






源自:现代防御系统
作者:涂拥军 林鸿生 王智勇
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习
摘 要
光电探测是水下目标近距离探测时不可缺少的技术手段。水下光学图像具有低信噪比和对比度、照明不均匀等特点,使得光电探测在水下应用时效果不佳。常见的水下光学图像处理方法是对图像进行背景前景分割。目前主要有2种分割方法,传统分割方法易受光照、噪声等因素影响,效果不佳;深度学习方法易受训练数据限制,泛化能力不强。设计了一个带并行卷积的神经网络结构以及带约束的损失函数,通过大量实验获得了损失函数的超参数最优取值,并在不同照明条件、不同浑浊度、光照不均匀的条件下进行了实验分析。结果表明:该方法实验所获的MAE值远小于FCN8,UNet等方法,mIoU值大于FCN8,Unet等方法,P-R曲线优于其他方法的P-R曲线,更加适应水下环境复杂多变的特点,可获得更好的目标分割结果。
关键词
阈值分割, 水下图像, 光照不均, 并行卷积, 深度学习
引言
相比声呐图像,光学图像更直观更符合人眼的观察习惯,成为水下目标近距离探测时不可或缺的重要手段[1-5]。在众多应用场合中,对水下目标的识别和定位都是首先要解决的问题,通过对图像进行背景前景分割,可以为目标描述、特性分析等后续研究提供基础。图像的前景提取越准确,识别和定位成功概率越高。在图像背景前景的分割方法中,阈值分割最为常见,具有简单、有效、易于理解等特点[6-7]。
因为水体对光的吸收和散射作用,海域成像必须采取主动照明方式[8],且容易受各种因素干扰和影响。当受光束发散角及光源质量影响时,经常出现照明不均匀的现象;当受水体的吸收影响时,距离较远的目标会出现照度较低,图像偏暗的现象;当受水体的散射影响时,图像会出现大量噪声[9-10]。采用阈值分割方法对水下图像的背景前景进行分割,通常有全局阈值化和局部阈值化2种方法。其中,全局阈值法容易受光照不均的影响。局部阈值化方法首先对图像进行局部直方图均衡,然后采用全局阈值方法进行分割。尽管克服了光照不均的影响,但在有噪声的情况下,局部阈值化的分割效果仍然不够理想[11-12]。有的文献采用先提取图像的灰度波动特征、后使用局部阈值化方法进行阈值分割的做法,但在图像照度较低、噪声较严重的情况下,分割结果仍然较差。实践中还发现,传统的阈值化方法存在人工干预比较多的缺点,而且对于具有低信噪比、低对比度和照明不均匀的水下图像的分割效果难以达到预期要求。
随着深度学习技术的面世,诸多学者提出了基于深度学习的图像前景背景分割方法。如Long等提出使用全卷积网络(fully convolutional networks,FCN)[13]替代深度网络的全连接层,对图像像素进行分类预测,进而对图像进行分割。Ronneberger提出U-Net网络结构[14]用于医学图像的分割,它采用扩大解码器的容量、收缩路径和膨胀路径等方式来实现更精准的像素定位,网络结构简单、对小样本数据集有较好的效果。但上述方法所使用的训练图像都是在地面上拍摄的,光照比较均匀、图像比较清晰,基本没有噪声。另外,这些方法存在数据依赖问题[15],即当被分割的图像与训练图像处在同一个分布空间时(照度、对比度、均匀性等),分割效果最好。因此,研究具有普适性的图像分割方法,使之能够处理不同照明条件下、光照不均的水下图像,具有重要的意义。
在实际应用中,目标体积大小未知,距离未知,导致像的大小未知。在提取目标特征时如果只使用单一尺寸的卷积核,会使程序的适应性不好。本文在特征提取的时候,采用多个大小不同的卷积核并行提取特征,设计包含不同感受域的并行卷积层,提高网络对不同大小目标的适应性。另外,为了提高网络的泛化能力,使其能够适应不同照度、光照不均等实验条件,本文为模型添加了L1范数约束[16]。
1 网络结构设计
1.1 网络结构
本文设计的网络结构包含输入层、并行卷积层、编码-解码组合层以及输出层,见图1所示。
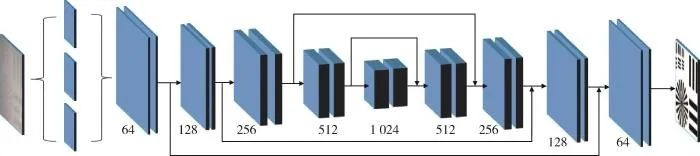
图1 网络结构示意图
输入层中对图像进行归一化。具体过程如下:假设在图像位置(i,j)的灰度值为I(i,j),使用如下公式计算其归一化的值L(i,j)。
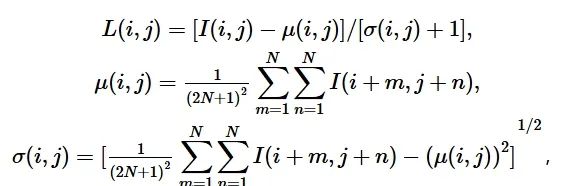
式中:N为图像像素大小,本文取256,即输入图像像素大小为256×256。
并行卷积层采用包含不同卷积核大小的并行卷积结构,用于提取水下图像中不同尺度的目标和噪声特征。并行卷积层中包含的卷积核分别为7×7 ,5×5 ,3×3 (单位为像素)。
编码-解码组合层采用收缩、扩展的方式对特征图进行编码、解码,与U-Net网络结构一致。编解码过程由多个模块组成,编码模块卷积核大小为3×3,采用 𝑅𝑒𝐿𝑈(𝑥)=max(0,𝑥)函数作为非线性激活层[17],采用核大小为2×2的最大池化对特征图进行下采样。解码模块由上采样层、卷积层、激活函数和拼接层组成。上采样层采用复制插值的方式进行,卷积层卷积核大小为3×3,激活函数依然采用 𝑅𝑒𝐿𝑈(𝑥),拼接层把编码模块的输出与相同大小的解码模块中的特征图进行拼接。输出层由卷积层、激活函数组成。卷积核大小为3×3的卷积层把编解码输出的特征图转为前景和背景2个特征图,经过非线性激活后,采用卷积核大小为1×1的卷积层把2个特征图合成一个,再经过sigmoid激活函数后输出二值化的图像。
1.2 损失函数
损失函数是神经网络的重要组成部分,用来衡量模型的预测值f(x)和真实值y的不一致程度。小样本情况下,采用结构风险最小化的方式设计目标优化函数[18],也就是在损失函数的基础上加一个正则化项。损失函数L设计为
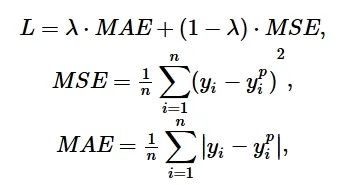
式中:𝑦𝑖为像素的真实值,
![]()
为预测值;λ为超参数,取值为[0,1]。
本文对上述带超参数的损失函数进行实验,选取最优λ值。图2为λ取0.1,0.3,0.5,0.7时(当λ取0.9时,发现训练很难收敛,效果较差)的图像分割结果。

图2 损失函数的定性比较
从图2可以看出,当λ=0.3时,分割效果更好一点,虽然带有噪声,但细节保留较好;当λ=0.7时,分割结果很差,丢失大部分图像细节。当λ=0.1或0.5时,噪声较多。
平均绝对值误差(mean absolute error,MAE)用于衡量预测结果与真实图像之间的差异,平均交并比(mean intersection over union,mIoU)用于衡量图像分割精度[19]。它们随λ变化的评价指标曲线如图3所示。
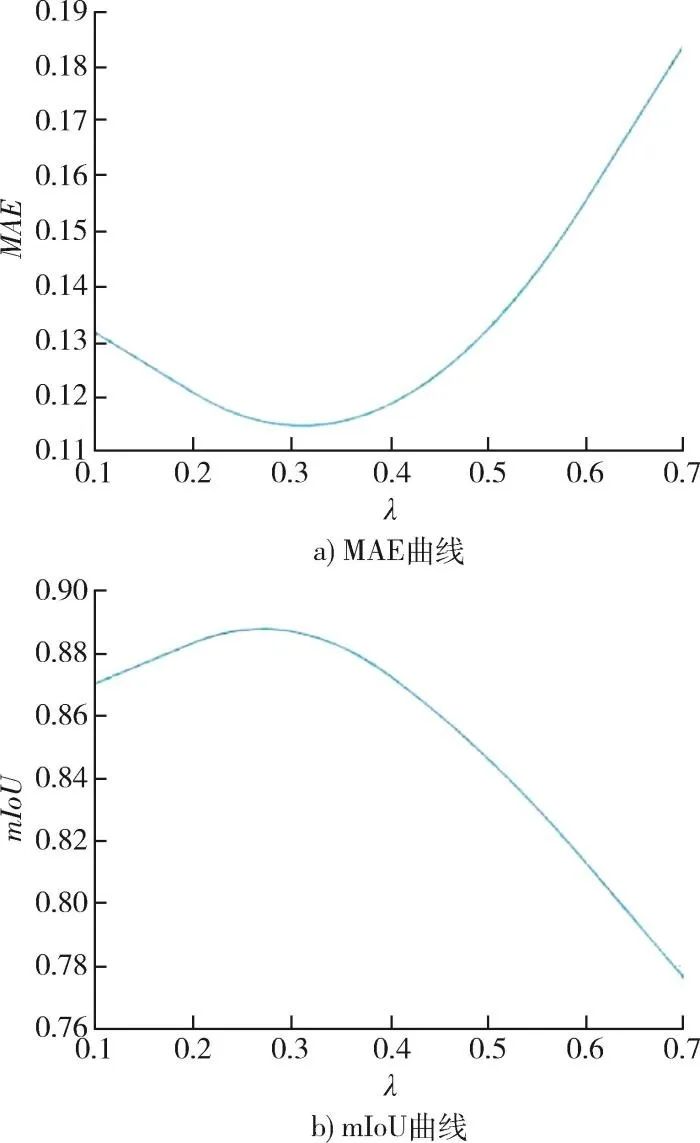
图3 λ的评价指标曲线
可以看到,当λ=0.3时,MAE误差最小,mIoU值最大,即λ=0.3为最优选择。
综上所述,损失函数采用λ=0.3时网络性能最优。
2 实验与分析
2.1 建立数据集
本文采用连续光成像系统采集数据,该系统示意图如图4所示。连续光光源亮度可调,靶板置于水池中。为了隔绝自然光及日光灯等影响,实验系统置于暗室。在采集图像过程中,使光源的照射中心不在目标中心,从而形成光照不均匀的情况。
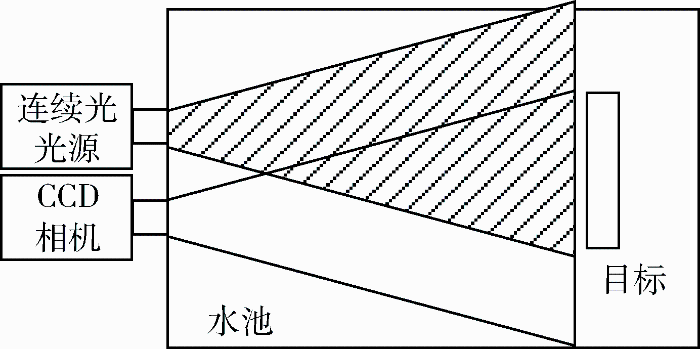
图4 本文实验装置示意图
首先,在空气中进行图像采集(作为Ground Truth图像),然后往水池加入清水,滴入墨水和牛奶的混合液体(改变水体特性,模拟杂质的散射和吸收),调整光源照明强度,采集不同照明条件下的图像(光源采用白光面光源)。
图5是相机距目标1.4 m处采集的图像,图5a)为空气中的图像,图5b)为照度为13.826 lx条件下采集的水下图像,图5c)为照度为6.947 lx条件下采集的水下图像,图5d)为照度为0.925 lx条件下采集的水下图像。可以看出,随着照明条件的不同,图像质量也随之改变,且存在非均匀性照明问题(右下角比较亮)。

图5 不同照度下的水下图像
在13.826 lx照明条件下采集图像作为训练集。对采集的图像进行裁剪(裁剪像素大小为256×256),采用旋转、镜像的方法扩充训练集,最后训练集数据为600张、验证集数据为32张。
在13.826 lx,6.947 lx和0.925 lx照明条件下采集图像作为测试集,用来测试训练后网络的泛化性能。
2.2 实验参数设置
训练环境:算法基于Keras框架实现,在Ubuntu中用Python进行实验。训练平台采用CPU为Intel i7 7700K,GPU为nvidia gtx 1080,内存为32G的台式机。训练过程中采用GPU加速。
为了验证本文网络结构的有效性,进行了FCN,U-Net以及本文方法实验。所有实验中训练参数设置都一样,如表1所示。

表1 训练参数
其中e表示周期(epoch),s表示每个周期的迭代次数(steps per epoch)。
优化算法采用Adam算法[20],初始学习率设置为1e-4,β1为0.8,β2为0.999,epsilon为1e-8。
2.3 对比分析
2.3.1 主观评价
图6,7为不同照度条件下水下图像及在不同分割方法的实验结果,其中第1,4行的原始图像为13.826 lx照度下采集的,第2,5行为6.947 lx照度下采集的,第3,6行为0.925 lx照度下采集的。深度学习的训练数据采用13.826 lx照度的图像。在进行图像采集时,图6,7中,目标距离采集设备分别为1.4,1 m。同时在水中添加了少量牛奶与墨水的混合液。实验结果表明:采用深度学习的方法要比传统的全局阈值方法及局部阈值方法要好,能够大幅降低噪声的影响,基本能够克服光照不均的影响;相比FCN8和U-Net,本文方法的分割效果更好。

图6 不同照度下测试集图像的分割结果

图7 不同照度及不同浊度下水下图像的分割结果
随着照度的降低,FCN8和U-Net的分割结果开始变差,对训练数据的依赖性较强,对不同条件下的图像适应性较差。而本文方法对不同照度下的图像都能获得较好的分割结果,泛化能力更强。
图7为不同照度及不同浊度下水下图像的分割结果,其中3个目标为螺丝刀、带花纹的圆柱形物体以及刀柄。从中可以看到,传统的全局阈值法在对水下图像进行阈值分割时,效果很差,易受光照及水体浊度影响;局部阈值法效果相对好一些,但需要不停调整局部区域大小,干预过多;先进行图像增强再进行全局阈值的方法依然会受光照及水体浊度影响。FCN8能够克服光照的部分影响,但会受水体浊度影响;U-Net能够一定程度上克服浊度的影响,但会受光照影响;本文方法效果最好,基本上克服了光照及水体浊度的影响,3个目标的形状及花纹都能够较好分割出来。
图8中为木兰湖中采集的水下图像以及使用各种方法对该图像进行阈值分割的结果。与实验室环境相比,湖中采集的图像背景干扰更大,这是由于自然水域中浮游生物、杂质较多,从而产生更大的后向散射光。整体来看,采用深度学习的方法要比传统的全局阈值方法及局部阈值方法要好;相比FCN8和U-Net,本文方法的分割效果在细节上表现更好,如第1个目标的右下角的细条纹,第2个目标的边缘及中心的细条纹,第3个目标的绳子及尾舵。

图8 木兰湖水下图像的分割结果
2.3.2 客观评价
P-R曲线可以用于评价分类器(用于本文,即为背景与前景的分类)的性能,当一个分类器的P-R曲线能够包住另外一个分类器的曲线时,说明该分类器性能优于另外一个分类器[16]。
在测试集上,计算6种方法的precision(准确率)和recall(召回率)值,得到P-R曲线如图9所示。可以看到,本文所采用方法的曲线与坐标轴所围住的面积比其他方法都要大,说明优于FCN8,U-Net等方法。
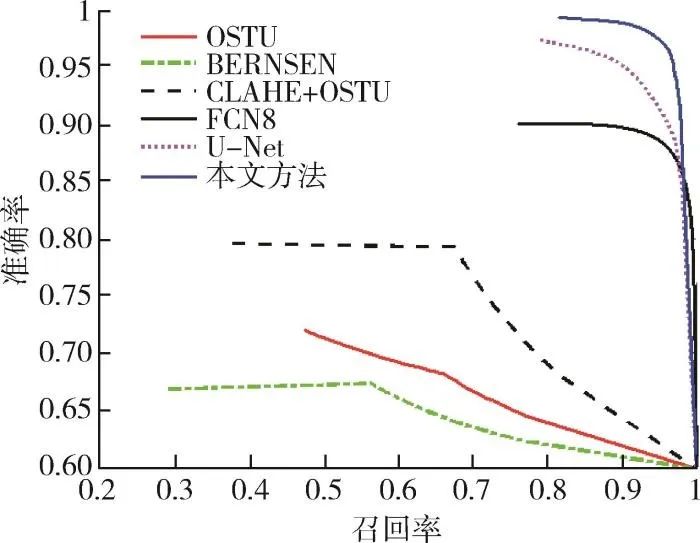
图9 不同方法的P-R曲线
在测试集上,计算6种方法的MAE及mIoU,结果如表2所示。可以看出,本文方法的MAE远小于其他方法,表明分割结果与理论上的分割图像之间的差异最小。本文方法的mIoU值大于其他方法,表明本文方法获得的分割图像更接近理想的分割结果。

表2 分割结果的客观评价
3 结束语
水下环境复杂多变,传统的图像处理方法应用到水下时人工干预过多、效果不佳;常见的深度学习方法受训练数据限制,泛化能力不足。考虑到目标的多样性,本文借鉴多尺度分析方法,设计了带并行卷积的网络结构,同时为损失函数引入约束,提高网络的泛化性。最后通过实验证明了本文结构的优越性。本文方法还可以应用到水下光学图像去噪、去模糊等其他领域。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习















 2663
2663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









