








概念
频繁模式(frequent pattern):是频繁地出现在数据集中的模式(如项集、子序列或子结构)。频繁模式挖掘搜索给定数据集中反复出现的联系。
支持度(support)和置信度(confidence)是关联规则的两种度量。他们分别反映所发现规则的有用性和确定性。例如:
computer=>antivirus_software[support = 2%; confidence = 60%],
其中支持度2%表示所有事务的2%显示电脑和杀毒软件被同时购买,置信度60%表示购买计算机的顾客也购买了杀毒软件。
2、关联规则
设
I={I1,I2,...,Im}
是项的集合。设任务相关的数据
D
是数据库事务的集合,其中每个事务
其中, σ(X) 表示项集 X 的支持度计数。同时满足最小支持度阈值
给定事务的集合
T
,关联规则发现是指找出支持度大于等于
为了避免不必要的开销,事先对规则剪枝,而无须计算它们的支持度和置信度的值将是有益的。提高关联规则挖掘算法性能的第一步是拆分支持度和置信度要求。由公式1可以看出,规则 A⇒B 的支持度仅仅依赖于其对应项集 A∪B 的支持度。例如,下面的规则有相同的支持度,因为他们涉及的项都源自于同一个项集{啤酒,尿布,牛奶}:
{啤酒,尿布}->{牛奶},{啤酒,牛奶}->{尿布},
{牛奶,尿布}->{啤酒},{啤酒}->{尿布,牛奶},
{尿布}->{牛奶,啤酒},{牛奶}->{尿布,啤酒}
如果项集{啤酒,尿布,牛奶}是非频繁的,则可以立即去掉这6个候选规则,则不必计算他们的置信度值。
因此,关联规则的挖掘是一个两步的过程:
(1)找出所有的频繁项集:根据定义,这些项集的每一个频繁出现的次数至少与预定义的最小支持度计数
min_sup
一样。
(2)由频繁项集产生强关联规则:根据定义,这些规则必须满足最小支持度和最小置信度。
可以使用附加的兴趣度度量来发现相关联的项之间的相关联系。由于第二步的开销远小于第一步,因此挖掘关联规则的总体性能由第一步决定。
例:
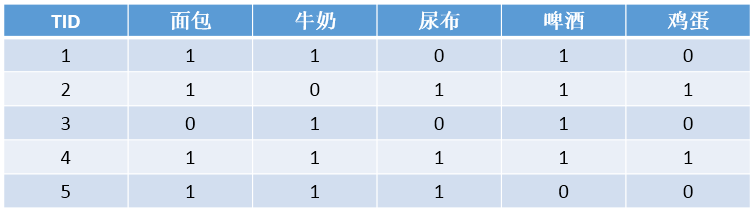
上表中:规则
{(牛奶,尿布)⇒(啤酒)}
的支持度 = 0.4,置信度=0.67
3、频繁项集的产生
发现频繁项集的一种原始的方法是确定每个候选项集的支持度计数。为了完成这一个任务,必须将每个候选项集与每个事务进行比较。
有几种方法可以降低产生频繁项集的计算复杂度:
(1)减少候选项集的数目:下面介绍的先验(apriori)原理,是一种不用计算支持度值而删除某些候选项集的有效方法。
(2)减少比较次数:替代将每个候选项集与每个事务相匹配,可以使用更高级的数据结构,或者存储候选项集或者压缩数据集,来减少比较的次数。
4、Apriori算法,通过限制候选产生发现频繁项集
(1)先验原理:
(a)定理:如果一个项集是频繁的,则它的所有非空子集也一定是频繁的;
(b)单调性:令
I
是项的集合,
(2)Apriori算法
**算法原理:**Apriori使用一种称之为逐层搜索的迭代方法,其中
k
项集用于探索
令
Ck
为候选k-项集的集合,而
Fk
为频繁k-项集的集合。

(1)该算法初始通过单遍扫描数据集,确定每个项的支持度。一旦完成这一步,就得到所有频繁1-项集的集合
F1
(步骤1和步骤2)。
(2)接下来,该算法将使用上一次迭代发现的频繁(k-1)-项集,产生新的候选k-项集(步骤5)。候选的产生使用apriori-gen函数实现。
(3)为了对候选项的支持度计数,算法需要再次扫描一遍数据集(步骤6~10)。使用子集函数确定包含在每一个事务t中的
Ck
中的所有候选k-项集。
(4)计算候选项的支持度计数之后,算法将删去支持度计数小于
minup
的所有候选项集(步骤12)。
(5)当没有新的频繁项集产生,即
Fk=∅
时,算法结束(步骤13)。
Apriori算法的频繁项集产生的部分有两个重要的特点:第一,它是逐层算法,他每次遍历项集格中的一层;第二,它使用产生-测试(generate-and-test)策略发现频繁项集。该算法总的迭代次数是
Kmax+1
,其中
Kmax
是频繁项集的最大长度。
(3)候选的产生和剪枝
a.候选项集的产生,连接步:为了找出
Lk
,通过将
Lk−1
与自身连接产生候选
K
项集的集合。
b.候选项集的剪枝,剪枝步:扫描数据库,确定候选的计数,删除支持度计数小于
(3.a)连接步:候选项集的产生
a.蛮力方法:把所有的k-项集都看作可能的候选,然后使用候选剪枝除去不必要的候选。第
k
层产生的候选项集的数目为
b.
Fk−1⋅F1
方法:这种方法是完备的,因为每一个频繁
k
-项集都是由一个频繁
c.
Fk−1⋅Fk−1
方法:函数apriori-gen函数的候选产生过程合并一对频繁
(k−1)−
项集,仅当他们的前
k−2
个项都相同。令
A={a1,a2,...,ak−1}
和
B={b1,b2,...,bk−1}
是一对频繁
(k−1)
-项集,合并
A
和
(4)基于Hash树进行支持度计数
在Apriori算法中,候选项集划分为不同的桶,并存放在Hash树中。在支持度计数期间,包含在事务当中的项集也散列到相应的桶中。这种方法不是将事务中的每个项集与所有的候选项集进行比较,而是将它与同一个桶内候选项集进行匹配。图略。
5、由频繁项集产生关联规则
一旦由数据库中产生频繁项集,就可以直接由他们产生强关联规则(强关联规则满足最小支持度和最小置信度)。
对于置信度,可以用如下公式进行计算:
对于支持度,可以用如下的公式计算:
每个频繁
k−
项集能够产生多达
2k−2
个关联规则。关联规则可以这样提取:将项集
Y
划分成两个非空的子集
计算关联规则的置信度并不需要再次扫描事务数据集。因为置信度 σ(A∪B)/σ(A) 。这两个项集在支持度计数已经在频繁项集产生的时候已经得到,因此不必再次扫描整个数据集。
6、基于置信度的剪枝
不像支持度度量,置信度不具有任何单调性。例如:规则
X→Y
的置信度可能大于、小于或者等于规则
X′→Y′
的置信度,其中
X′⊆X
且
Y′⊆Y
。尽管如此,当比较由频繁项集
Y
产生的规则时,下面的定理对置信度度量成立。
定理: 如果规则
7、频繁项集的紧凑表示
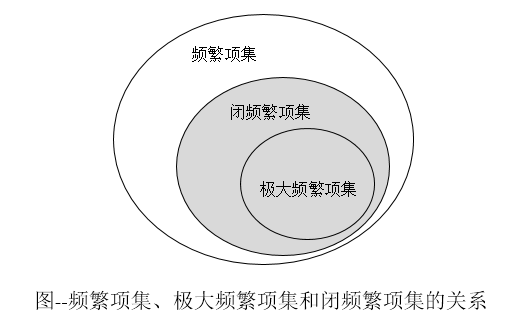
(a)极大频繁项集:极大频繁项集的直接超集都不是频繁的。极大频繁项集有效地提供了频繁项集的紧凑表示。换句话说,极大频繁项集形成了可以导出所有频繁项集的最小的项集的集合。
(b)闭项集:如果项集
(c)闭频繁项集:如果一个项集是闭的,并且它的支持度大于或等于最小支持度阈值。闭频繁项集的集合包含了频繁项集的完整信息。不会存在其它的项总是和闭频繁项集一起出现,否则闭频繁项集就包含它了。















 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









