






背景需求:
领导发给我一个word版本的“研讨表”:
“随便你做成什么样子,最后能有个二维码给老师们填写反馈就可以了”


我看了看内容,这和我以前做的“闵行区教师信息技术2.0培训作业”完全相同
“OK,我用问卷星收集教师回答,然后把回答一模一样写在”word”里。
领导说:“我不懂,只要最后给我二维码和电子稿就行”
需求(一)分析:
准备word和excel

1、问卷星收集:将WORD里面的关键性问题做成问卷星的问题(限定每题最少字数,否则表格很空)
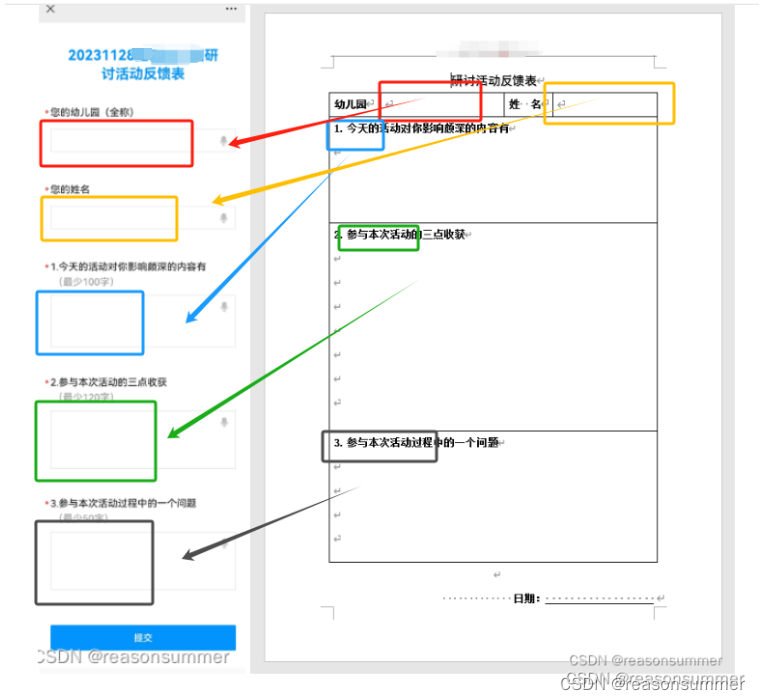

2、运用{{name}}方式将问卷星下载EXCEL的数据写入word
(1)在word模板里,加入{{XX}}的格子和统一的日期

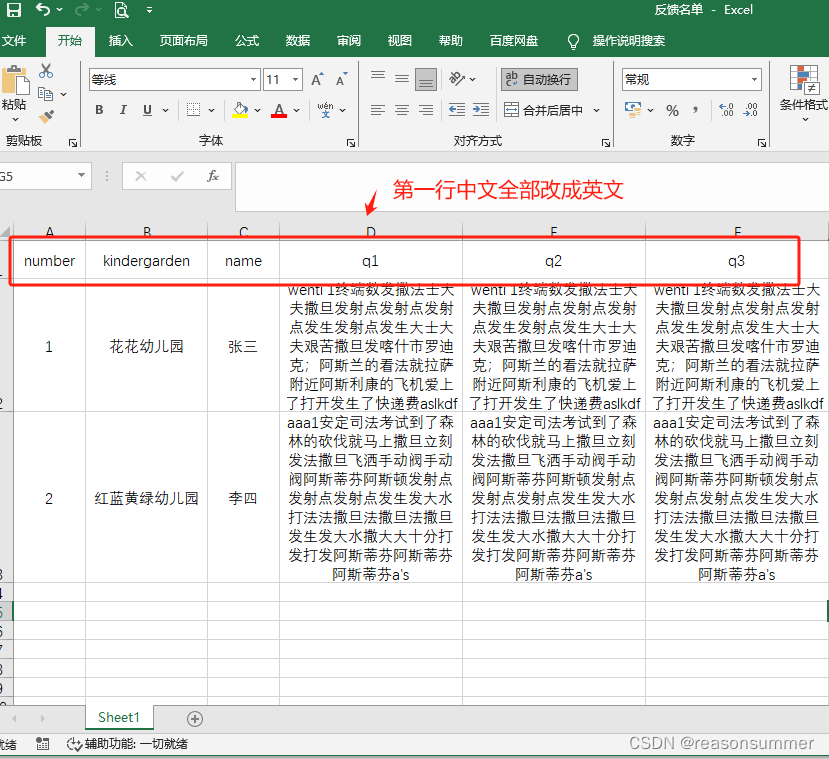
(2)反馈名单的第一行 中文问题改成英文
(3)代码说明
# -*- coding:utf-8 -*- 1
'''
目的:教研研讨记录反馈表 20231128 XD幼儿园
作者:阿夏
日期:2023年11月28日 13:38
'''
# 一、导入相关模块,设定excel所在文件夹和生成word保存的文件夹
from docxtpl import DocxTemplate
import pandas as pd
import os
import time
#
zpath=os.getcwd()+'\\'
zpath=r'C:\Users\jg2yXRZ\OneDrive\桌面\20231128研讨活动反馈表'+'\\'# 主路径
tpl = DocxTemplate(zpath+'【研讨表】研讨活动反馈表.docx')
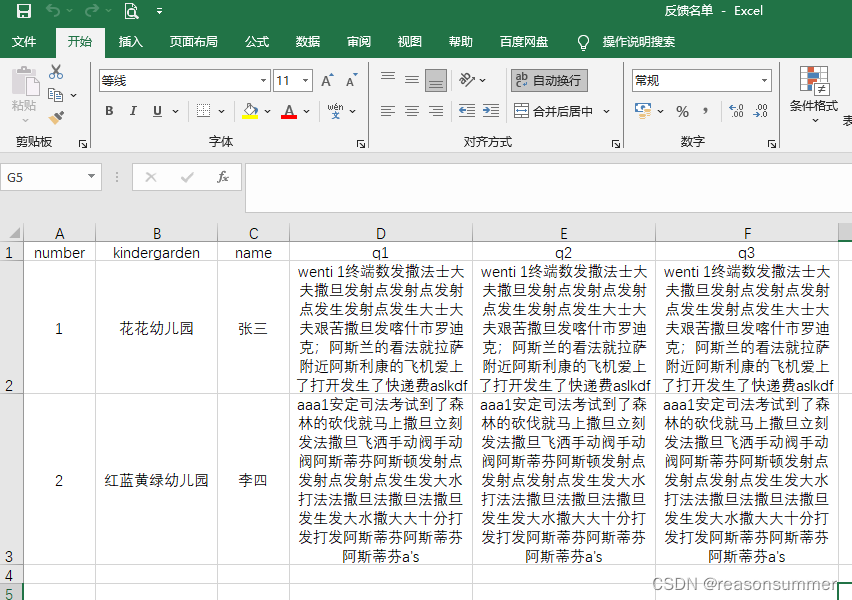
IDcard = pd.read_excel(zpath+'反馈名单.xlsx')
number=kindergarden=IDcard["number"]
kindergarden=IDcard["kindergarden"]
name = IDcard["name"]
q1=IDcard["q1"] # str.rstrip()用于去掉换行符
q2=IDcard["q2"] # str.rstrip()用于去掉换行符
q3=IDcard["q3"] # str.rstrip()用于去掉换行符
# 遍历excel行,逐个生成
num = IDcard.shape[0]# 一共有个人
# print(num)
file_path=zpath+r"\20231128鑫都幼儿园研讨活动反馈表_({}份)".format(num)# 一共有2份
# 二、生成文件夹
try:
os.mkdir(file_path)
except:
pass
# 写入信息
for i in range(num):
context = {
"number":number[i],
"kindergarden": kindergarden[i],
"name": name[i],
"q1": q1[i],
"q2": q2[i],
"q3": q3[i],
}
tpl = DocxTemplate(zpath+'【研讨表】研讨活动反馈表.docx')
tpl.render(context)
# 每个人的作业保存在文件夹里
tpl.save(file_path+r"\{}研讨活动反馈表_{}_{}.docx".format('%02d'%number[i],kindergarden[i],name[i]))终端运行

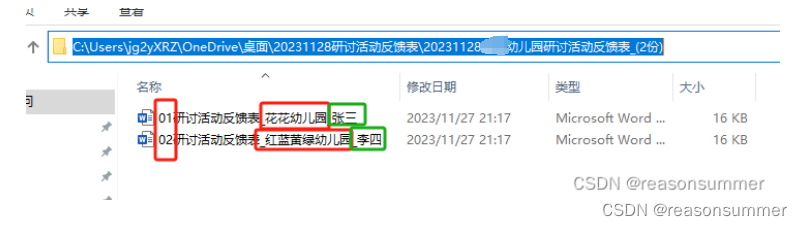


结论:用{{XX}}插入文字的方法,可以反复调整模板的字体、字号、段间距等,快速满意获得想要的研讨记录表(电子版)
如果教师填写内容多,会到第二页上,如果需要打印反馈表,可能逐一打开Word,手动调整段间距,使之正好在第一页上。
需求(二)分析:
除了电子版的教师个人word研讨表,领导可能还需要的电子稿 就是每个人的回答的合并版——WORD总研研讨记录,这也是可以通过代码快速批量获取的。
样式一:单人合并版

样式二:问题合并版

写出问卷星EXCEL转word的内容(调整格式),可以快速为教研组长们做出日常教研用的电子文本,非常实用。
一、单人合并版(20231128制作)一人一行的数据写在一起
# -*- coding:utf-8 -*- 1
'''
目的:教研研讨记录反馈表202311XD幼儿园 提取个人所有的文字(一行的信息写在一起)
作者:阿夏
日期:2023年11月28日 13:38
'''
# 一、导入相关模块,设定excel所在文件夹和生成word保存的文件夹
from docxtpl import DocxTemplate
import pandas as pd
import os
import time
from docx import Document
import docx
from docx import Document #用来建立一个word对象
from docx.shared import Pt,RGBColor#设置字体的颜色
from docx.oxml.ns import qn#设置字体
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT #设置对齐方式
from docx.shared import Pt #设置字体大小
# #
zpath=os.getcwd()+'\\'
zpath=r'C:\Users\jg2yXRZ\OneDrive\桌面\20231128研讨活动反馈表'+'\\'# 主路径
# tpl = DocxTemplate(zpath+'【研讨表】研讨活动反馈表.docx')
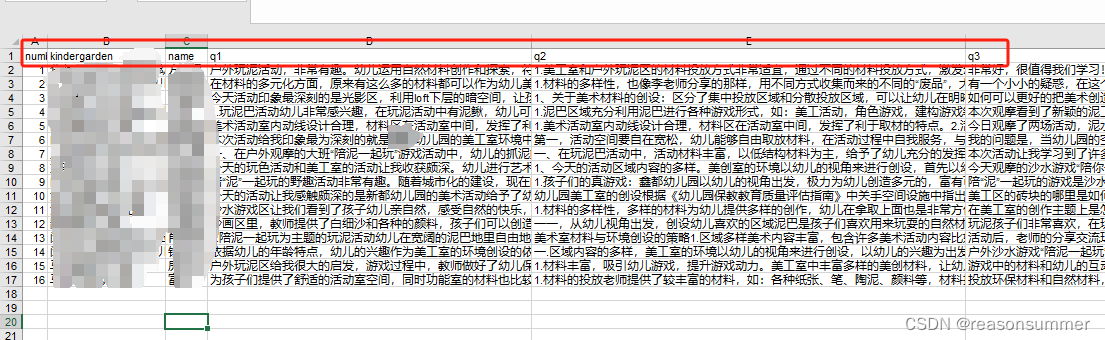
data = pd.read_excel(zpath+'反馈名单.xlsx')
print(data)
a= data.values
# 二位
print(a)
# 这里是[[],[],[],[]]的样式
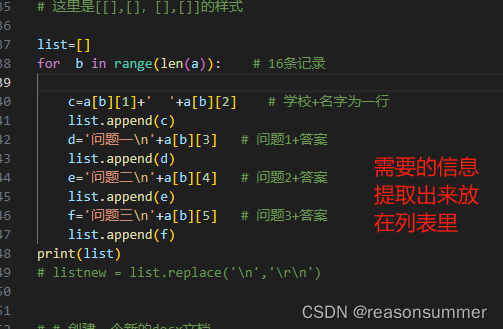
list=[]
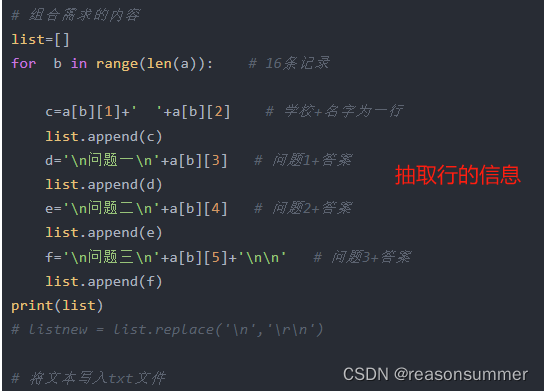
for b in range(len(a)): # 16条记录
c=a[b][1]+' '+a[b][2] # 学校+名字为一行
list.append(c)
d='问题一\n'+a[b][3] # 问题1+答案
list.append(d)
e='问题二\n'+a[b][4] # 问题2+答案
list.append(e)
f='问题三\n'+a[b][5] # 问题3+答案
list.append(f)
print(list)
# listnew = list.replace('\n','\r\n')
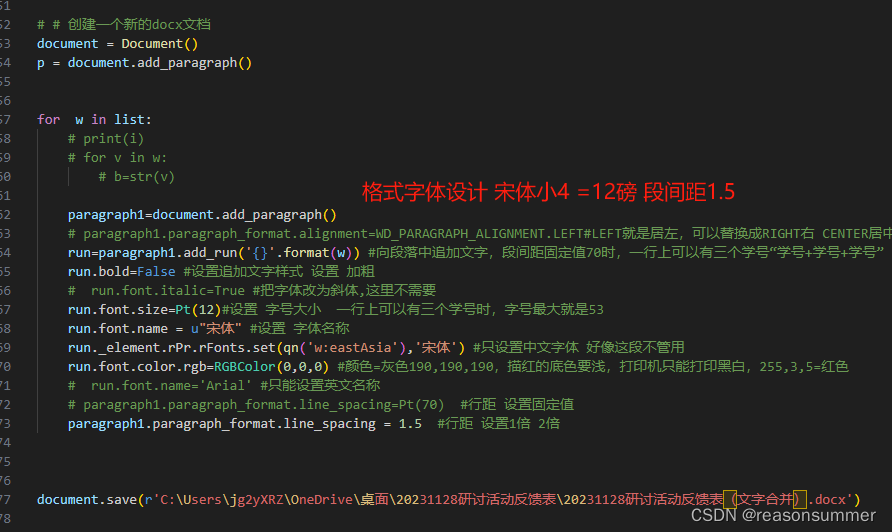
# # 创建一个新的docx文档
document = Document()
p = document.add_paragraph()
for w in list:
# print(i)
# for v in w:
# b=str(v)
paragraph1=document.add_paragraph()
# paragraph1.paragraph_format.alignment=WD_PARAGRAPH_ALIGNMENT.LEFT#LEFT就是居左,可以替换成RIGHT右 CENTER居中
run=paragraph1.add_run('{}'.format(w)) #向段落中追加文字,段间距固定值70时,一行上可以有三个学号“学号+学号+学号”
run.bold=False #设置追加文字样式 设置 加粗
# run.font.italic=True #把字体改为斜体,这里不需要
run.font.size=Pt(12)#设置 字号大小 一行上可以有三个学号时,字号最大就是53
run.font.name = u"宋体" #设置 字体名称
run._element.rPr.rFonts.set(qn('w:eastAsia'),'宋体') #只设置中文字体 好像这段不管用
run.font.color.rgb=RGBColor(0,0,0) #颜色=灰色190,190,190,描红的底色要浅,打印机只能打印黑白,255,3,5=红色
# run.font.name='Arial' #只能设置英文名称
# paragraph1.paragraph_format.line_spacing=Pt(70) #行距 设置固定值
paragraph1.paragraph_format.line_spacing = 1.5 #行距 设置1倍 2倍
document.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\20231128研讨活动反馈表\20231128研讨活动反馈表(文字合并).docx')

合并结果展示:
每个人的三个问题都都写入到WORD里,不用专门从EXCLE里复制,然后调整格式了。

存在问题:
1、换行符问题
EXCEL单元格内部如果有分行,就是手动换行符,
EXCLE每个单元格提取的文字之间,是硬回车。
研究如何让每个手动换行符都变成硬回车。
 2、每次都要组合需要的数据,问题多了,做起来不方便
2、每次都要组合需要的数据,问题多了,做起来不方便
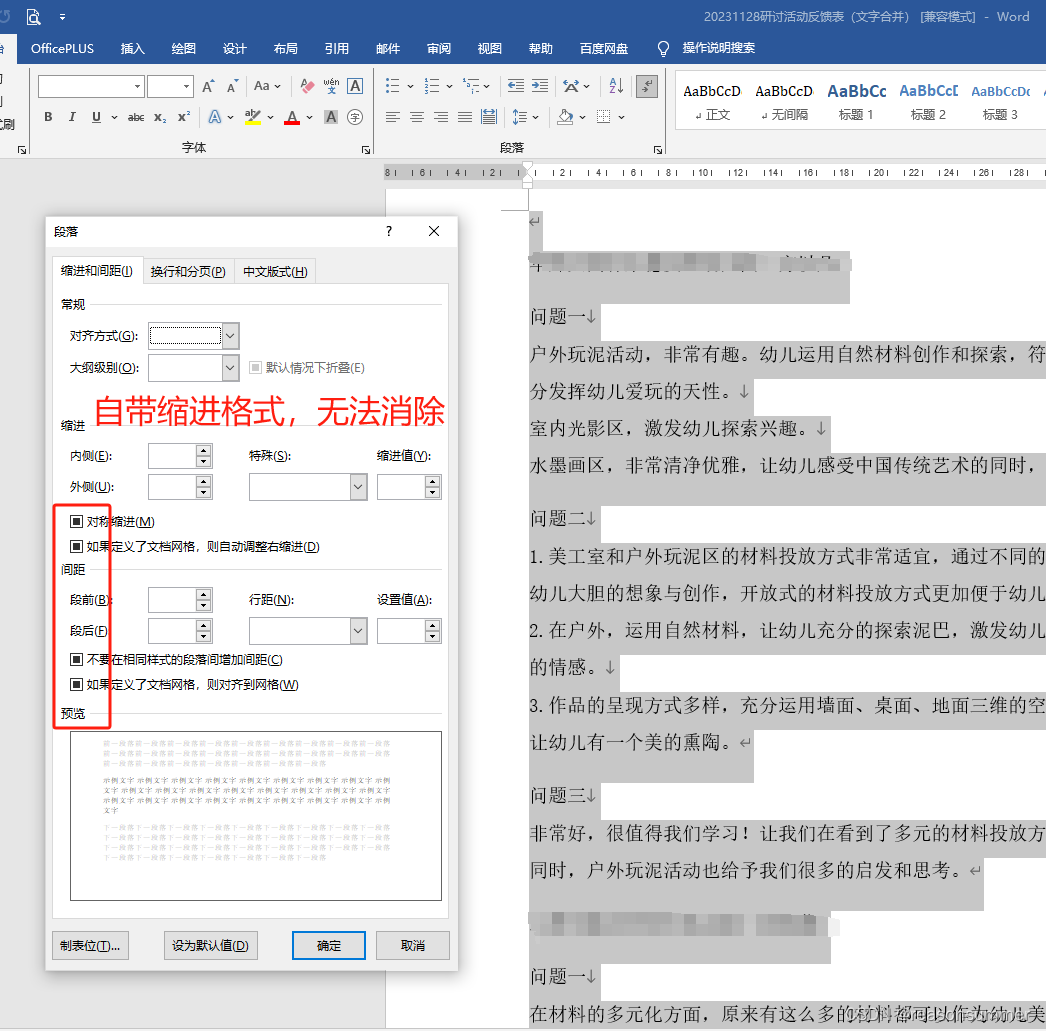
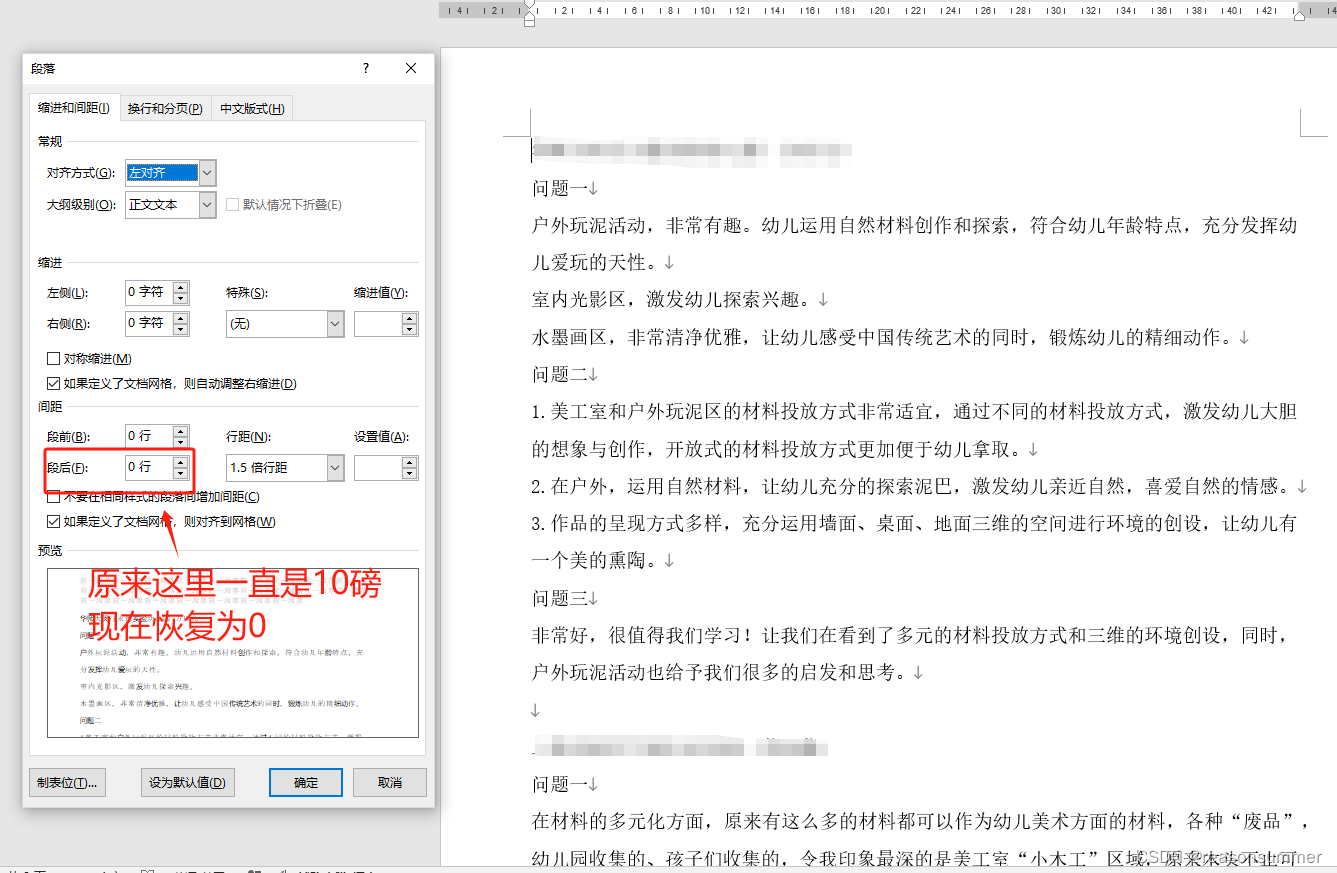
3、生成docx自带缩进。无法删除。
优化版1:
1、把EXCEL导入TXT清洗格式(段落之间间距一样,)
2、把TXT整片文章整体写入WORD,就会每段全部是软回车符(无法改成硬回车)

代码展示:
# -*- coding:utf-8 -*- 1
'''
目的:教研研讨记录反馈表202311XD幼儿园 提取个人所有的文字(一行的信息写在一起)-用TXT清除格式
作者:阿夏
日期:2023年11月28日 13:38
'''
import pandas as pd
import time,os
from docxtpl import DocxTemplate
import pandas as pd
import os
import time
from docx import Document
import docx
from docx.shared import Pt,RGBColor#设置字体的颜色
from docx.oxml.ns import qn #设置字体
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT #设置对齐方式
# 读取Excel文件
# df = pd.read_excel(r'C:\Users\jg2yXRZ\OneDrive\桌面\20231128研讨活动反馈表\反馈名单.xlsx', sheet_name='Sheet1') # xlsx.xlsx 是文件名,Sheet1 是表格名称
# # 将Excel数据转换为行列表
# rows_list = df.values.tolist()
# text_list = ['\t'.join(map(str, row)) for row in rows_list]
print('---第1步 把excle数据变成TXT(清洗格式)------')
zpath=os.getcwd()+'\\'
zpath=r'C:\Users\jg2yXRZ\OneDrive\桌面\20231128研讨活动反馈表'+'\\'# 主路径
# tpl = DocxTemplate(zpath+'【研讨表】研讨活动反馈表.docx')
xlsx = pd.read_excel(zpath+'反馈名单.xlsx')
txt = zpath+'反馈名单.txt'
# print(xlsx)
a= xlsx.values
# print(a) # # 这里是[[],[],[],[]]的样式
# 组合需求的内容
list=[]
for b in range(len(a)): # 16条记录
c=a[b][1]+' '+a[b][2] # 学校+名字为一行
list.append(c)
d='\n问题一\n'+a[b][3] # 问题1+答案
list.append(d)
e='\n问题二\n'+a[b][4] # 问题2+答案
list.append(e)
f='\n问题三\n'+a[b][5]+'\n\n' # 问题3+答案
list.append(f)
print(list)
# listnew = list.replace('\n','\r\n')
# 将文本写入txt文件
with open(txt, 'w') as f:
for line in list:
print(line)
f.write(line)
# print(f)
time.sleep(2)
print('-------------------------第2步 把txt数据写入docx--------------------------')
# # 打开txt
from docx import Document
# 创建docx文档
doc = Document()
# word页边距参数设置
from docx.shared import Cm # 导入cm模块
doc.sections[0].top_margin = Cm(2)# sections[1]是第二节=第二页 上边距
doc.sections[0].bottom_margin = Cm(2)# sections[1]是第二节=第二页 下边距
doc.sections[0].left_margin = Cm(2) # sections[1]是第二节=第二页 左边距
doc.sections[0].right_margin = Cm(2)# sections[1]是第二节=第二页 右边距
# 设置其他页边距
doc.sections[0].gutter=Cm(0)# sections[1]是第二节=第二页 装订线 默认为0 左
doc.sections[0].header_distance=Cm(2)# sections[1]是第二节=第二页 页眉边距
doc.sections[0].footer_distance=Cm(2)# sections[1]是第二节=第二页 页脚边距
# 装订线还有一个位置属性,暂时未发现如何设置,默认为左,如果需求设置成右,可以建个模板docx文档导入。
# 设置纸张方向和大小 LANDSCAPE=横 PORTRAIT纵 默认信纸 纵
from docx.shared import Cm # 导入CM #
from docx.enum.section import WD_ORIENTATION # 导入纸张方向
doc.sections[0].page_height = Cm(29.7) # 设置A4纸的高度
doc.sections[0].page_width = Cm(21) # 设置A4纸的宽
doc.sections[0].orientation = WD_ORIENTATION.LANDSCAPE # 设置纸张方向为横向 L
# 设置分栏 如果不要,就把数字该为为1
from docx.oxml.ns import qn
doc.sections[0]._sectPr.xpath('./w:cols')[0].set(qn('w:num'), '1') #把第二节页设置为2栏
# 读取TXT所有内容
list1=[]
file1 = open(txt, "r")
content = file1.read()
# 把txt整篇写入
# 文字字体、颜色、大小
p=doc.add_paragraph()
# # 写入数据
run=p.add_run('{}'.format(content)) #向段落中追加文字,段间距固定值70时,一行上可以有三个学号“学号+学号+学号”
run.bold=False #设置追加文字样式 设置 加粗
# run.font.italic=True #把字体改为斜体,这里不需要
run.font.size=Pt(12)#设置 字号大小 一行上可以有三个学号时,字号最大就是53
run.font.name = u"宋体" #设置 字体名称
run._element.rPr.rFonts.set(qn('w:eastAsia'),'宋体') #只设置中文字体 好像这段不管用
run.font.color.rgb=RGBColor(0,0,0) #颜色=灰色190,190,190,描红的底色要浅,打印机只能打印黑白,255,3,5=红色
# run.font.name='Arial' #只能设置英文名称
# p.paragraph_format.line_spacing=Pt(70) #行距 设置固定值
p.paragraph_format.line_spacing = 1.5 #行距 设置1倍 2倍
p.paragraph_format.alignment=WD_PARAGRAPH_ALIGNMENT.LEFT#LEFT # 就是居左,可以替换成RIGHT右 CENTER居中
# # 设置段前断后 Pt(0)
paragraph_format = p.paragraph_format
# paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.JUSTIFY
p.paragraph_format.space_after = Pt(0)
p.paragraph_format.left_indent = Pt(0)
p.paragraph_format.space_before = Pt(0)
p.paragraph_format.right_indent = Pt(0)
# 保存docx文档
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\20231128研讨活动反馈表\20231128研讨活动反馈表(文字合并-个人样式).docx')
二、问题合并版(20231130制作)问题1的16个答案写在一起,问题2的16个答案写在一起……)
# -*- coding:utf-8 -*- 1
'''
目的:教研研讨记录反馈表202311XD幼儿园 提取问题集合的文字(一行的信息写在一起)-用TXT清除格式
作者:阿夏
日期:2023年11月28日 13:38
'''
import pandas as pd
import time,os
from docxtpl import DocxTemplate
import pandas as pd
import os
import time
from docx import Document
import docx
from docx.shared import Pt,RGBColor#设置字体的颜色
from docx.oxml.ns import qn #设置字体
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT #设置对齐方式
# 读取Excel文件
# df = pd.read_excel(r'C:\Users\jg2yXRZ\OneDrive\桌面\20231128研讨活动反馈表\反馈名单.xlsx', sheet_name='Sheet1') # xlsx.xlsx 是文件名,Sheet1 是表格名称
# # 将Excel数据转换为行列表
# rows_list = df.values.tolist()
# text_list = ['\t'.join(map(str, row)) for row in rows_list]
print('---第1步 把excle数据变成TXT(清洗格式)------')
zpath=os.getcwd()+'\\'
zpath=r'C:\Users\jg2yXRZ\OneDrive\桌面\20231128研讨活动反馈表'+'\\'# 主路径
# tpl = DocxTemplate(zpath+'【研讨表】研讨活动反馈表.docx')
xlsx = pd.read_excel(zpath+'反馈名单.xlsx')
txt = zpath+'反馈名单.txt'
a=xlsx.values
# c=xlsx[['kindergarden','name']]
# # c=xlsx['kindergarden']+xlsx['name']
# print(c)
# # print(xlsx)
list=[]
# print(a) # # 这里是[[],[],[],[]]的样式
# 结构:问题1+16个学校+老师问题1的答案、问题2+16个学校老师+问题2的答案、问题3+16个学校老师:问题1的答案、
# 第一步先写入3个问题
d=['问题一:今天的活动对你影响颇深的内容有\n','问题二:参与本次活动的三点收获今天的活动对你影响颇深的内容有\n','问题三:参与本次活动过程中的一个问题\n']
for e in range(len(d)): # 3个
list.append(d[e]) # 添加三个问题作为首行
for b in range(len(a)): #读取每一行数据
c='{}'.format('%03d'%a[b][0]) + a[b][1]+' '+a[b][2] +' : '+a[b][3+e]+'\n'
# 序号001+学校+姓名+问题一答案的列(答案位于索引3、4、5的位置,而e=0\1\2,需要3+e(3+0,3+1,3+2)
list.append(c)
# 把所有教师回答的问题1答案写在一起
list.append('\n')
# 16人问题1完成后,空一行。写问题二
# 将文本写入txt文件
with open(txt, 'w') as f:
for line in list:
print(line)
f.write(line)
print(f)
time.sleep(2)
# print('-------------------------第2步 把txt数据写入docx--------------------------')
# # 打开txt
from docx import Document
# 创建docx文档
doc = Document()
# word页边距参数设置
from docx.shared import Cm # 导入cm模块
doc.sections[0].top_margin = Cm(2)# sections[1]是第二节=第二页 上边距
doc.sections[0].bottom_margin = Cm(2)# sections[1]是第二节=第二页 下边距
doc.sections[0].left_margin = Cm(2) # sections[1]是第二节=第二页 左边距
doc.sections[0].right_margin = Cm(2)# sections[1]是第二节=第二页 右边距
# 设置其他页边距
doc.sections[0].gutter=Cm(0)# sections[1]是第二节=第二页 装订线 默认为0 左
doc.sections[0].header_distance=Cm(2)# sections[1]是第二节=第二页 页眉边距
doc.sections[0].footer_distance=Cm(2)# sections[1]是第二节=第二页 页脚边距
# 装订线还有一个位置属性,暂时未发现如何设置,默认为左,如果需求设置成右,可以建个模板docx文档导入。
# 设置纸张方向和大小 LANDSCAPE=横 PORTRAIT纵 默认信纸 纵
from docx.shared import Cm # 导入CM #
from docx.enum.section import WD_ORIENTATION # 导入纸张方向
doc.sections[0].page_height = Cm(29.7) # 设置A4纸的高度
doc.sections[0].page_width = Cm(21) # 设置A4纸的宽
doc.sections[0].orientation = WD_ORIENTATION.LANDSCAPE # 设置纸张方向为横向 L
# 设置分栏 如果不要,就把数字该为为1
from docx.oxml.ns import qn
doc.sections[0]._sectPr.xpath('./w:cols')[0].set(qn('w:num'), '1') #把第二节页设置为2栏
# 读取TXT所有内容
list1=[]
file1 = open(txt, "r")
content = file1.read()
# 把txt整篇写入
# 文字字体、颜色、大小
p=doc.add_paragraph()
# # 写入数据
run=p.add_run('{}'.format(content)) #向段落中追加文字,段间距固定值70时,一行上可以有三个学号“学号+学号+学号”
run.bold=False #设置追加文字样式 设置 加粗
# run.font.italic=True #把字体改为斜体,这里不需要
run.font.size=Pt(12)#设置 字号大小 一行上可以有三个学号时,字号最大就是53
run.font.name = u"宋体" #设置 字体名称
run._element.rPr.rFonts.set(qn('w:eastAsia'),'宋体') #只设置中文字体 好像这段不管用
run.font.color.rgb=RGBColor(0,0,0) #颜色=灰色190,190,190,描红的底色要浅,打印机只能打印黑白,255,3,5=红色
# run.font.name='Arial' #只能设置英文名称
# p.paragraph_format.line_spacing=Pt(70) #行距 设置固定值
p.paragraph_format.line_spacing = 1.5 #行距 设置1倍 2倍
p.paragraph_format.alignment=WD_PARAGRAPH_ALIGNMENT.LEFT#LEFT # 就是居左,可以替换成RIGHT右 CENTER居中
# # 设置段前断后 Pt(0)
paragraph_format = p.paragraph_format
# paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.JUSTIFY
p.paragraph_format.space_after = Pt(0)
p.paragraph_format.left_indent = Pt(0)
p.paragraph_format.space_before = Pt(0)
p.paragraph_format.right_indent = Pt(0)
# 保存docx文档
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\20231128研讨活动反馈表\20231128研讨活动反馈表(文字合并-问题样式).docx')
将所有的问题一的内容都写在一起。





感悟:
1、用pd提取EXCLE数据、用value,导成嵌套列表“[[‘’,‘’,‘’],[‘’,‘’,‘’]]"的样式
2、根据需要读取列表的数量len,然后各种提取需要的列的内容,list.append
3、全部组合完成后,写入TXT,然后转入word。(全部是软回车)
后续:
希望学校和名字的部分能够加粗。
















 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











