







0 - 写在前面
本系列共四篇,为林轩田机器学习基础篇学习笔记。主要内容可以总结概括为:线性模型通过非线性的变换可以得到非线性的模型,增强了模型对数据的拟合能力,但这样导致了在机器学习领域中一个很常见的问题,过拟合。为了解决这个问题引入了正则化因子(规则化因子)。而为了解决正则化因子的选择,模型的选择以及超参数的选择等问题引入了 validation v a l i d a t i o n 的相关方法。
- 机器学习笔记- Nonlinear Transformation N o n l i n e a r T r a n s f o r m a t i o n
- 机器学习笔记- Hazard of Overfitting H a z a r d o f O v e r f i t t i n g
- 机器学习笔记- Regularization R e g u l a r i z a t i o n
- 机器学习笔记- Validation V a l i d a t i o n
1 - 什么是过拟合
在上一篇中我们讲到将线性模型( linear model l i n e a r m o d e l )加上非线性的转换( nonlinear transform n o n l i n e a r t r a n s f o r m )就可以很方便的产生非线性的模型来扩展我们学习的能力,但是这样做的缺点是要付出额外的模型复杂度( model complexity m o d e l c o m p l e x i t y )代价。正是这个额外的模型复杂度会造成机器学习中一个很容易出现和很难解决的问题,过拟合的问题,本小节先分析过拟合产生的原因, 然后给出解决的方法。
1.2 - 泛化能力(Gad Generalization)
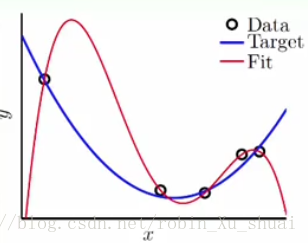
以上是一个一维的回归分析的例子。一共有 5 5 个资料点,随机产生, y y 是将带入一个二次多项式然后再加上一点点 noise n o i s e 得到的。所以最佳的回归曲线应该是蓝色的那条二次曲线。但是由于事先是不知道的, 所以有可能会使用四次的多项式来做回归分析对这 5 5 个点进行拟合。如何用四次的多项式来做回归呢?次的特征转换+线性回归就可以得到一个 4 4 次的多项式。这样可以得到一个唯一的次多项式在这 5 5 个点上的(训练误差为0),也就是这个四次多项式(图中的红色的线)会穿过这 5 5 个点,但是我们知道其实这条线的是非常大的。当 VC dimension V C d i m e n s i o n 很大时候, Ein E i n 就会很低,此时 Eout E o u t 就会很大,这样的情形被称为是 bad generalization b a d g e n e r a l i z a t i o n ,通俗的讲,这样的模型不能很好的举一反三,泛化能力很差。
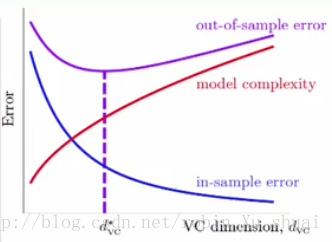
从上图可以看出, 随着 dvc d v c 不断的增大, 会发现 in-sample error in-sample error ,即 Ein E i n 在不断的下降,但是模型复杂度( model complexity m o d e l c o m p l e x i t y )在不断的上升,所以 out-of-sample error out-of-sample error ,即 Eout E o u t 会先降后升。如果 dvc d v c 从 d∗vc d v c ∗ (最佳的 dvc d v c )再向右移,这时把 fitting f i t t i n g 做好了,但是太过头了,此时 Eout E o u t 升高了, 我们把这种情况叫做 overfitting o v e r f i t t i n g 。相对于 overfitting o v e r f i t t i n g 来说,还有 underfitting u n d e r f i t t i n g , 从 d∗vc d v c ∗ 向左移动就会出现这种情况,但是这种情况是比较好解决的问题,只需要增加模型的复杂度,即使用比较复杂的特征转换就可以解决,这种情况在上一篇中给出了解决方案。
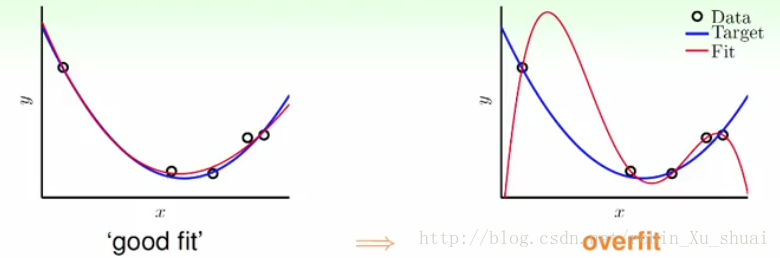
1.3 - 过拟合的成因
使用开车出事故来类比过拟合的问题。目的是更加生活化的了解
overfitting
o
v
e
r
f
i
t
t
i
n
g
是怎么一回事。 开车出事故可能是什么原因造成的呢?例如说,可能是因为开太快。对应到在
learning
l
e
a
r
n
i
n
g
中就是我们使用了太过复杂的模型,本来是二次的多项式产生的数据,但是使用了四次多项式去拟合,导致了太大的模型复杂度;另一个
overfitting
o
v
e
r
f
i
t
t
i
n
g
的原因可能是数据本身有
noise
n
o
i
s
e
,这个对应到开车的例子中可以认为是路不平,当路不平但是车开的很快的时候自然就很容易出事故。也就是当数据本身有
noise
n
o
i
s
e
而你使用了太过于复杂的模型的时候就会很容易出现过拟合的情形;另一个我们需要注意的问题是资料量的大小,如果资料量很多的时候,比较不容易会有
overfitting
o
v
e
r
f
i
t
t
i
n
g
的情况出现。例如如果你对路况比较熟悉,那么就算路况不好, 你还是有把握不出事故。
所以当我们对资料的认识是有限的-对路况不是很了解,并且这些资料又是有噪声的-路面又不平,而我们又使用了比较复杂的模型-开车很快,这样就很有可能过拟合-出车祸。
综合以上的说法,过拟合的三个主要的成因是:
- 使用了太过复杂的模型(车开太快)
- 存在噪声(路面不平)
- 数据量不够多(路况不清楚)
2 - 噪声和数据量对过拟合的影响
这节通过一些实验结果来进一步了解 overfitting o v e r f i t t i n g 的成因。现在有两笔一维空间中的资料用来做回归分析,
- 第一笔资料:使用某个 10 10 次多项式作为目标函数,即左图中蓝色的那条线,并且在该 10 10 次多项式上加上 noise n o i s e , 得到资料点(图中黑色的点)
- 第二笔资料:使用一个 50 50 次多项式作为目标函数,但是不加 noise n o i s e 。 50 50 次多项式和数据点如右图所示。
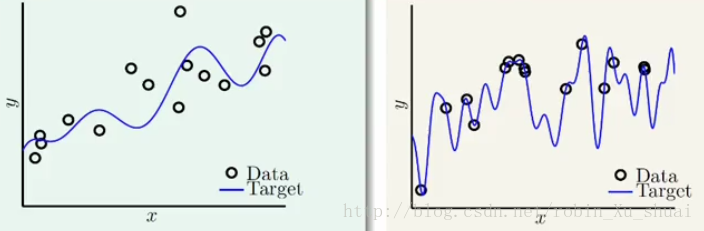
我们看看在这样的数据设定下,什么时候会出现
overfitting
o
v
e
r
f
i
t
t
i
n
g
的问题。
假设现在有两个不同的
learning model
l
e
a
r
n
i
n
g
m
o
d
e
l
: 第一个只考虑使用所有的二次多项式来对需要学习的数据进行拟合,
g2∈H2
g
2
∈
H
2
;另一个考虑使用所有的十次多项式(十次以下也考虑)来对数据进行拟合,
g10∈H10
g
10
∈
H
10
。可以理解为有两个人,一个只会做二次的,一个比较厉害会做所有十次以下的,他们分别来对数据进行拟合。
下图是使用二次和十次多项式分别对两种数据进行拟合的结果:
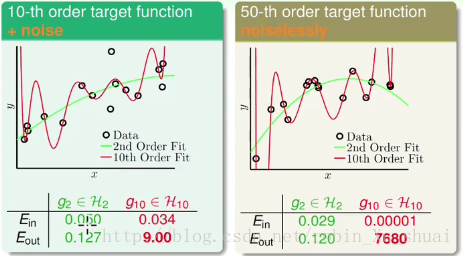
可以看出,虽然 g10 g 10 在 Ein E i n 上都要小于 g2 g 2 ,但是 g10 g 10 的 Eout E o u t 却都很大,所以从 g2 g 2 切换到 g10 g 10 的过程中发生了 overfitting o v e r f i t t i n g 。
在案例一目标函数是十次多项式且有噪声的例子中我们看到:
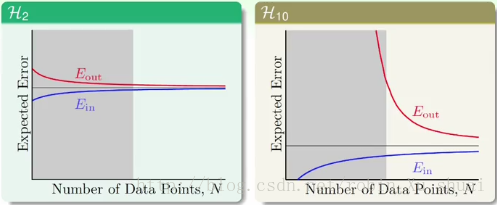
即使原本的数据就是由十次多项式产生的,但是有噪声,那么可能使用十次的假设函数依然得不到很好的效果。反而使用简单的假设函数会得到更好的结果。或者说就算你知道你的目标是十次多项式,但是你用十次多项式来拟合未必就会做的很好。为什么会这样呢?下面给出了使用二次模型和十次模型的学习曲线 learning curve l e a r n i n g c u r v e :
横轴是数据量的大小,图中的灰色区域代表的是数据量比较少的情形,这个时候可以看到:- 使用简单的模型下 Ein E i n 和 Eout E o u t 之间的差距比使用复杂的模型下 Ein E i n 和 Eout E o u t 之间的差距要小很多。
- 当然当数据量足够多的时候,使用复杂的模型得到的 Expected Error E x p e c t e d E r r o r 是低于使用简单的模型所能得到的。
所以当资料量不多的时候,使用简单的模型可能会更好的解释这些资料。因为有噪声的存在,复杂的模型可能在过多的关注这些噪声,导致“跑偏”了。
在案例二目标函数是 50 50 次多项式且没有噪声:
为什么在没有 noise n o i s e 的情况下, g10 g 10 还是做的不好呢?
事实上当我们想要学习的东西很复杂的时候,这个复杂度实际上也产生了和 noise n o i s e 一样的影响。一个 50 50 次多项式产生的数据对于二次多项式和十次多项式来说都是 noise n o i s e 。 所以在这个例子中,还是 g2 g 2 做的比较好。
3 - Deterministic Noise
3.1 - A detailed experiment
我们想要知道的是:什么时候要特别的小心
overfitting
o
v
e
r
f
i
t
t
i
n
g
会发生?
我们把产生资料的过程分成两个部分: 一个是
target function
t
a
r
g
e
t
f
u
n
c
t
i
o
n
;另一个是
noise
n
o
i
s
e
,假设噪声是高斯分布的。
- Qf Q f 表示多项式的次数,
- N N 表示资料量,
- 表示 noise n o i s e 的强度。
接下来将分析这三个变数对
overfitting
o
v
e
r
f
i
t
t
i
n
g
的影响。同样的我们使用上一小节中的两个模型来对以上产生的数据进行学习,一个是
g2∈H2
g
2
∈
H
2
,包含所有的二次多项式的假设集;另一个是
g10∈H10
g
10
∈
H
10
,包含所有的十次多项式的假设集。这里我们知道一定有
Ein(g10)
E
i
n
(
g
10
)
≤
≤
Ein(g2)
E
i
n
(
g
2
)
。
现在我们定义一个衡量
overfit
o
v
e
r
f
i
t
的指标:
Eout(g10)
E
o
u
t
(
g
10
)
-
Eout(g2)
E
o
u
t
(
g
2
)
,如果这个值很大,表示
overfit
o
v
e
r
f
i
t
很严重。如果这个值不是很大的话表明
overfit
o
v
e
r
f
i
t
不严重。接下来给出的图将说明的问题是, 在各种不同的条件下:不同的
N
N
, 不同的, 不同的
ϵ2
ϵ
2
, 什么时候
overfitting
o
v
e
r
f
i
t
t
i
n
g
最严重。
图中的颜色代表 overfit o v e r f i t 的程度,红色表示过拟合很严重,也就是两个 Eout E o u t 的差距非常的大;蓝色表示过拟合不是很严重,也就是说, g10 g 10 表现的更好。
3.2 - 结果1
Qf=20 Q f = 20
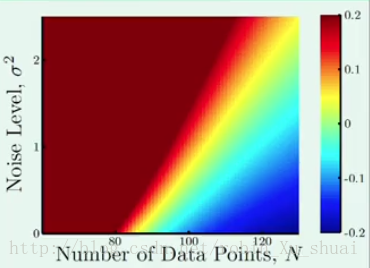
结论:
横轴为数据量,纵轴为噪声的强度,数据由20次多项式产生。
- 当资料很少, noise n o i s e 很多的时候, overfit o v e r f i t 很严重;
- 当资料很多, noise n o i s e 很少的时候, overfit o v e r f i t 不严重。
这是一个很容易理解的结果。
3.2 - 结果2
σ2=0.1 σ 2 = 0.1
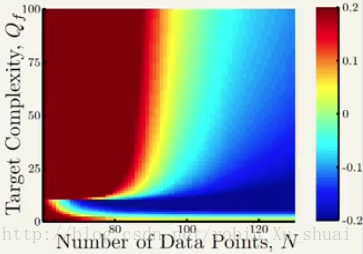
上面这个图中,横轴还是资料的量;纵轴表示的是目标函数的复杂度。
结论:
- 当资料很少,目标函数很复杂的时候, overfit o v e r f i t 很严重;
- 当资料很多,目标函数不是很复杂的时候, overfit o v e r f i t 不严重。
综合以上的两个图,高斯噪声对 overfit o v e r f i t 有很大的影响,我们称之为 stochastic noise s t o c h a s t i c n o i s e ;目标函数的复杂度对于 overfit o v e r f i t 也有很大并且是类似的影响, 我们将其称为 deterministic noise d e t e r m i n i s t i c n o i s e 。所以我们得到 overfit o v e r f i t 发生的情形可以总结为以下的四点:
- 资料量太少的时候(两幅图的左侧)
- stochastic noise s t o c h a s t i c n o i s e 太大的时候(第一幅图的左上角)
- deterministic noise d e t e r m i n i s t i c n o i s e 太多的时候(第二幅图的左上角)
- 使用的模型的复杂度太高的时候(第二幅图的左下角,目标数据是由低于10次的多项式产生的,但是用了10次的多项式来拟合)
3.3 - Deterministic Noise
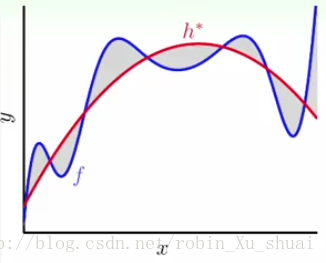
通过上面的谈论可以知道,当目标函数太过复杂的时候, 其对过拟合的影响和数据中的噪声差不多。例如 h∗ h ∗ 是假设集中最好的,但是对于很复杂或者是更高次的目标函数来说,很多地方依然 capture c a p t u r e 不到。图中的灰色区域就是我们所说的 deterministic noise d e t e r m i n i s t i c n o i s e 。 所以从这个意思上来说,目标函数如果太复杂的话和噪声对 overfit o v e r f i t 的影响是差不多的。但是还有有一点的区别的:因为如果我们使用更为复杂的 model m o d e l (假设集)的话,理论上说 deterministic noise d e t e r m i n i s t i c n o i s e 应该会变小,但是同时模型的复杂度的提升也会造成 overfit o v e r f i t 。
4 - 避免过拟合
下面给出了解决 overfitting o v e r f i t t i n g 的一些思路:
- 从简单的模型开始
- data cleaning/data pruning d a t a c l e a n i n g / d a t a p r u n i n g
- data hinting d a t a h i n t i n g
- regularization r e g u l a r i z a t i o n
- validation v a l i d a t i o n
本篇对 data cleaning/data pruning d a t a c l e a n i n g / d a t a p r u n i n g 和 data hinting d a t a h i n t i n g 进行简单的讲解, regularization r e g u l a r i z a t i o n 和 validation v a l i d a t i o n 将在后续文章中介绍。
4.1 - Data Cleaning/Pruning

当使用某些手段发现有的样本存在明显错误的时候,例如该样本本身标注是 × × ,但是到其他的 × × 距离很远,或者到其他的 ◯ ◯ 距离很近,或者利用已经得到的训练器在该样本上划分错误,例如左上角的样本“5”那样,这时可以采取的方法有:
- data cleaning d a t a c l e a n i n g :将数据的 label l a b e l 修正过来;
- data pruning d a t a p r u n i n g :将数据扔掉。
4.2 - Data Hinting
相当于在深度学习中的
data argument
data argument
。

在手写数字的识别中,如果手头上的资料不是很多的时候,可以对已有的资料做一些平移,小幅度的旋转等操作,这样可以得到更多的资料,这些资料被称为 virtual example v i r t u a l e x a m p l e 。但是要注意的是这样的资料不再是 IID I I D 的来自原来的分布。
5 - Summary
本篇介绍了过拟合这个在机器学习中非常重要的问题。当数据存在噪声,当模型的复杂度太高,当数据量不够, 或者当目标函数太过于复杂的时候,过拟合都会出现。本篇介绍了简单的面向 data d a t a 的用来减低过拟合的方法,这些方法可能会有效,也可能不会。之后会介绍专门用来解决过拟合的系统的方法。















 196
196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









