







 文章指出在QNX系统中,动态内存分配由于全局锁的存在导致高并发时性能下降,表现为频繁的锁竞争和CPU占用。通过分析tracelog,发现在1camera情况下,每秒内锁的争用超过一万次。锁抢占不仅引起任务延迟和线程切换,还会导致CPU占用过高。通过内存缓存策略(MEMORY_HOLD=1)和使用tcmalloc可以优化性能,但前者可能导致内存泄漏,后者可能带来技术风险。
文章指出在QNX系统中,动态内存分配由于全局锁的存在导致高并发时性能下降,表现为频繁的锁竞争和CPU占用。通过分析tracelog,发现在1camera情况下,每秒内锁的争用超过一万次。锁抢占不仅引起任务延迟和线程切换,还会导致CPU占用过高。通过内存缓存策略(MEMORY_HOLD=1)和使用tcmalloc可以优化性能,但前者可能导致内存泄漏,后者可能带来技术风险。
在QNX系统上,动态分配内存效率极低,进程内各个线程分配内存时,都会先去拿一把公共锁;由于本身的低效,全局锁,以及强优先级调度的机制,内存分配过多将成为系统性能的瓶颈;
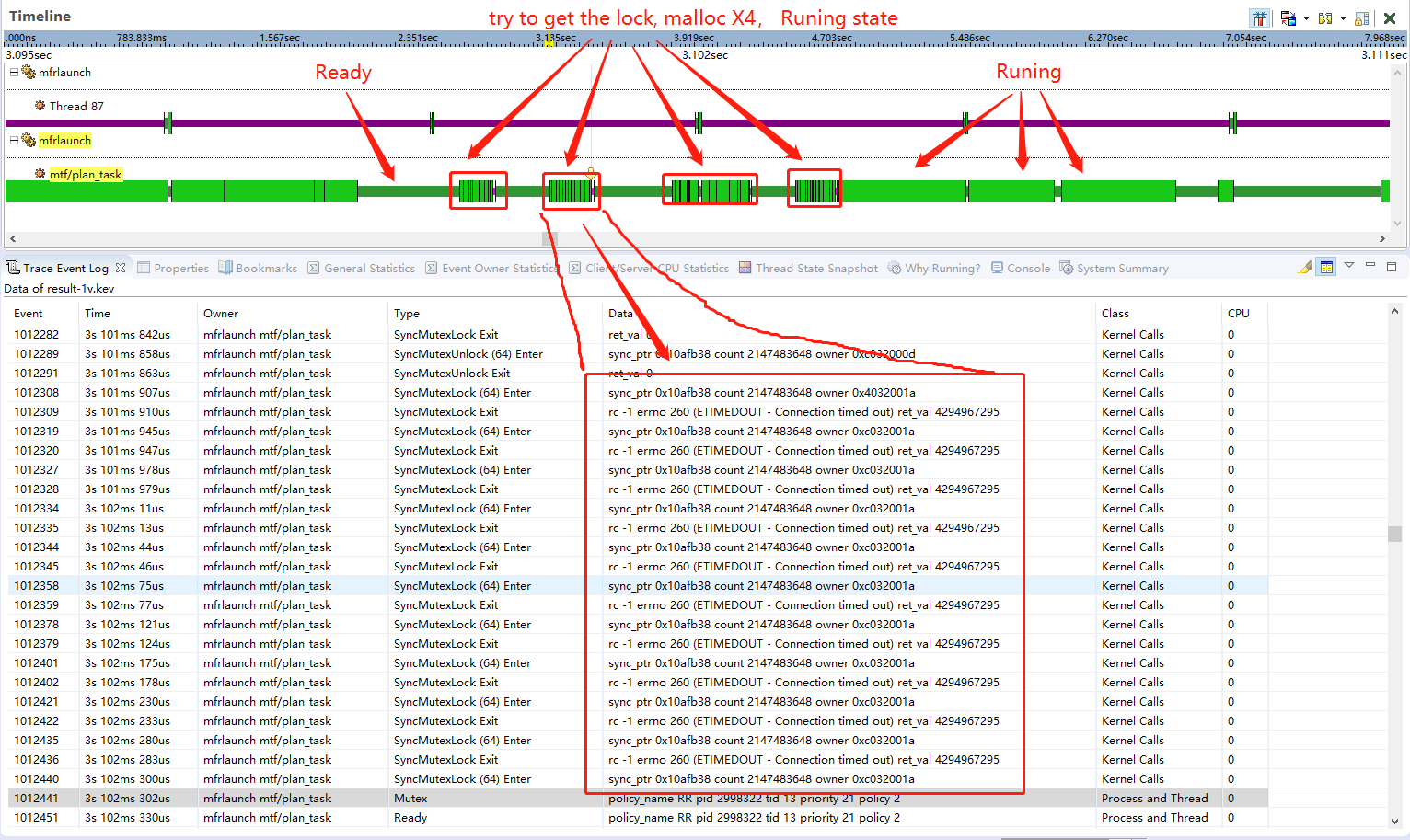
通过抓取实车运行的tracelog,我们统计到目前1camera情况下,由于多线程并发malloc导致的严重锁竞争情况,mutexlock(ptr=0x10afb38)平均每秒进入内核的次数超过1万; 附件:
锁的抢占一方面,会导致任务的延时,并造成频繁的任务调度。下图可以看到下面几个线程,出现了严重的锁竞争情况,导致任务的延时和频繁线程切换;
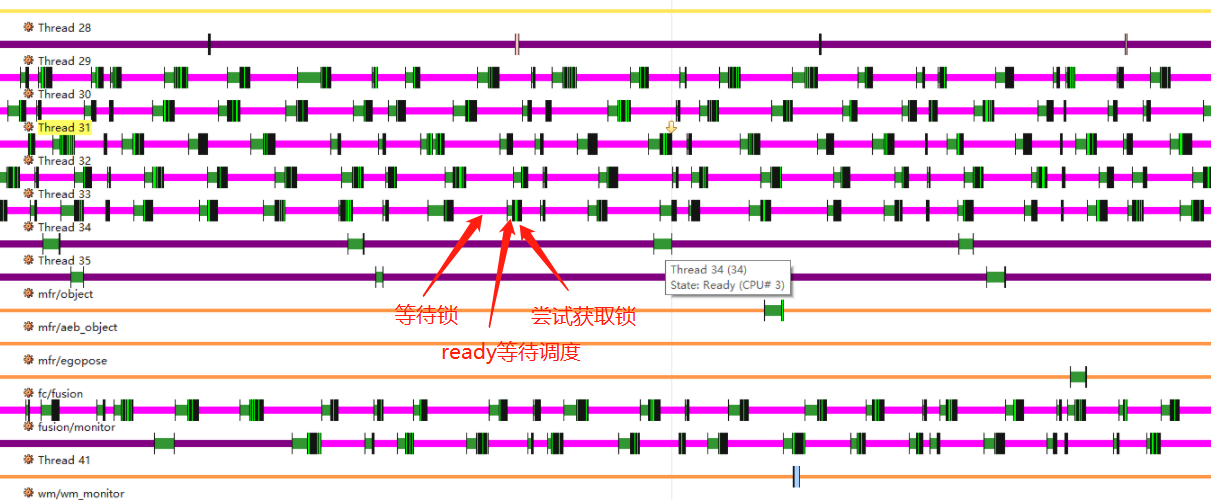
锁抢占另一方面,会导致严重的CPU占用问题。QNX提供的libc,在获取锁时如果拿不到,会以spintrylock自旋方式重试10次,这期间一直占用着CPU,如下图
QNX的强优先级机制,如果当前拿不到锁,而且如果锁当前被同一个CPU上的线程占用,则spin10次也是徒劳,只能等尝试失败后进入Mutex等待态;
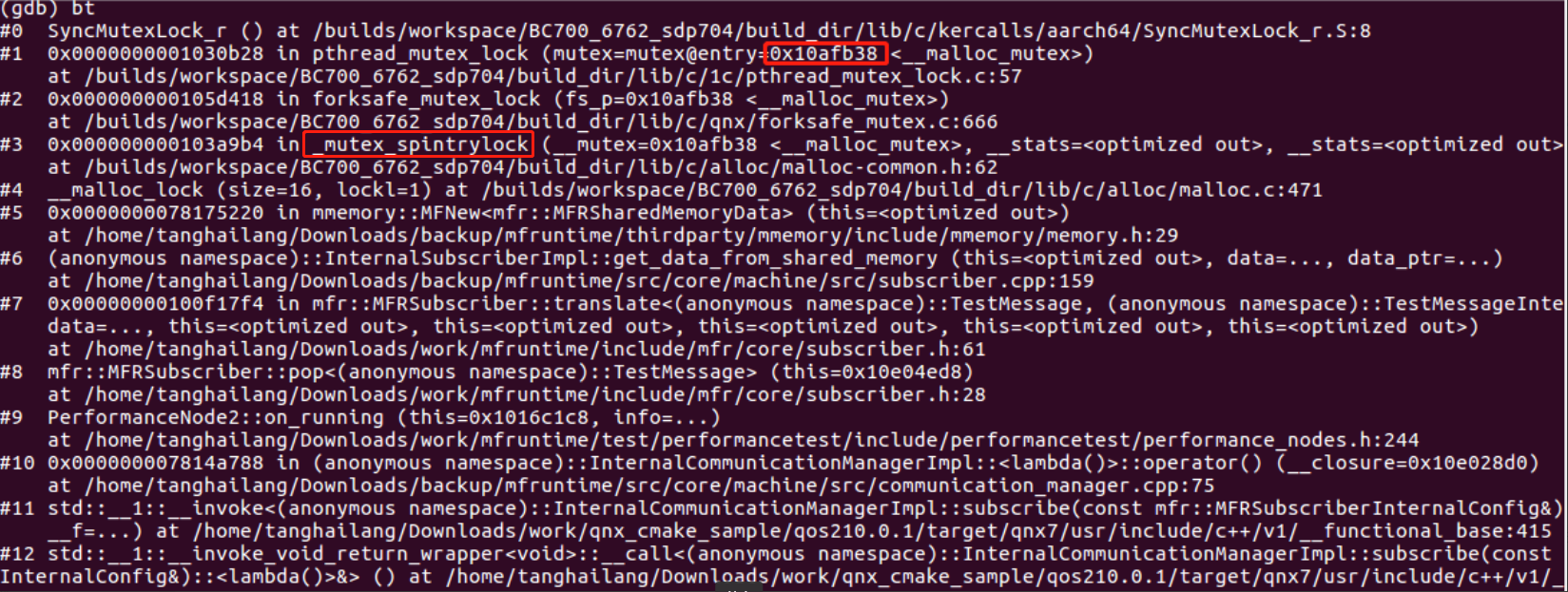
调用栈:
验证
通过配置MEMORY_HOLD=1的malloc选项,让free的内存永远不还给操作系统,尽量多的缓存到用户层,发现全系统的性能可以有较大的提升,从原来的1~2fps提升到9fps;但是这种方式会导致内存泄露,只能当成临时的手段walkaround;
通过使用tcmalloc替换libc的malloc,也基本可以达到同样的优化效果;tcmalloc QNX官方不支持(可提供独立的付费支持),存在一定的技术风险;

















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









