







基本概念
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例 | 负例 | |
| 正例 | TP(真正例) | FN(假负例) |
| 负例 | FP(假正例) | TN(真负例) |
其中,
样本总数(GT) = TP + FP + TN + FN
正例的总数 = TP + FN
预测正例的总数 = TP + FP
从TP、FP、TN、FN和GT,我们可以延伸,继续定义
查准率(Precision):反映模型对于某个类别分类结果的准确程度;即预测为正例的样本中,确实是正例的比例,计算公式为Precision = TP /(TP + FP)
召回率(Recall):反映模型对于某个类别真值的召回程度;即真值的正例中,被正确判断为正例的比例,计算公式为Recall = TP / (TP + TN)
举个栗子
| 真实情况 | 预测结果 | ||
|---|---|---|---|
| 绿色 | 黄色 | 红色 | |
| 绿色 | 1014 | 1 | 2 |
| 负例 | 2 | 92 | 4 |
| 红色 | 5 | 1 | 1797 |
Average Precision(AP)
一般情况下,模型都会有一个类似置信度的值(score)来判断分类结果的预测概率,对于单个类别,通常会把高于某个置信度阈值(score_threshold)的分类结果当作预测的正例,低于阈值的结果当作分类预测的负例。
这样,得到的某个类别的Precison和Recall,实际上是关于score的一个函数:P(score)、R(score);我们可以把P(score)和R(score)分别作为y和x的坐标,按照score从大到小的排序方式,绘制一条折线,这条折线被称为P-R曲线,P-R曲线上的每个点代表了模型在某个Recall下的Precision。

而P-R曲线与x,y轴所包围的面积,被称为Average Precision,简称AP。它代表的是不同Recall下的平均Precision。AP比某个置信度阈值下的Precision或Recall更能反映模型的综合表现,适合比较不同置信度发布的模型结果,因为AP与score无关。此外,mAP表示多个物体类别的平均AP
注:实际计算AP的不同方式,在细节上略有不同,具体请参考评测代码。
检测模型常用指标
检测模型,这里特指框(bounding box)的检测模型,比如车辆检测,行人检测等。在检测场景中,对于TP的定义,除了分类要正确,还要求预测的检测框和GT的检测框满足一定的要求。对于2D检测而言,这个要求一般指面积交并比(Intersection over Union, IoU)大于某个阈值(常见的有0.5,0.7);对于3D检测而言,这个要求一般指体积交并比大于某个阈值。
交并比,指的是两个目标的交集和并集之比,计算的可以是长度,面积或者体积,下面以面积为例,介绍一下。

如上图所示,这里有两个框,分别为蓝色的GT框和黄色的预测框,两者的交集为图中深蓝色的部分,此时有:
当预测框预测的类别与GT框的类别相同,并且A,B之间的IoU大于某个阈值时,预测框称为TP。反之,类别错误或者检测框不满足IoU的条件,称为FP。哪些没有匹配到正确预测框的GT框被称为FN,与分类场景不同的是,检测场景下并没有TN的说法。
基于检测的TP、FP、FN定义,可以使用Precision、Recall、AP、P-R曲线等指标来进行评价。此外,为了进一步评价检测模型的检测框的精度,还可以参考关于检测框精度的误差评价指标:
2D框:中心点,框的左上右下四条边和框的宽高的L1误差
3D框:中心点、长宽高和角度误差
延伸阅读
道理都懂,那么如何绘制P-R曲线呢?这里举一个小例子,假设有一个目标检测数据集,这个数据集中有7张图片,下面是对于某一个类别的检测结果,其中,红色的框是预测框,绿色的框是GT框,数字则是该预测框对应的置信度score:
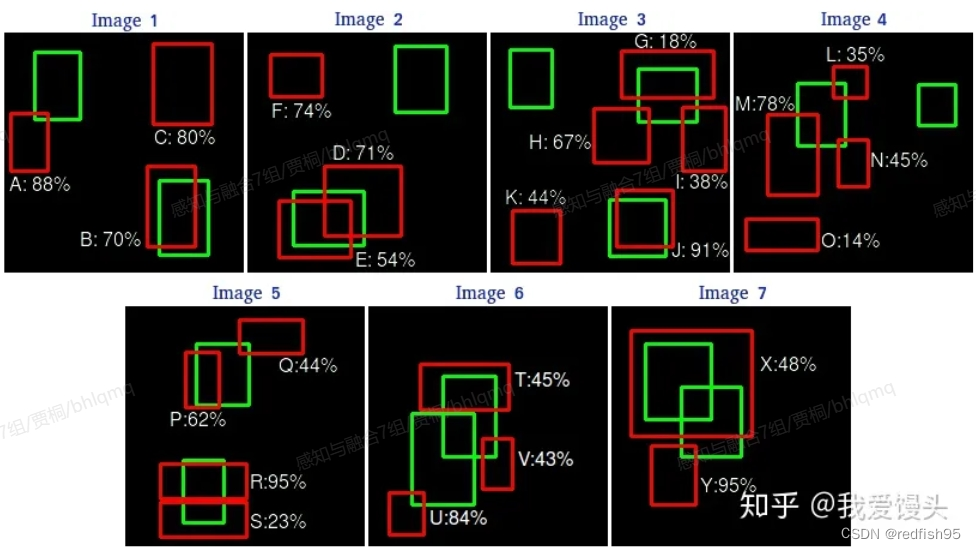
对于上面的预测结果,按照置信度进行排序(IoU > 0.5则判定为正样本),可以统计出下面这个表格:
| Images | Detections | scores | TP | FP | ACC TP | ACC FP | Precision | Recall |
|---|---|---|---|---|---|---|---|---|
| Image 5 | R | 95% | 1 | 0 | 1 | 0 | 1 | 0.0666 |
| Image 7 | Y | 95% | 0 | 1 | 1 | 1 | 0.5 | 0.0666 |
| Image 3 | J | 91% | 1 | 0 | 2 | 1 | 0.6666 | 0.1333 |
| Image 1 | A | 88% | 0 | 1 | 2 | 2 | 0.5 | 0.1333 |
| Image 6 | U | 84% | 0 | 1 | 2 | 3 | 0.4 | 0.1333 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
第三列表示预测框的置信度(scores)排名,第四列表示当前目标框预测正确与否,倒数第一,第二列实际上是TopK的Precision和Recall。前文说过,Precision表示预测出来的正样本正确的比例有多少。那么Top1时,预测了一个正样本,且预测正确,所以Precision=1.0。同理可以算出Recall=0.0666,即总共15个正样本,却只预测出来1个,召回比例就是0.0666。同理TopK的Precision和Recall均可以计算。
上述例子中,随着K的增大,Recall和Precision会一增一减。那么以Recall为横轴,Precision为纵轴,就可以画出一条P-R曲线如下(实际计算时,当Precision下降到一定程度时,后面就直接默认为0,不算了。
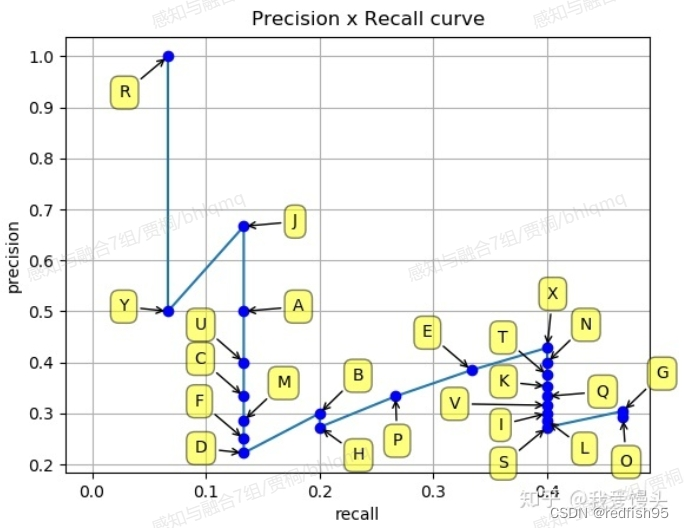
上图P-R曲线下的面积就定义为AP。
参考文献
https://www.cnblogs.com/ywheunji/p/13376090.html
https://zhuanlan.zhihu.com/p/60834912















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









