ')
改为print('iter ' + repr(iteration) + ' || Loss: %.4f ||' % (loss.item()), end=' ')
update_vis_plot(iteration, loss_l.item(), loss_c.data[]
iter_plot, epoch_plot, 'append')
改为ate_vis_plot(iteration, loss_l.item(), loss_c.item(),
iter_plot, epoch_plot, 'append')
(2) img, boxes, labels = self.transform(img, target[:, :4], target[:, 4])
IndexError: too many indices for array: array is 1-dimensional, but 2 were indexed
代码中直接跳过了一个类别将类添名加进voc0712.py中的VOC_CLASSES
(3)使用直接的权重报错Missing key(s) in state_dict: 和Unexpected key(s) in state_dict:
因为遇到这种错误,说明训练模型和测试加载模型所使用的环境不一致。原来的vgg16权重数据是直接从guthub上下载的。因此,即使key不匹配,但是value是完全一致的没有问题。是如果使用自己的权重数据的话,需要解决权重数据的key不匹配的问题。添加False后忽略这个问题。
RuntimeError: Error(s) in loading state_dict for ModuleList:
Missing key(s) in state_dict: "0.bias", "0.weight", "2.bias", "2.weight", "5.bias", "5.weight", "7.bias", "7.weight", "10.bias", "10.weight", "12.bias", "12.weight", "14.bias", "14.weight", "17.bias", "17.weight", "19.bias", "19.weight", "21.bias", "21.weight", "24.bias", "24.weight", "26.bias", "26.weight", "28.bias", "28.weight", "31.bias", "31.weight", "33.bias", "33.weight".
Unexpected key(s) in state_dict: "vgg.0.weight", "vgg.0.bias", "vgg.2.weight", "vgg.2.bias", "vgg.5.weight", "vgg.5.bias", "vgg.7.weight", "vgg.7.bias", "vgg.10.weight", "vgg.10.bias", "vgg.12.weight", "vgg.12.bias", "vgg.14.weight", "vgg.14.bias", "vgg.17.weight", "vgg.17.bias", "vgg.19.weight", "vgg.19.bias", "vgg.21.weight", "vgg.21.bias", "vgg.24.weight", "vgg.24.bias", "vgg.26.weight", "vgg.26.bias", "vgg.28.weight", "vgg.28.bias", "vgg.31.weight", "vgg.31.bias", "vgg.33.weight", "vgg.33.bias", "L2Norm.weight", "extras.0.weight", "extras.0.bias", "extras.1.weight", "extras.1.bias", "extras.2.weight", "extras.2.bias", "extras.3.weight", "extras.3.bias", "extras.4.weight", "extras.4.bias", "extras.5.weight", "extras.5.bias", "extras.6.weight", "extras.6.bias", "extras.7.weight", "extras.7.bias", "loc.0.weight", "loc.0.bias", "loc.1.weight", "loc.1.bias", "loc.2.weight", "loc.2.bias", "loc.3.weight", "loc.3.bias", "loc.4.weight", "loc.4.bias", "loc.5.weight", "loc.5.bias", "conf.0.weight", "conf.0.bias", "conf.1.weight", "conf.1.bias", "conf.2.weight", "conf.2.bias", "conf.3.weight", "conf.3.bias", "conf.4.weight", "conf.4.bias", "conf.5.weight", "conf.5.bias".
解决办法将train.py中ssd_net.vgg.load_state_dict(vgg_weights)
改为ssd_net.vgg.load_state_dict(vgg_weights,False)

(4)RuntimeError: Legacy autograd function with non-static forward method is deprecated. Please use new-style autograd function with static forward method. (Example: https://pytorch.org/docs/stable/autograd.html#torch.autograd.Function)
参考https://blog.csdn.net/qq_36926037/article/details/108419899
解决办法:修改ssd.py下
if self.phase == "test":
output = self.detect(
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(conf.size(0), -1,
self.num_classes)), # conf preds
self.priors.type(type(x.data)) # default boxes
)
改为
if self.phase == "test":
output = self.detect.forward(loc.view(loc.size(0), -1, 4),
self.softmax(conf.view(conf.size(0), -1, self.num_classes)),
self.priors.type(type(x.data))
)
修改box_utils.py下nms函数中
在idx = idx[:-1]后插入
idx = torch.autograd.Variable(idx, requires_grad=False)
idx = idx.data
x1 = torch.autograd.Variable(x1, requires_grad=False)
x1 = x1.data
y1 = torch.autograd.Variable(y1, requires_grad=False)
y1 = y1.data
x2 = torch.autograd.Variable(x2, requires_grad=False)
x2 = x2.data
y2 = torch.autograd.Variable(y2, requires_grad=False)
y2 = y2.data

6、参考文献
https://blog.csdn.net/lxy_2011/article/details/99680399
https://blog.csdn.net/qq_36926037/article/details/108419899
https://www.codenong.com/cs109691551/















 6494
6494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









