



 本文介绍了电影推荐系统的基础知识,包括三种主要类型:人口统计过滤、基于内容的过滤和协同过滤。通过TMDB5000电影数据集构建了一个基线推荐系统,详细讲解了数据加载、评分计算、内容相似度和协同过滤的实现。最后讨论了协同过滤中的用户和项目过滤,以及奇异值分解在降低复杂性和稀疏性问题中的应用。
本文介绍了电影推荐系统的基础知识,包括三种主要类型:人口统计过滤、基于内容的过滤和协同过滤。通过TMDB5000电影数据集构建了一个基线推荐系统,详细讲解了数据加载、评分计算、内容相似度和协同过滤的实现。最后讨论了协同过滤中的用户和项目过滤,以及奇异值分解在降低复杂性和稀疏性问题中的应用。
一、推荐系统的时代
数据收集的快速增长带来了一个新的信息时代。数据正被用于创建更高效的系统,而这正是推荐系统发挥作用的地方。推荐系统是一种信息过滤系统,因为它们可以提高搜索结果的质量,并提供与搜索项目更相关或与用户的搜索历史更相关的项目。
它们用于预测用户对某个项目的评分或偏好。几乎每一家大型科技公司都以某种形式应用了它们:亚马逊用它来向客户推荐产品,YouTube用它来决定下一步在autoplay上播放哪个视频,Facebook用它来推荐喜欢的页面和关注的人。此外,像Netflix和Spotify这样的公司在很大程度上依赖其推荐引擎的有效性来实现其业务和成功。
在这个内核中,我们将使用TMDB5000电影数据集构建一个基线电影推荐系统。对于像我这样的新手来说,这个内核将在推荐系统中起到很好的基础作用,并将为您提供一些东西。
那我们走吧!
推荐系统基本上有三种类型:-
人口统计过滤——根据电影人气和/或类型,向每个用户提供一般性建议。该系统向具有相似人口统计特征的用户推荐相同的电影。由于每个用户都是不同的,这种方法被认为太简单了。这一体系背后的基本理念是,更受欢迎、更受好评的电影更容易受到普通观众的喜爱。
基于内容的过滤-他们建议基于特定项目的类似项目。该系统使用项目元数据,例如电影的类型、导演、描述、演员等,来提出这些建议。这些推荐系统背后的一般理念是,如果一个人喜欢某个特定的项目,他或她也会喜欢与之相似的项目。
协同过滤-此系统匹配具有相似兴趣的人,并基于此匹配提供建议。与基于内容的过滤器不同,协作过滤器不需要项目元数据。
二、加载数据
 https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system/data
https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system/dataimport pandas as pd
import numpy as np
df1=pd.read_csv('../input/tmdb-movie-metadata/tmdb_5000_credits.csv')
df2=pd.read_csv('../input/tmdb-movie-metadata/tmdb_5000_movies.csv')第一个数据集包含以下功能:-
电影id-每部电影的唯一标识符。
演员-主角和配角的名字。
剧组-导演、编辑、作曲家、作家等的姓名。
第二个数据集具有以下功能:-
预算-制作电影的预算。
类型-电影、动作片、喜剧、惊悚片等的类型。
主页-电影主页的链接。
id-这实际上是第一个数据集中的电影id。
关键词-与电影相关的关键词或标签。
原创语言-电影制作时使用的语言。
原片名-翻译或改编前的电影片名。
概述-电影的简要描述。
流行度-指定电影流行度的数字量。
制片公司——电影的制片公司。
生产国-生产该产品的国家。
发布日期-发布的日期。
收入-电影产生的全球收入。
runtime—电影的运行时间(分钟)。
状态-“发布”或“传闻”。
标语-电影的标语。
片名——电影的片名。
投票平均-电影的平均收视率。
计票-收到的票数。
让我们将“id”列上的两个数据集连接起来
df1.columns = ['id','tittle','cast','crew']
df2= df2.merge(df1,on='id')人口统计过滤-
在开始之前-
我们需要一个指标来评分或评价电影
计算每部电影的分数
对分数进行排序,并向用户推荐评级最好的电影。
我们可以用电影的平均收视率作为分数,但这样做是不够公平的,因为平均收视率为8.9且只有3票的电影不能被认为比平均收视率为7.8但只有40票的电影更好。因此,我将使用IMDB的加权评级(wr),如下所示:-
哪里
v是电影的票数;
m是图表中列出的最低票数;
R是电影的平均收视率;和
C是整个报告的平均投票数
我们已经有了v(投票计数)和R(投票平均数),C可以计算为
C= df2['vote_average'].mean()因此,所有电影的平均评分在10分制下约为6。下一步是确定m的适当值,即图表中列出的最低投票数。我们将使用第90百分位作为我们的分界点。换句话说,要让一部电影在排行榜上占据一席之地,它必须拥有比列表中至少90%的电影更多的选票。
m= df2['vote_count'].quantile(0.9)现在,我们可以筛选出符合图表要求的电影
q_movies = df2.copy().loc[df2['vote_count'] >= m]
q_movies.shape我们看到有481部电影符合这个名单。现在,我们需要计算每部合格电影的指标。为此,我们将定义一个函数,weighted_rating(),并定义一个新的功能评分,我们将通过将此函数应用于合格电影的数据帧来计算该值:
def weighted_rating(x, m=m, C=C):
v = x['vote_count']
R = x['vote_average']
# 基于IMDB公式的计算
return (v/(v+m) * R) + (m/(m+v) * C)# 定义一个新功能“分数”,并使用“加权评分”(weighted_rating)计算其值`
q_movies['score'] = q_movies.apply(weighted_rating, axis=1)最后,让我们根据分数特性对数据帧进行排序,并输出前10部电影的标题、投票数、投票平均数和加权评级或分数
#根据上面计算的分数对电影进行排序
q_movies = q_movies.sort_values('score', ascending=False)
#Print the top 15 movies
q_movies[['title', 'vote_count', 'vote_average', 'score']].head(10)万岁!我们已经做了我们的第一个(虽然很基本)推荐人。在这些系统的“现在趋势”选项卡下,我们可以找到非常受欢迎的电影,只需按“受欢迎程度”列对数据集进行排序即可获得。
pop= df2.sort_values('popularity', ascending=False)
import matplotlib.pyplot as plt
plt.figure(figsize=(12,4))
plt.barh(pop['title'].head(6),pop['popularity'].head(6), align='center',
color='skyblue')
plt.gca().invert_yaxis()
plt.xlabel("Popularity")
plt.title("Popular Movies")现在需要记住的是,这些人口统计推荐人为所有用户提供了一个推荐电影的通用图表。他们对特定用户的兴趣和品味不敏感。这就是我们转向更精细的系统——基于内容的过滤的时候了。
三、基于内容的过滤
在这个推荐系统中,电影的内容(概述、演员阵容、剧组、关键词、标语等)被用来寻找与其他电影的相似之处。然后推荐最有可能相似的电影。
四、基于图描述的推荐器
我们将根据情节描述计算所有电影的成对相似性分数,并根据该相似性分数推荐电影。数据集的概述功能中给出了绘图描述。让我们看一下数据…
df2['overview'].head(5)对于任何之前做过一点文本处理的人来说,都知道我们需要转换每个概述的单词向量。现在,我们将为每个概述计算术语频率逆文档频率(TF-IDF)向量。
现在,如果您想知道什么是术语频率,那么它是文档中一个单词的相对频率,并以(术语实例/总实例)的形式给出。反向文档频率是包含术语的文档的相对计数,以log(文档数/包含术语的文档数)的形式给出。每个单词对其出现的文档的总体重要性等于TF*IDF
这将为您提供一个矩阵,其中每列表示概述词汇表中的一个单词(至少在一个文档中出现的所有单词),每行表示一部电影,如前所述。这样做是为了降低情节概述中经常出现的单词的重要性,从而降低它们在计算最终相似性分数时的重要性。
幸运的是,scikit learn为您提供了一个内置的TfIdfVectorizer类,该类在几行中生成TF-IDF矩阵。太好了,不是吗?
#Import TfIdfVectorizer from scikit-learn
from sklearn.feature_extraction.text import TfidfVectorizer
#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'
tfidf = TfidfVectorizer(stop_words='english')
#Replace NaN with an empty string
df2['overview'] = df2['overview'].fillna('')
#Construct the required TF-IDF matrix by fitting and transforming the data
tfidf_matrix = tfidf.fit_transform(df2['overview'])
#Output the shape of tfidf_matrix
tfidf_matrix.shape
我们发现,在我们的数据集中,有超过20000个不同的词被用来描述4800部电影。
有了这个矩阵,我们现在可以计算相似性分数了。这方面有几个候选人;例如欧几里得、皮尔逊和余弦相似性分数。对于哪个分数最好,没有正确的答案。不同的分数在不同的场景中效果很好,使用不同的指标进行实验通常是一个好主意。
我们将使用余弦相似性来计算表示两部电影之间相似性的数字量。我们使用余弦相似性分数,因为它与震级无关,并且计算起来相对简单和快速。在数学上,其定义如下:
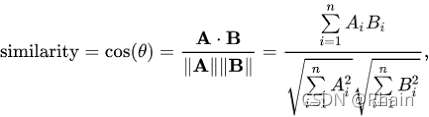
由于我们使用了TF-IDF矢量器,计算点积将直接得到余弦相似性分数。因此,我们将使用sklearn的线性内核()而不是余弦内核(),因为它速度更快。
# Import linear_kernel
from sklearn.metrics.pairwise import linear_kernel
# Compute the cosine similarity matrix
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)我们将定义一个函数,该函数接收电影标题作为输入,并输出10部最相似电影的列表。首先,为此,我们需要电影标题和数据帧索引的反向映射。换句话说,我们需要一种机制来识别元数据数据框中给定电影标题的电影索引。
#Construct a reverse map of indices and movie titles
indices = pd.Series(df2.index, index=df2['title']).drop_duplicates()我们现在可以很好地定义我们的推荐函数。以下是我们将遵循的步骤:-
获取给定电影标题的电影索引。
获取特定电影与所有电影的余弦相似性分数列表。将其转换为元组列表,其中第一个元素是其位置,第二个元素是相似性分数。
根据相似度得分对上述元组列表进行排序;即第二个要素。
获取此列表的前10个元素。忽略第一个元素,因为它指的是自我(与特定电影最相似的电影是电影本身)。
返回与顶部元素的索引相对应的标题。
# Function that takes in movie title as input and outputs most similar movies
def get_recommendations(title, cosine_sim=cosine_sim):
# Get the index of the movie that matches the title
idx = indices[title]
# Get the pairwsie similarity scores of all movies with that movie
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the movies based on the similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar movies
sim_scores = sim_scores[1:11]
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
# Return the top 10 most similar movies
return df2['title'].iloc[movie_indices]get_recommendations('The Dark Knight Rises')
get_recommendations('The Avengers')
虽然我们的系统在寻找情节描述相似的电影方面做得不错,但推荐的质量并不是很好。《黑暗骑士崛起》将返回所有蝙蝠侠电影,而喜欢该电影的人更有可能更喜欢克里斯托弗·诺兰的其他电影。这是当前系统无法捕捉到的。
五、基于信用、类型和关键字的推荐器
不用说,随着更好的元数据的使用,我们的推荐者的质量将会提高。这正是我们在本节要做的。我们将基于以下元数据构建一个推荐器:3位顶级演员、导演、相关类型和电影情节关键词。
从演员、剧组和关键词特征中,我们需要提取三个最重要的演员,导演和与该电影相关的关键词。现在,我们的数据以“字符串化”列表的形式存在,我们需要将其转换为安全和可用的结构
# Parse the stringified features into their corresponding python objects
from ast import literal_eval
features = ['cast', 'crew', 'keywords', 'genres']
for feature in features:
df2[feature] = df2[feature].apply(literal_eval)接下来,我们将编写函数,帮助我们从每个特性中提取所需的信息。
# Get the director's name from the crew feature. If director is not listed, return NaN
def get_director(x):
for i in x:
if i['job'] == 'Director':
return i['name']
return np.nan# Returns the list top 3 elements or entire list; whichever is more.
def get_list(x):
if isinstance(x, list):
names = [i['name'] for i in x]
#Check if more than 3 elements exist. If yes, return only first three. If no, return entire list.
if len(names) > 3:
names = names[:3]
return names
#Return empty list in case of missing/malformed data
return []# Define new director, cast, genres and keywords features that are in a suitable form.
df2['director'] = df2['crew'].apply(get_director)
features = ['cast', 'keywords', 'genres']
for feature in features:
df2[feature] = df2[feature].apply(get_list)# Print the new features of the first 3 films
df2[['title', 'cast', 'director', 'keywords', 'genres']].head(3)下一步是将名称和关键字实例转换为小写,并去掉它们之间的所有空格。这样做是为了我们的矢量器不会将“Johnny Depp”和“Johnny Galecki”中的Johnny计算为相同的值。
# Function to convert all strings to lower case and strip names of spaces
def clean_data(x):
if isinstance(x, list):
return [str.lower(i.replace(" ", "")) for i in x]
else:
#Check if director exists. If not, return empty string
if isinstance(x, str):
return str.lower(x.replace(" ", ""))
else:
return ''
# Apply clean_data function to your features.
features = ['cast', 'keywords', 'director', 'genres']
for feature in features:
df2[feature] = df2[feature].apply(clean_data)我们现在可以创建我们的“元数据汤”,它是一个字符串,包含我们想要提供给向量器的所有元数据(即参与者、导演和关键字)。
def create_soup(x):
return ' '.join(x['keywords']) + ' ' + ' '.join(x['cast']) + ' ' + x['director'] + ' ' + ' '.join(x['genres'])
df2['soup'] = df2.apply(create_soup, axis=1)接下来的步骤与我们使用基于情节描述的推荐器所做的步骤相同。一个重要的区别是我们使用CountVectorizer()而不是TF-IDF。这是因为,如果一个演员/导演在相对较多的电影中表演或导演,我们不想贬低他的存在。这没有什么直观的意义。
# Import CountVectorizer and create the count matrix
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(df2['soup'])
# Compute the Cosine Similarity matrix based on the count_matrix
from sklearn.metrics.pairwise import cosine_similarity
cosine_sim2 = cosine_similarity(count_matrix, count_matrix)
# Reset index of our main DataFrame and construct reverse mapping as before
df2 = df2.reset_index()
indices = pd.Series(df2.index, index=df2['title'])现在,我们可以通过传入新的cosine_sim2矩阵作为第二个参数来重用get_recommendations()函数。
get_recommendations('The Dark Knight Rises', cosine_sim2)get_recommendations('The Godfather', cosine_sim2)我们看到我们的推荐人由于更多的元数据而成功地捕获了更多的信息,并且(可以说)给了我们更好的推荐。惊奇漫画或DC漫画迷更可能喜欢同一家制片公司的电影。因此,我们可以在上述功能的基础上增加生产公司。我们还可以通过在汤中多次添加该功能来增加控制器的重量。
协同过滤
我们基于内容的引擎受到一些严重限制。它只能推荐与某部电影相近的电影。也就是说,它无法捕捉品味并提供跨流派的推荐。
此外,我们构建的引擎并不是真正的个性化引擎,因为它不能捕捉用户的个人喜好和偏见。任何查询我们的引擎以获得基于某部电影的推荐的人,无论她/他是谁,都将收到与该电影相同的推荐。
因此,在本节中,我们将使用一种称为协同过滤的技术向电影观众提出建议。它基本上有两种类型:
基于用户的过滤
-这些系统向类似用户喜欢的用户推荐产品。为了测量两个用户之间的相似性,我们可以使用皮尔逊相关或余弦相似性。这种过滤技术可以用一个例子来说明。在下面的矩阵中,每一行代表一个用户,而列对应不同的电影,除了最后一个记录该用户和目标用户之间的相似性的电影。每个单元格表示用户对该电影的评级。假设用户E是目标。
由于用户A和F与用户E没有任何共同的电影评级,因此它们与用户E的相似性在Pearson相关性中没有定义。因此,我们只需要考虑基于皮尔森相关的用户B、C和D,我们就可以计算出以下相似性。
从上表中我们可以看出,用户D与用户E之间的Pearson相关性为负,因此用户D与用户E非常不同。他在你之前给我的评分高于他的平均评分,而用户E则相反。现在,我们可以开始填写用户没有根据其他用户评价的电影的空白。
虽然计算基于用户的CF非常简单,但它存在几个问题。一个主要问题是用户的偏好会随着时间的推移而改变。这表明基于相邻用户预计算矩阵可能会导致性能下降。为了解决这个问题,我们可以应用基于项目的CF。
基于项目的协同过滤-
基于项目的CF根据项目与目标用户评分的项目的相似性推荐项目,而不是测量用户之间的相似性。同样,相似性可以用皮尔逊相关或余弦相似性计算。主要区别在于,使用基于项目的协同过滤,我们垂直填充空白,与基于用户的CF的水平方式相反。下表显示了如何为电影“我在你面前”执行此操作。
它成功地避免了动态用户偏好带来的问题,因为基于项目的CF更加静态。然而,这种方法仍然存在一些问题。首先,主要问题是可伸缩性。计算量随着客户和产品的增长而增长。最坏情况下的复杂度是O(mn),有m个用户和n个项目。此外,稀疏性是另一个问题。再看一下上面的表格。虽然只有一个用户同时对《黑客帝国》和《泰坦尼克号》进行了评级,但两者之间的相似性为1。在极端情况下,我们可以拥有数百万用户,而两部完全不同的电影之间的相似性可能非常高,这仅仅是因为只有一位用户对这两部电影进行了排名,而这两部电影的排名相似。
单值分解
处理CF产生的可伸缩性和稀疏性问题的一种方法是利用潜在因素模型来捕获用户和项目之间的相似性。本质上,我们希望将推荐问题转化为优化问题。我们可以将其视为我们在预测给定用户的项目评级方面有多好。一个常见的度量是均方根误差(RMSE)。RMSE越低,性能越好。
现在谈到潜在因素,你可能会想知道它是什么?它是一个广义的概念,描述了用户或项目所具有的属性或概念。例如,对于音乐,潜在因素可以指音乐所属的流派。奇异值分解通过提取效用矩阵的潜在因子来降低效用矩阵的维数。本质上,我们将每个用户和每个项目映射到一个维度为r的潜在空间。因此,它有助于我们更好地理解用户和项目之间的关系,因为它们具有直接可比性。下图说明了这一想法。
说得够多了,让我们看看如何实现这一点。因为我们以前使用的数据集没有userId(这对于协作过滤是必需的),所以让我们加载另一个数据集。我们将使用惊奇库来实现SVD。
from surprise import Reader, Dataset, SVD, evaluate
reader = Reader()
ratings = pd.read_csv('../input/the-movies-dataset/ratings_small.csv')
ratings.head()请注意,在这个数据集中,电影的评级为5级,与之前的不同。
data = Dataset.load_from_df(ratings[['userId', 'movieId', 'rating']], reader)
data.split(n_folds=5)
svd = SVD()
evaluate(svd, data, measures=['RMSE', 'MAE'])我们得到的平均根平均平方误差约为0.89,这对于我们的情况来说已经足够好了。现在让我们对数据集进行训练,并得出预测。
trainset = data.build_full_trainset()
svd.fit(trainset)让我们选择用户Id为1的用户,并检查她/他给出的评分。
ratings[ratings['userId'] == 1]svd.predict(1, 302, 3)对于ID为302的电影,我们得到的估计预测值为2.618。这个推荐系统的一个惊人的特点是它不在乎电影是什么(或包含什么)。它完全基于指定的电影ID工作,并尝试根据其他用户对电影的预测来预测收视率。
结论
我们使用人口统计、基于内容和协作过滤创建推荐人。虽然人口统计过滤非常简单,无法实际使用,但混合系统可以利用基于内容的过滤和协作过滤,因为这两种方法几乎是互补的。这个模型是非常基本的,只提供了一个基本的框架。
我想提一下我从中学到的一些很好的参考资料
https://hackernoon.com/introduction-to-recommender-system-part-1-collaborative-filtering-singular-value-decomposition-44c9659c5e75
https://www.kaggle.com/rounakbanik/movie-recommender-systems
http://trouvus.com/wp-content/uploads/2016/03/A-hybrid-movie-recommender-system-based-on-neural-networks.pdf

















 3455
3455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









