









行人检测1(总结)
最近一直在看行人检测的论文,对目前的行人检测做大概的介绍。
行人检测具有极其广泛的应用:智能辅助驾驶,智能监控,行人分析以及智能机器人等领域。从2005年以来行人检测进入了一个快速的发展阶段,但是也存在很多问题还有待解决,个人觉得主要还是在性能和速度方面还不能达到一个权衡。
1.行人检测的现状(大概可以分为两类)
(1).基于背景建模:利用背景建模方法,提取出前景运动的目标,在目标区域内进行特征提取,然后利用分类器进行分类,判断是否包含行人;
背景建模目前主要存在的问题:(背景建模的方法总结可以参考我的前一篇博文介绍)(前景目标检测总结)
- 必须适应环境的变化(比如光照的变化造成图像色度的变化);
- 相机抖动引起画面的抖动(比如手持相机拍照时候的移动);
- 图像中密集出现的物体(比如树叶或树干等密集出现的物体,要正确的检测出来);
- 必须能够正确的检测出背景物体的改变(比如新停下的车必须及时的归为背景物体,而有静止开始移动的物体也需要及时的检测出来)。
- 物体检测中往往会出现Ghost区域,Ghost区域也就是指当一个原本静止的物体开始运动,背静差检测算法可能会将原来该物体所覆盖的区域错误的检测为运动的,这块区域就成为Ghost,当然原来运动的物体变为静止的也会引入Ghost区域,Ghost区域在检测中必须被尽快的消除。
(2).基于统计学习的方法:这也是目前行人检测最常用的方法,根据大量的样本构建行人检测分类器。提取的特征主要有目标的灰度、边缘、纹理、颜色、梯度直方图等信息。分类器主要包括神经网络、SVM、adaboost以及现在被计算机视觉视为宠儿的深度学习。
统计学习目前存在的难点:
(a)行人的姿态、服饰各不相同、复杂的背景、不同的行人尺度以及不同的关照环境。
(b)提取的特征在特征空间中的分布不够紧凑;
(c)分类器的性能受训练样本的影响较大;
(d)离线训练时的负样本无法涵盖所有真实应用场景的情况;
目前的行人检测基本上都是基于法国研究人员Dalal在2005的CVPR发表的HOG+SVM的行人检测算法(Histograms of Oriented Gradients for Human Detection, Navneet Dalel,Bill Triggs, CVPR2005)。HOG+SVM作为经典算法也别集成到opencv里面去了,可以直接调用实现行人检测
为了解决速度问题可以采用背景差分法的统计学习行人检测,前提是背景建模的方法足够有效(即效果好速度快),目前获得比较好的检测效果的方法通常采用多特征融合的方法以及级联分类器。(常用的特征有Harry-like、Hog特征、LBP特征、Edgelet特征、CSS特征、COV特征、积分通道特征以及CENTRIST特征。
2.行人检测综述性文章
[1] D. Geronimo, and A. M.Lopez. Vision-based Pedestrian Protection Systems for Intelligent Vehicles, BOOK, 2014.
[2] P.Dollar, C. Wojek,B. Schiele, et al. Pedestrian detection: an evaluation of the state of the art [J].IEEE Transactions on PatternAnalysis andMachine Intelligence, 2012, 34(4): 743-761.
[3]苏松志, 李绍滋, 陈淑媛等. 行人检测技术综述[J]. 电子学报, 2012, 40(4): 814-820.
[4]M. Enzweiler, and D.Gavrila. Monocular pedestrian detection: survey and experiments [J]. IEEE Transactions on Pattern Analysis andMachine Intelligence, 2009, 31(12): 2179-2195.
[5] D. Geronimo, A. M.Lopez and A. D. Sappa, et al. Survey of pedestrian detection for advanced driverassistance systems [J]. IEEE Transactionson Pattern Analysis and Machine Intelligence, 2010, 32(7): 1239-1258.
[6]贾慧星, 章毓晋.车辆辅助驾驶系统中基于计算机视觉的行人检测研究综述[J], 自动化学报, 2007, 33(1): 84-90.
[7] 许言午, 曹先彬,乔红. 行人检测系统研究新进展及关键技术展望[J], 电子学报, 2008, 36(5): 368-376.
[8] 杜友田; 陈峰;徐文立; 李永彬;基于视觉的人的运动识别综述, 电子学报, 2007. 35(1): 84-90.
[9]朱文佳. 基于机器学习的行人检测关键技术研究[D]. 第一章, 硕士学位论文, 上海交通大学. 2008. 指导教师: 戚飞虎.
最新论文
2014_ITS_Toward real-time pedestrian detection based on a deformable template model
2014_PAMI_Scene-specific pedestrian detection for static video surveillance
2014_CVPR_Pedestrian Detection in Low-resolution Imagery by Learning Multi-scale Intrinsic Motion Structures (MIMS)
2014_CVPR_Switchable Deep Network for Pedestrian Detection
2014_CVPR_Informed Haar-like Features Improve Pedestrian Detection
2014_CVPR_Word Channel Based Multiscale Pedestrian Detection Without Image Resizing and Using Only One Classifier
2013_BMVC_Surveillance camera autocalibration based on pedestrian height distribution
2013_Virtual and real world adaptation for pedestrian detection
2013_Search space reduction in pedestrian detection for driver assistance system based on projective geometry
2013_CVPR_Robust Multi-Resolution Pedestrian Detection in Traffic Scenes
2013_CVPR_Optimized Pedestrian Detection for Multiple and Occluded People
2013_CVPR_Pedestrian Detection with Unsupervised and Multi-Stage Feature Learning
2013_CVPR_Single-Pedestrian Detection aided by Multi-pedestrian Detection
2013_CVPR_Modeling Mutual Visibility Relationship in Pedestrian Detection
2013_CVPR_Local Fisher Discriminant Analysis for Pedestrian Re-identification
3.行人检测source code
1.INRIA Object detection and Localization Toolkit, Dalal于2005年提出了基于HOG特征的行人检测方法,行人检测领域中的经典文章之一。HOG特征目前也被用在其他的目标检测与识别、图像检索和跟踪等领域中。
2. Real-time Pedestrian Detection. Jianxin Wu实现的快速行人检测方法。
3. Hough Transfom for Pedestrian Detection. Olga Barinova, CVPR 2010 Paper: On detection of multiple object instances using Hough Transforms
4. HIKSVM, HOG+LBP+HIKSVM, 行人检测的经典方法.
5. GroundHOG, GPU-based Object Detection with Geometric Constraints, In: ICVS, 2011. CUDA版本的HOG+SVM, video.
6. 100FPS_PDS, Pedestrian detection at 100 frames per second, R. Benenson. CVPR, 2012. 实时的(⊙o⊙)哦。 Real-time!!!
7. POM: Probabilistic Occupancy Map. Multiple camera pedestrian detection.
8. Pitor Dollar Detector. Integral Channel Feature + 多尺度特征近似+多特征融合. Real-Time!
4.行人检测DataSets
该数据库为较早公开的行人数据库,共924张行人图片(ppm格式,宽高为64x128),肩到脚的距离约80象素。该数据库只含正面和背面两个视角,无负样本,未区分训练集和测试集。Dalal等采用“HOG+SVM”,在该数据库上的检测准确率接近100%。
该数据库是目前使用最多的静态行人检测数据库,提供原始图片及相应的标注文件。训练集有正样本614张(包含2416个行人),负样本1218张;测试集有正样本288张(包含1126个行人),负样本453张。图片中人体大部分为站立姿势且高度大于100个象素,部分标注可能不正确。图片主要来源于GRAZ-01、个人照片及google,因此图片的清晰度较高。在XP操作系统下部分训练或者测试图片无法看清楚,但可用OpenCV正常读取和显示。
该数据库采用车载摄像机获取,分为检测和分类两个数据集。检测数据集的训练样本集有正样本大小为18x36和48x96的图片各15560(3915x4)张,行人的最小高度为72个象素;负样本6744张(大小为640x480或360x288)。测试集为一段27分钟左右的视频(分辨率为640x480),共21790张图片,包含56492个行人。分类数据库有三个训练集和两个测试集,每个数据集有4800张行人图片,5000张非行人图片,大小均为18x36,另外还有3个辅助的非行人图片集,各1200张图片。
该数据库是目前规模较大的行人数据库,采用车载摄像头拍摄,约10个小时左右,视频的分辨率为640x480,30帧/秒。标注了约250,000帧(约137分钟),350000个矩形框,2300个行人,另外还对矩形框之间的时间对应关系及其遮挡的情况进行标注。数据集分为set00~set10,其中set00~set05为训练集,set06~set10为测试集(标注信息尚未公开)。性能评估方法有以下三种:(1)用外部数据进行训练,在set06~set10进行测试;(2)6-fold交叉验证,选择其中的5个做训练,另外一个做测试,调整参数,最后给出训练集上的性能;(3)用set00~set05训练,set06~set10做测试。由于测试集的标注信息没有公开,需要提交给Pitor Dollar。结果提交方法为每30帧做一个测试,将结果保存在txt文档中(文件的命名方式为I00029.txt I00059.txt ……),每个txt文件中的每行表示检测到一个行人,格式为“[left, top,width, height, score]”。如果没有检测到任何行人,则txt文档为空。该数据库还提供了相应的Matlab工具包,包括视频标注信息的读取、画ROC(Receiver Operatingcharacteristic Curve)曲线图和非极大值抑制等工具。
TUD行人数据库为评估运动信息在行人检测中的作用,提供图像对以便计算光流信息。训练集的正样本为1092对图像(图片大小为720x576,包含1776个行人);负样本为192对非行人图像(手持摄像机85对,车载摄像机107对);另外还提供26对车载摄像机拍摄的图像(包含183个行人)作为附加训练集。测试集有508对图像(图像对的时间间隔为1秒,分辨率为640x480),共有1326个行人。Andriluka等也构建了一个数据库用于验证他们提出的检测与跟踪相结合的行人检测技术。该数据集的训练集提供了行人的矩形框信息、分割掩膜及其各部位(脚、小腿、大腿、躯干和头部)的大小和位置信息。测试集为250张图片(包含311个完全可见的行人)用于测试检测器的性能,2个视频序列(TUD-Campus和TUD-Crossing)用于评估跟踪器的性能。
该数据库是目前规模较大的静态图像行人数据库,25551张含单人的图片,5207张高分辨率非行人图片,数据库中已分好训练集和测试集,方便不同分类器的比较。Overett等用“RealBoost+Haar”评估训练样本的平移、旋转和宽高比等各种因素对分类性能的影响:(1)行人高度至少要大于40个象素;(2)在低分辨率下,对于Haar特征来说,增加样本宽度的性能好于增加样本高度的性能;(3)训练图片的大小要大于行人的实际大小,即背景信息有助于提高性能;(4)对训练样本进行平移提高检测性能,旋转对性能的提高影响不大。以上的结论对于构建行人数据库具有很好的指导意义。
Ess等构建了基于双目视觉的行人数据库用于多人的行人检测与跟踪研究。该数据库采用一对车载的AVT Marlins F033C摄像头进行拍摄,分辨率为640x480,帧率13-14fps,给出标定信息和行人标注信息,深度信息采用置信度传播方法获取。
该数据库目前包含三个数据集(CVC-01、CVC-02和CVC-Virtual),主要用于车辆辅助驾驶中的行人检测研究。CVC-01[Geronimo,2007]有1000个行人样本,6175个非行人样本(来自于图片中公路区域中的非行人图片,不像有的行人数据库非行人样本为天空、沙滩和树木等自然图像)。CVC-02包含三个子数据集(CVC-02-CG、CVC-02-Classification和CVC-02-System),分别针对行人检测的三个不同任务:感兴趣区域的产生、分类和系统性能评估。图像的采集采用Bumblebee2立体彩色视觉系统,分辨率640x480,焦距6mm,对距离摄像头0~50m的行人进行标注,最小的行人图片为12x24。CVC-02-CG主要针对候选区域的产生,有100张彩色图像,包含深度和3D点信息;CVC-02-Classification主要针对行人分类,训练集有1016张正样本,7650张负样本,测试集分为基于切割窗口的分类(570张行人,7500张非行人)和整张图片的检测(250张包含行人的图片,共587个行人);CVC-02-System主要用于系统的性能评估,包含15个视频序列(4364帧),7983个行人。CVC-Virtual是通过Half-Life 2图像引擎产生的虚拟行人数据集,共包含1678虚拟行人,2048个非行人图片用于测试。
该数据库包含三组数据集(USC-A、USC-B和USC-C),以XML格式提供标注信息。USC-A[Wu, 2005]的图片来自于网络,共205张图片,313个站立的行人,行人间不存在相互遮挡,拍摄角度为正面或者背面;USC-B的图片主要来自于CAVIAR视频库,包括各种视角的行人,行人之间有的相互遮挡,共54张图片,271个行人;USC-C有100张图片来自网络的图片,232个行人(多角度),行人之间无相互遮挡。
5.Others
相关资料资料
1. Edgar Seemann维护的行人检测网站,比较全,包括publications, code, datasets等。
2. Pedestrian detection: state of the art. A video talk byPitor Dollar. Pitor Dollar做了很多关于行人检测方法的研究,他们研究小组的Caltech Pedestrian Dataset也很出名。
6.人体行为识别(Human Action Recognition)
来源:http://hi.baidu.com/susongzhi/item/656d196a2dcd733cac3e83e3
1. Statistical and Structural Recognition of Human Actions. ECCV, 2010 Tutorial, by Ivan Laptev and Greg Mori. (注:要用爬墙软件才能访问到)
2. Human Action Recognition in realistic scenarios, 一份很好的硕士生毕业论文开题资料。
参考:http://hi.baidu.com/susongzhi/item/085983081b006311eafe38e7
行人检测在计算机视觉领域的许多应用中起着至关重要的作用,例如视频监控、汽车驾驶员辅助系统、人体的运动捕捉系统等.图像的行人检测方法可以分成两大类:轮廓匹配和表观特征.表观特征又被定义成图像特征空间(也叫做描述算子),它可以分为整体法、局部法、特征点对法.
在整体法中,Papageorgiou和Poggio[1]提出了Haar小波(HWs)特征,并用SVM训练行人,其中包括了行人的正面和背面.Viola和Jones[2, 3]采用级联AdaBoost学习算法(即选择超过一定阈值的弱分类器组成强分类器的算法)提取基本Haar-like特征和扩展的两个Haar-like特征,用于视频监控的行人检测.Levi和Weiss[4]则提出边缘方向直方图(edge orientation histograms,简称EOHs)进行人脸检测.EOHs先计算图像梯度强度,然后按梯度方向等分成K个区间,而特征的表示是通过方向间的统计比得到的一个实数值.Haar-like和EOHs都可以通过图像积分图方法加快运算速度.
Dalal和Triggs等人[5]提出了梯度方向直方图特征(histogram of oriented gradient,简称HOG).HOG基于梯度信息并允许块间相互重叠,因此对光照变化和偏移不敏感,能有效地刻画人体的边缘特征.然而,HOG也有其缺点:特征维度高,大量的重叠和直方图统计,使得特征的计算速度慢,进而影响实时性;遮挡处理能力较差;未利用颜色、形状和纹理等特征.针对这些缺点,近年来一些研究者提出了更多[6, 7, 8, 9]的行人特征,有COV,Integral Channel Feature,ACF,GGP等.
Chen等人[10]提出韦伯特征(Weber local descriptor,简称WLD).WLD由两部分组成:激励(differential excitation)和方向(orientation),其充分利用人类视觉机制韦伯定理,对明暗变化和噪声干扰有一定的鲁棒性,缺点是方向部分计算复杂.
局部法的主要思想是将人体看成是部位的组合,该方法要解决两个问题:构造有效的部位检测器和建模部位间的几何关系.Mohan等人[11]将人体划分为头、下半身、左右胳膊这4个部位,取各个部位分类器的响应值作为支持向量机的输入,构建一个组合的多层次分类器来检测行人.
Edgelet特征描述的是人体的轮廓特征,但是它描述的是人体局部轮廓的特征,包括的形状有直线、弧线等.它将人体分为几个部分来训练,比如全身、头肩部、腿部和躯干部等,每个部分都使用adaboost算法训练一个强分类器;在分类时,利用4个部分的联合概率进行决策.该算法采用的是人体的局部特征,所以在出现遮挡的情况下仍然有很好的表现,缺点是特征的计算比较复杂.
Wu[12]提取图像的edgelet特征用于检测静态图像中的人体,对组成人体的各个部分分别建立模型,每一个edgelet描述人体的某个部位的轮廓,然后再用adaboost算法筛选出最有效的一组edgelet来描述人的整体.
Wu定义了3种edgelet,包括直线型、弧形和对称型.每一个edgelet由一组边缘点构成,是一条具有一定形状和位置的线段.对于图像中任意的位置,根据该位置是否具有和某edgelet形状相似的边缘得到一个响应值.如果边缘的形状与edgelet越相似,那么响应值就越高.
这类方法分别检测窗口的局部区域,然后再综合这些区域的检测结果来做最终的判决.优点在于能更好地处理遮挡以及行人姿势的多样性,主要问题在于如何定义局部以及如何整合来自多个部位检测器的信息.
特征点对法是将行人检测问题视为一个广义的霍夫变换:首先,通过局部特征检测器来寻找关键点;然后,在关键点的周围选取一个固定大小的图像块,通过聚类、随机森林或者最大间隔等方法建立图像块的空间分布模式;最后,通过霍夫投票方式寻找图像中的行人位置.典型的方法是David Lowe提出的SIFT特征[13].
无论是整体、局部还是特征点对法,核心的问题是如何有效表示行人的整体特征、部位特征或者局部块特征.方向梯度直方图特征是目前广泛使用的行人特征表示,但是方向梯度无法刻画人眼视觉敏感度,信息冗余度大.本文针对这一缺点,在中心变换直方图[14]特征(census transform histogram,简称CENTRIST)的基础上,提出一种显著性纹理结构特征,与CENTRIST类似于局部二值模式直方图不同,该特征融合了人眼视觉的心理物理学规律,能更好地实现光照波动、背景杂乱等道路环境下的行人检测.
[1] Papageorgiou C, Poggio T. A trainable system for object detection. Int’l Journal of Computer Vision, 2000,38(1):15-33 .
[2] Viola P, Jones MJ, Snow D. Detecting pedestrians using patterns of motion and appearance. In: Proc. of the Int’l Conf. on Computer Vision. 2003. 734-741 .
[3] Jones MJ, Snow D. Pedestrian detection using boosted features over many frames. In: Proc. of the IEEE Conf. Computer Vision and Pattern Recognition. 2008. 1-4 .
[4] Levi K, Weiss Y. Learning object detection from a small number of examples: The importance of good features. In: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition. 2004.53-60 .
[5] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition. 2005.886-893 .
[6] Tuzel O, Porikli F, Meer P. Pedestrian detection via classification on riemannian manifolds. IEEE Trans. on PAMI, 2008,30(10): 1713-1727 .
[7] Dollar P, Tu Z, Perona P, Belongie S. Integral channel features. In: Proc. of the British Machine Vision Conf. 2009. 1-11.
[8] Gao W, Ai H, Lao S. Adaptive contour features in oriented granular space for human detection and segmentation. In: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition. 2009. 1786-1793 .
[9] Liu YZ, Shan SG, Zhang WC, Chen XL, Gao W. Granularity-Tunable gradients partition (GGP) descriptors for human detection. In: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition. 2009.1255-1262 .
[10] Chen J, Shan SG, He C, Zhao GY. WLD: A robust local image descriptor. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2010, 32(9):1705-1720 .
[11] Mohan A, Papageorgiou C, Poggio T. Example-Based object detection in images by components. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2001,23(4):349-361
[12] Wu B, Nevatia R, Li Y. Segmentation of multiple, partially occluded objects by grouping, merging, assigning part detection responses. Int’l Journal of Computer Vision, 2009,82:185-204 .
[13] Lowe DG. Distinctive image features from scale-invariant keypoints. Int’l Journal of Computer Vision, 2004,60(2):91-l10 .
[14] Wu JX, Rehg JM. CENTRIST: A visual descriptor for scene categorization. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2011,33(8):1489-1501 .
序号
| 文章简介 | 论文 | 出处 | |
| 0 | 2012年PAMI登的行人检测的综述性文章: pedestrian detection an evaluation of the state of the art 作者:Piotr Dollar 文中对比了很多最新的行人检测的算法。这篇论文简称为PAMI2012 | pedestrian detection an evaluation of the state of the art | |
| 1 | PAMI2012综述文章中,排名第一的算法: New Features and Insights for Pedestrian Detection 文中使用改进的HOG,即HOF和CSS(color self similarity)特征,使用HIK SVM分类器。 本文的作者是德国人:Stefen Walk。目前Stefan Walk在苏黎世联邦理工大学任教。 | New features and insights for pedestrian detection
| https://www.d2.mpi-inf.mpg.de/CVPR10Pedestrians
|
| 2 | PAMI2012综述文章中,排名第2的算法: 加州理工学院2009年行人检测的文章:Integral Channel Features(积分通道特征) 这篇文章与2012年PAMI综述文章是同一作者。 作者:Piotr Dollar
| Integral channel features
| http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/ 各种行人检测的库和演示代码 Matlab代码中包含完整的训练和测试的算法源码。压缩包里面的代码包含了作者几乎所有论文中讲到的算法,其中,作者最新的PAMI2014论文的代码也包含在这个压缩包里面。 |
| 3 | PAMI2012综述文章中,排名第3的算法 The Fastest Pedestrian Detector in the West 这篇文章与2012年PAMI综述文章是同一作者。 作者:Piotr Dollar | The Fastest Pedestrian Detector in the West | 文章作者的主页: http://vision.ucsd.edu/~pdollar/research.html 文章中算的matlab代码下载页面: |
| 4 |
作者Piotr Dollar于2009年写的行人检测的文章 | Pedestrian Detection A Benchmark . | |
| 5 | CVPR2008: A Discriminatively Trained, Multiscale, Deformable Part Model
PAMI2010: Object Detection with Discriminatively Trained Part Based Models
CVPR2010: Cascade Object Detection with Deformable Part Models
以上三篇文章,都是作者研究DPM算法做目标检测的文章,有源代码可以下载。在PAMI2012综述文章中,没有提及这个算法,不知道什么原因。 | A Discriminatively Trained, Multiscale, Deformable Part Model
Object Detection with Discriminatively Trained Part Based Models
Cascade Object Detection with Deformable Part Models
| 作者的个人主页: |
| 6 | IJCV2014年的文章,利用DPM模型,检测粘连情况很严重的行人,效果很好。 | Detection and Tracking of Occluded People | 目前找不到该论文相关的源码。 |
| 7 | ICCV2013: 简 称UDN算法,从文中描述的检测效果来看,该方法是所有方法中最好的,并且,效果远超过其他方法。经过对论文和该算法源码的研究,该算法是与作者另外一篇 论文的方法 ,另外的论文算法做图片扫描,得到矩形框,然后用该方法对矩形框进行进一步确认,以及降低误警率和漏警率。另外的论文是:Multi-Stage Contextual Deep Learning for Pedestrian Detection
说得难听一点,这篇文章对行人检测没有多大的贡献。仅仅是用深度学习的CNN做candidate window的确认。而主要的行人检测的算法还是HOG+CSS+adaboost | Joint Deep Learning for Pedestrian Detection
Multi-Stage Contextual Deep Learning for Pedestrian Detection
|
香港中文大学,Joint Deep Learning for Pedestrian Detection,行人检测论文的相关资源: http://www.ee.cuhk.edu.hk/~wlouyang/projects/ouyangWiccv13Joint/index.html |
| 8 | ECCV2010年的论文: Multiresolution models for object detection 文中描述的算法效果相当好,但是,作者没有公布源码。不知道论文中的效果是否属实。 | Multiresolution models for object detection | Multires算法检测行人,作者的个人主页: http://www.ics.uci.edu/~iypark/ 作者未公布源代码,也没有公布demo |
| 9 | ICCV2009年的论文,检测效果与Piotr Dollar的效果可以匹敌。作者只公布了测试软件,并没有公布源码。 文中采用HOG+LBP特征,这种特征,与Centrist特征类似,能够描述人体全局轮廓,都具有较好的检测效果。 | An HOG-LBP Human Detector with Partial Occlusion Handling
| http://vision.ece.missouri.edu/~wxy/index.html http://web.missouri.edu/~hantx/
|
| 10 | 使用Centrist特征,Centrist是LBP特征的改进。作者将Centrist特征与HOG、LBP特征做了比较,证明Centtrist特征在描述行人方面,具有很好的效果。 作者是华人,在南阳理工读的博士。个人理解,Centrist特征没有多大的创新,与LBP并没有太大的差异。作者自己也在文中表示,算法的效果没有HOG和LBP好,仅仅是算法的速度较快。 | Real-Time Human Detection Using Contour Cues
| 源码中只有测试源码,没有训练分类器的代码。 http://www.c2i.ntu.edu.sg/jianxin/projects/C4/C4.htm
|
总体上来说,这些最新的文章中,最好的有三个方面的方法:
1)改进的HOG+改进的SVM。也就是PAMI2012中排名第一的论文中的方法。可惜找不到源码。
2) HOF+CSS+adaboost.。也就是PAMI2012中排名第二的方法。能找到matlab源码。
3) HOG+LBP+SVM方法。也就是上表中序号为9的论文中的方法。没有源码。
4) DPM。也就是上表中序号5、6中的方法,有源码。
原文:http://blog.csdn.net/dpstill/article/details/22420065
参考原文: http://blog.csdn.net/zouxy09/article/details/7929531
http://www.cnblogs.com/dwdxdy/archive/2012/05/31/2528941.html
http://blog.csdn.net/dujian996099665/article/details/8886576
LBP(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的优点。它是首先由T. Ojala, M.Pietikäinen, 和 D. Harwood 在1994年提出,用于纹理特征提取。而且,提取的特征是图像的局部的纹理特征;在行人检测中HOG+LBP+HIKSVM取得了不错的效果,在人脸识别中也是广泛应用。
1、LBP特征的描述
原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。如下图所示:
LBP的改进版本:
原始的LBP提出后,研究人员不断对其提出了各种改进和优化。
(1)圆形LBP算子:
基本的 LBP算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。为了适应不同尺度的纹理特征,并达到灰度和旋转不变性的要求,Ojala等对 LBP 算子进行了改进,将 3×3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的 LBP 算子允许在半径为 R 的圆形邻域内有任意多个像素点。从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子;

(2)LBP旋转不变模式
从 LBP 的定义可以看出,LBP 算子是灰度不变的,但却不是旋转不变的。图像的旋转就会得到不同的 LBP值。
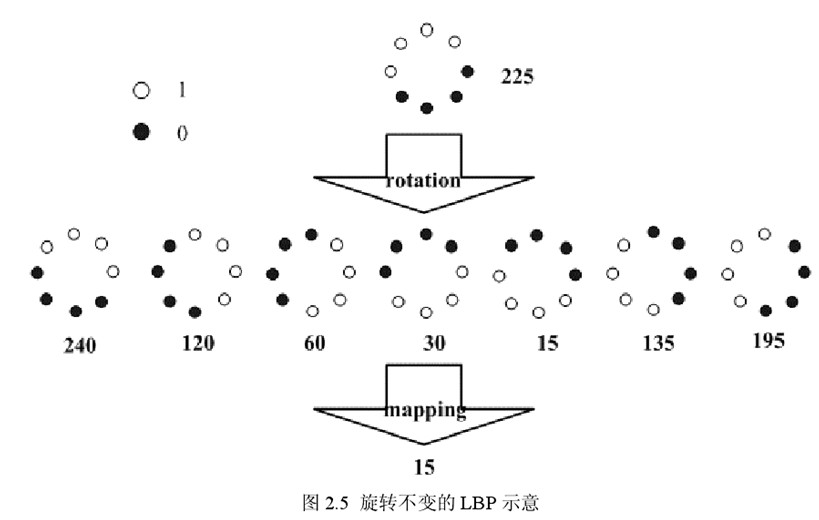
Maenpaa等人又将 LBP算子进行了扩展,提出了具有旋转不变性的 LBP 算子,即不断旋转圆形邻域得到一系列初始定义的 LBP值,取其最小值作为该邻域的 LBP 值。
图 2.5 给出了求取旋转不变的 LBP 的过程示意图,图中算子下方的数字表示该算子对应的 LBP值,图中所示的 8 种 LBP模式,经过旋转不变的处理,最终得到的具有旋转不变性的 LBP值为 15。也就是说,图中的 8种 LBP 模式对应的旋转不变的 LBP模式都是 00001111。
一个更加正式的LBP操作可以被定义为

其中 是中心像素,亮度是
是中心像素,亮度是 ;而
;而  则是相邻像素的亮度。s是一个符号函数:
则是相邻像素的亮度。s是一个符号函数:

这种描述方法使得你可以很好的捕捉到图像中的细节。实际上,研究者们可以用它在纹理分类上得到最先进的水平。正如刚才描述的方法被提出后,固定的近邻区域对于尺度变化的编码失效。所以,使用一个变量的扩展方法,在文献[AHP04]中有描述。主意是使用可变半径的圆对近邻像素进行编码,这样可以捕捉到如下的近邻:

对一个给定的点 ,他的近邻点
,他的近邻点  可以由如下计算:
可以由如下计算:

其中,R是圆的半径,而P是样本点的个数。
这个操作是对原始LBP算子的扩展,所以有时被称为扩展LBP(又称为圆形LBP)。如果一个在圆上的点不在图像坐标上,我们使用他的内插点。计算机科学有一堆聪明的插值方法,而OpenCV使用双线性插值。

(3)LBP等价模式(ULBP)
一个LBP算子可以产生不同的二进制模式,对于半径为R的圆形区域内含有P个采样点的LBP算子将会产生P2种模式。很显然,随着邻域集内采样点数的增加,二进制模式的种类是急剧增加的。例如:5×5邻域内20个采样点,有220=1,048,576种二进制模式。如此多的二值模式无论对于纹理的提取还是对于纹理的识别、分类及信息的存取都是不利的。同时,过多的模式种类对于纹理的表达是不利的。例如,将LBP算子用于纹理分类或人脸识别时,常采用LBP模式的统计直方图来表达图像的信息,而较多的模式种类将使得数据量过大,且直方图过于稀疏。因此,需要对原始的LBP模式进行降维,使得数据量减少的情况下能最好的代表图像的信息。
为了解决二进制模式过多的问题,提高统计性,Ojala提出了采用一种“等价模式”(Uniform Pattern)来对LBP算子的模式种类进行降维。Ojala等认为,在实际图像中,绝大多数LBP模式最多只包含两次从1到0或从0到1的跳变。因此,Ojala将“等价模式”定义为:当某个LBP所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该LBP所对应的二进制就称为一个等价模式类。如00000000(0次跳变),00000111(只含一次从0到1的跳变),10001111(先由1跳到0,再由0跳到1,共两次跳变)都是等价模式类。除等价模式类以外的模式都归为另一类,称为混合模式类,例如10010111(共四次跳变)(这是我的个人理解,不知道对不对)。
通过这样的改进,二进制模式的种类大大减少,而不会丢失任何信息。模式数量由原来的2P种减少为 P ( P-1)+2种,其中P表示邻域集内的采样点数。对于3×3邻域内8个采样点来说,二进制模式由原始的256种减少为58种,这使得特征向量的维数更少,并且可以减少高频噪声带来的影响。
2、LBP特征用于检测的原理
显而易见的是,上述提取的LBP算子在每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(记录的是每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(记录的是每个像素点的LBP值)。

LBP的应用中,如纹理分类、人脸分析等,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
因为,从上面的分析我们可以看出,这个“特征”跟位置信息是紧密相关的。直接对两幅图片提取这种“特征”,并进行判别分析的话,会因为“位置没有对准”而产生很大的误差。后来,研究人员发现,可以将一幅图片划分为若干的子区域,对每个子区域内的每个像素点都提取LBP特征,然后,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述;整个图片就由若干个统计直方图组成;
例如:一幅100*100像素大小的图片,划分为10*10=100个子区域(可以通过多种方式来划分区域),每个子区域的大小为10*10像素;在每个子区域内的每个像素点,提取其LBP特征,然后,建立统计直方图;这样,这幅图片就有10*10个子区域,也就有了10*10个统计直方图,利用这10*10个统计直方图,就可以描述这幅图片了。之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了;
3、对LBP特征向量进行提取的步骤
(1)首先将检测窗口划分为16×16的小区域(cell);
(2)对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样, 3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值;
(3)然后计算每个cell的直方图,即每个数字(假定是十进制数LBP值)出现的频率;然后对该直方图进行归一化处理。
(4)最后将得到的每个cell的统计直方图进行连接成为一个特征向量,也就是整幅图的LBP纹理特征向量;
然后便可利用SVM或者其他机器学习算法进行分类了。
Reference:
黄非非,基于 LBP 的人脸识别研究,重庆大学硕士学位论文,2009.5
4.LBP的扩展DLBP
参考文献 Background Subtraction Based on a Combination of Texture,Color and Intensity ICSP 2008
文献在LBP的基础上,提出了DLBP特征 Double Local Binary Pattern.
LBP的缺点:
1).It cannot differeniate between ascending and homogeneous.
无法区分邻域像素点与中心像素点相等,或者邻域像素点大于中心像素点两种情况,因此,这两种情况所得都是s(u) = 1.
2).It is sensitive to noise due its threshold schem.
DLBP主要是为了解决LBP的缺点而提出的,表式形式如下:

当LBP+ = 0 且 LBP- = 0,表示邻域像素点与中心像素点相同;
当LBP+ = 1 且 LBP- = 0时,表示邻域像素点大于中心像素点;
当LBP+ = 0 且 LBP- = 1时,表示邻域像素点小于中心像素点;
从而可以区分邻域像素点与中心像素点的三种情况.
引入参数n,来改善像素点值轻微变化对LBP的影响.文中取n = 4.
LBP和DLBP的比较示例图如下:

(b),(c),(d)利用DLBP更能表述图像的特征.(a)中DLBP和LBP的表描结果是一样的.
5.原始LBP算法的opencv实现

// LBP.cpp : 定义控制台应用程序的入口点。
//
/***********************************************************************
* OpenCV 2.4.4 测试例程
* 杜健健 提供
***********************************************************************/
#include "stdafx.h"
#include <opencv2/opencv.hpp>
#include <cv.h>
#include <highgui.h>
#include <cxcore.h>
using namespace std;
using namespace cv;
//原始的LBP算法
//使用模板参数
template <typename _Tp> static
void olbp_(InputArray _src, OutputArray _dst) {
// get matrices
Mat src = _src.getMat();
// allocate memory for result
_dst.create(src.rows-2, src.cols-2, CV_8UC1);
Mat dst = _dst.getMat();
// zero the result matrix
dst.setTo(0);
cout<<"rows "<<src.rows<<" cols "<<src.cols<<endl;
cout<<"channels "<<src.channels();
getchar();
// calculate patterns
for(int i=1;i<src.rows-1;i++) {
cout<<endl;
for(int j=1;j<src.cols-1;j++) {
_Tp center = src.at<_Tp>(i,j);
//cout<<"center"<<(int)center<<" ";
unsigned char code = 0;
code |= (src.at<_Tp>(i-1,j-1) >= center) << 7;
code |= (src.at<_Tp>(i-1,j ) >= center) << 6;
code |= (src.at<_Tp>(i-1,j+1) >= center) << 5;
code |= (src.at<_Tp>(i ,j+1) >= center) << 4;
code |= (src.at<_Tp>(i+1,j+1) >= center) << 3;
code |= (src.at<_Tp>(i+1,j ) >= center) << 2;
code |= (src.at<_Tp>(i+1,j-1) >= center) << 1;
code |= (src.at<_Tp>(i ,j-1) >= center) << 0;
dst.at<unsigned char>(i-1,j-1) = code;
//cout<<(int)code<<" ";
//cout<<(int)code<<endl;
}
}
}
//基于旧版本的opencv的LBP算法opencv1.0
void LBP (IplImage *src,IplImage *dst)
{
int tmp[8]={0};
CvScalar s;
IplImage * temp = cvCreateImage(cvGetSize(src), IPL_DEPTH_8U,1);
uchar *data=(uchar*)src->imageData;
int step=src->widthStep;
cout<<"step"<<step<<endl;
for (int i=1;i<src->height-1;i++)
for(int j=1;j<src->width-1;j++)
{
int sum=0;
if(data[(i-1)*step+j-1]>data[i*step+j])
tmp[0]=1;
else
tmp[0]=0;
if(data[i*step+(j-1)]>data[i*step+j])
tmp[1]=1;
else
tmp[1]=0;
if(data[(i+1)*step+(j-1)]>data[i*step+j])
tmp[2]=1;
else
tmp[2]=0;
if (data[(i+1)*step+j]>data[i*step+j])
tmp[3]=1;
else
tmp[3]=0;
if (data[(i+1)*step+(j+1)]>data[i*step+j])
tmp[4]=1;
else
tmp[4]=0;
if(data[i*step+(j+1)]>data[i*step+j])
tmp[5]=1;
else
tmp[5]=0;
if(data[(i-1)*step+(j+1)]>data[i*step+j])
tmp[6]=1;
else
tmp[6]=0;
if(data[(i-1)*step+j]>data[i*step+j])
tmp[7]=1;
else
tmp[7]=0;
//计算LBP编码
s.val[0]=(tmp[0]*1+tmp[1]*2+tmp[2]*4+tmp[3]*8+tmp[4]*16+tmp[5]*32+tmp[6]*64+tmp[7]*128);
cvSet2D(dst,i,j,s);写入LBP图像
}
}
int _tmain(int argc, _TCHAR* argv[])
{
//IplImage* face = cvLoadImage("D://input//yalefaces//01//s1.bmp",CV_LOAD_IMAGE_ANYDEPTH | CV_LOAD_IMAGE_ANYCOLOR);
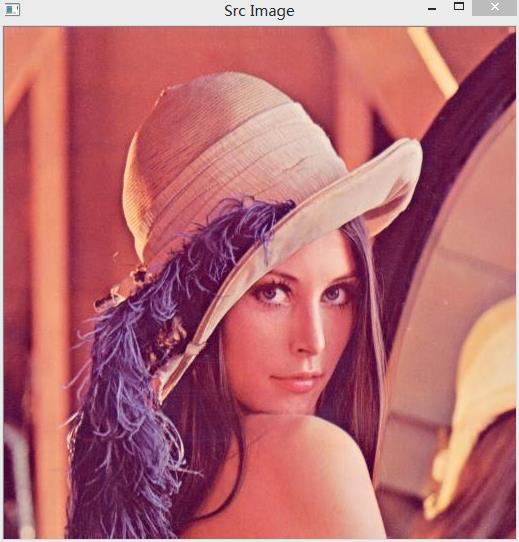
IplImage* face = cvLoadImage("D://input//lena.jpg",CV_LOAD_IMAGE_ANYDEPTH | CV_LOAD_IMAGE_ANYCOLOR);
//IplImage* lbp_face = cvCreateImage(cvGetSize(face), IPL_DEPTH_8U,1);
IplImage* Gray_face = cvCreateImage( cvSize( face->width,face->height ), face->depth, 1);//先分配图像空间
cvCvtColor(face, Gray_face ,CV_BGR2GRAY);//把载入图像转换为灰度图
IplImage* lbp_face = cvCreateImage(cvGetSize(Gray_face), IPL_DEPTH_8U,1);//先分配图像空间
cvNamedWindow("Gray Image",1);
cvShowImage("Gray Image",Gray_face);
//Mat face2 = imread("D://input//buti.jpg",CV_LOAD_IMAGE_ANYDEPTH | CV_LOAD_IMAGE_ANYCOLOR);
Mat face2 = imread("D://input//yalefaces//01//s1.bmp",CV_LOAD_IMAGE_ANYDEPTH | CV_LOAD_IMAGE_ANYCOLOR);
//Mat Gray_face2 = Mat::zeros(face2.size(),IPL_DEPTH_8U,1);
//cvCvtColor(face2,Gray_face2,CV_BGR2RAY);
Mat lbp_face2 = Mat::zeros(face2.size(),face2.type()) ;
//Mat::copyTo(lbp_face,face);
//显示原始的输入图像
cvNamedWindow("Src Image",CV_WINDOW_AUTOSIZE);
cvShowImage("Src Image",face);
//imshow("Src Image",face);
//计算输入图像的LBP纹理特征
LBP(Gray_face,lbp_face);
//olbp_<uchar>((Mat)face,(Mat)lbp_face);//有问题的调用
olbp_<uchar>(face2,lbp_face2);
//显示第一幅图像的LBP纹理特征图
cvNamedWindow("LBP Image",CV_WINDOW_AUTOSIZE);
cvShowImage("LBP Image",lbp_face);
//显示第二幅图 的LBP纹理特征图-一张yaleface人脸库中的人脸LBP特征图
namedWindow("LBP Image2",1);
imshow("LBP Image2",lbp_face2);
waitKey();
//cvReleaseImage(&face);
cvDestroyWindow("Src Image");
return 0;
}
结果:
原始图像lena.jpg
变换成灰度图后:

提取图片的LBP特征:

提取人脸图像的LBP特征;
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









