







FP-增长(Frequent Pattern Growth, FP-growth)算法:发现频繁模式而不产生候选
正如在Apriori算法中看到的,Apriori算法的候选产生-检查方法显著压缩了候选项集的规模,并产生了很好的性能。然而,它可能仍然需要产生大量的候选项集。同时,Apriori算法可能需要重复地扫描整个数据库。
下面介绍一种称作FP-growth的算法。该算法采用完全不同的方法来发现频繁项集。该算法不同于Apriori算法的“产生-测试”泛型,而是使用一种称作FP树的紧凑数据结构组织数据,并直接从该结构中提取频繁项集。
1、FP树表示法
FP树是一种输入数据的压缩表示,它通过读入事务,并把每个事务映射到FP树中的一条路径来构造。由于不同的事务可能会有若干个相同的项,因此它们的路径可能部分重叠。路径相互重叠越多,使用FP树结构获得的压缩效果越好。如果FP树足够小,能能够存放到内存中,就可以直接从这个内存中的结构提取频繁数据项集,而不必重复地扫描存放在硬盘上的数据。
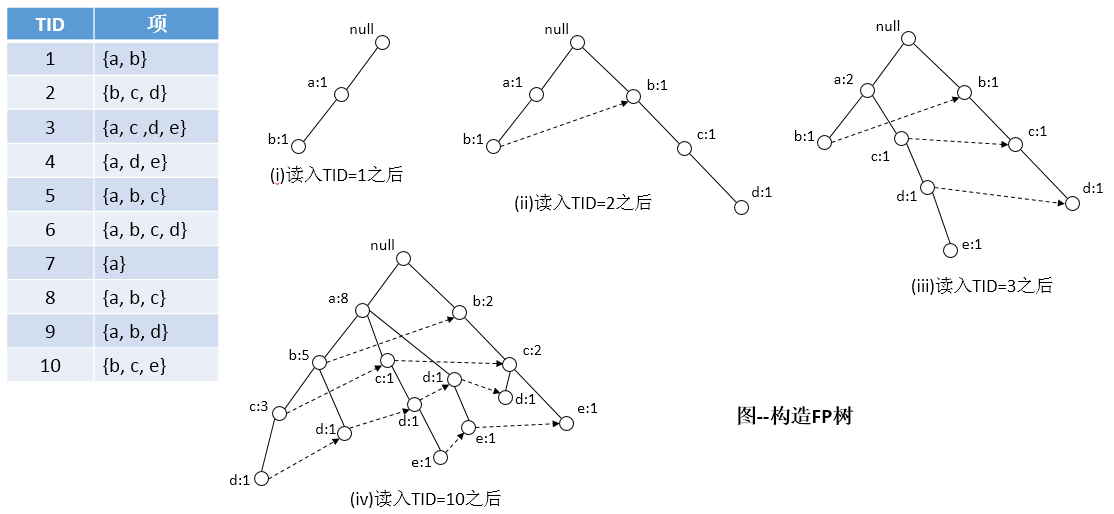
如上图所示显示了一个数据集,它包含10个事务和5个项。图中还绘出了读入前3个事务之后FP树的结构。树中每一个结点都包括一个项的标记和一个计数,计数显示映射到给定路径的事务的个数。初始,FP树仅包含一个根结点,用符号null标记。随后,用如下的方法扩种FP树:
(1.)扫描一次数据集,确定每个项的支持度计数。丢弃非频繁项,将频繁项按照支持度的递减排序。对于上图中的数据集,a是最频繁的项,接下来依次是b, c, d和 e。
(2.)算法第二次扫描数据集,构建FP树。读入第一个事务{a, b}之后,创建标记为a 和b 的结点。然后形成null → a → b路径,对该事务编码。该路径上的所有结点的频度计数为1。
(3.)读入第二个事务{b, c, d}之后,为项b, c和d创建新的结点集。然后连接结点null → b → c → d,形成一条代表该事务的路径。该路径上的所有结点的频度计数也等于1。尽管前两个事物具有一个共同项b,但是它们的路径不相交,因为这两个事务没有共同的前缀。
(4.)第三个事务{a, c, d, e}与第一个事务共享一个共同前缀项a,所以第三个事务的路径null → a → c → d → e与第一个事务的路径null → a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5457
5457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









