








详解python实现FP-TREE进行关联规则挖掘(带有FP树显示功能)附源代码下载(5)
在这一个节我们将谈一谈算法的优化。
一 构造树的优化方法:
1. 垂直数据格式中,diffset法,这些方法在.《数据挖掘 概念与技术》这本书都有提到但都有缺陷,不善于发现长模式(长模式是什么意思?谁来告诉我?)。总之可能用的比较少。
2. 在生成条件模式基的时候,有一种优化算法很实用,叫FPCFB_I,把生成条件模式基的步骤提前了,在一开始,就从树的每个叶子节点开始向上遍历父节点,并且设置相应节点的条件模式基。
二 挖掘树的优化方法:
这就涉及一个重要的概念了,叫闭频集项。
让我们回顾一下在第一节中我们挖掘出的结果:
('chips', 'eggs') 6
('milk', 'chips') 5
('milk', 'bread') 5
('chips', 'bread') 5
('bread', 'eggs') 5
('milk', 'eggs', 'chips') 4
('milk', 'eggs') 4
('chips', 'eggs', 'bread') 4
('milk', 'chips', 'bread') 4
('milk', 'eggs', 'chips', 'bread') 3
('beer', 'bread') 3
('beer', 'eggs') 3
('milk', 'eggs', 'bread') 3
('milk', 'chips') 5
('milk', 'bread') 5
('chips', 'bread') 5
('bread', 'eggs') 5
('milk', 'eggs', 'chips') 4
('milk', 'eggs') 4
('chips', 'eggs', 'bread') 4
('milk', 'chips', 'bread') 4
('milk', 'eggs', 'chips', 'bread') 3
('beer', 'bread') 3
('beer', 'eggs') 3
('milk', 'eggs', 'bread') 3
大家请看标成红色的两条关联结果,你会发现('milk', 'eggs') 4,其实是('milk', 'eggs', 'chips') 4 的"子集",没有必要重复。我们把('milk', 'eggs', 'chips') 4 称为一个闭频集,具体的定义大家去看书吧。在挖掘的过程中,及时发现非闭频集,并进行剪枝是一个很重的优化手段。
《数据挖掘 概念与技术》提到了三种优化手段,分别是项合并,子项集剪枝还有项跳过。
其中可能项跳过比较难于理解,我来试着解释(网上资料实在少,我也不是做学术的,若讲的不对,望高人指正)。请看下面一张图:
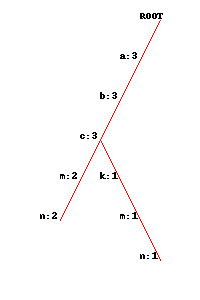
在上面的FP树中,以n为条件基和以 n ,m 为条件基,生成的模式树种,a,b,c的支持度都是3
所以可以得出 结论 没有必要以n,c或n,b或n,a为条件基去挖掘,因为挖掘出的结果必定是 以n,m为条件基的挖掘结果的子集。
这里的a,b,c就相当于书里提到的局部频繁项p,他在倒数第二层和倒数第三层的头表中都有相同的支持度3,可以被剪枝。
这种剪枝方法即所谓“项跳过”。
这种剪枝方法即所谓“项跳过”。
三 分布式挖掘(map-reduce)
大坑,敬请期待
















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











