







 超级会员免费看
超级会员免费看
 区域分裂合并算法是一种图像分割方法,通过不断分裂和聚合满足特定条件的区域来实现。基本思想是根据区域特征一致性进行分裂或合并。在无法继续分裂时,再寻找相邻相似区域进行合并。该过程可以避免区域生长方法中从单个像素开始的步骤,同时允许在较大区域基础上进行合并。图像分割示例展示了算法的有效性,但也强调选择合适的均匀性测试准则P的重要性,以防止‘方块效应’。
区域分裂合并算法是一种图像分割方法,通过不断分裂和聚合满足特定条件的区域来实现。基本思想是根据区域特征一致性进行分裂或合并。在无法继续分裂时,再寻找相邻相似区域进行合并。该过程可以避免区域生长方法中从单个像素开始的步骤,同时允许在较大区域基础上进行合并。图像分割示例展示了算法的有效性,但也强调选择合适的均匀性测试准则P的重要性,以防止‘方块效应’。
2. 區域分裂合並
區域分裂合並算法的基本思想是先確定一個分裂合並的准則,即區域
反復進行拆分和聚合以滿足限制條件的算法。
令R表示整幅圖像區域並選擇一個謂詞P。對R進行分割的一種方法
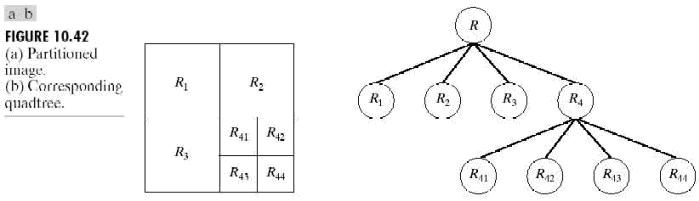
如果只使用拆分,最後的分區可能會包含具有相同性質的相鄰區域。
前面的討論可以總結為如下過程。在反復操作的每一步,
l.對於任何區域Ri,如果P(Ri)=FALSE,
2.將P(Rj∪Rk)=TRUE的任意兩個相鄰區域Rj和Rk
3.當再無法進行聚合或拆分時操作停止。
可以對前面講述的基本思想進行幾種變化。例如,
例10.17 拆分和聚合
圖10.43(a)顯示了一幅簡單的圖像。如果在區域Ri內至少

如前面的例子中所使用的屬性那樣,
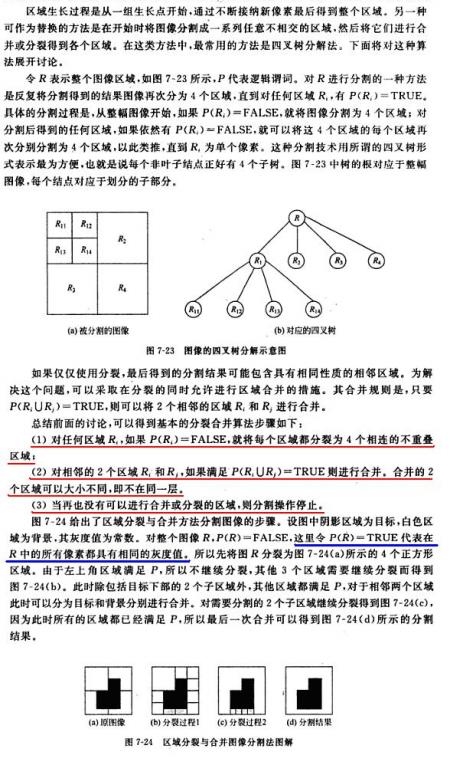
1. 把一幅圖像分成4份,
2. 對於那些不需要分裂的那些份圖像可以對其進行
// 代碼
// 區域分裂合並的圖像分割
// nOffSetLne是行偏移量
// 由於分裂的層數太多了, 使用遞歸將使內存空間堆棧溢出
// 解決方法是使用一個堆棧對要分裂的塊入棧
// 使用堆棧的方法類似在"區域生長"的實現方法
#include <stack>
struct SplitStruct
{
unsigned int nWidth;
unsigned int nHeigh;
unsigned int
unsigned int
};
void AreaSplitCombineEx(BYTE* image0, // 源圖像數據
unsig
unsig
unsig
unsig
unsig
unsig
{
std::stack<SplitStruct> nMyStack;
SplitStruct splitStruct, splitStructTemp;
splitStruct.nWidth
splitStruct.nHeigh
splitStruct.nOffSetWidth
splitStruct.nOffSetHeigh
nMyStack.push(
int i, j;
int nValueS[2][2]; //
int nAV;
int nWidthTemp[3], nHeightTemp[3], nTemp;
int nWidth, nHeigh;
int n, m, l;
double dOver;
while(!nMyStack.empty())
{
splitStruct = nMyStack.top();
nMyStack.pop();
n = (splitStruct.nOffSetHeigh * nAllWidth + splitStruct.nOffSetWidth);
// 1. 把圖像分成2 * 2 塊,
nWidthTemp[0] = 0;
nWidthTemp[2] = (splitStruct.nWidth + 1) / 2;
nWidthTemp[1] = splitStruct.nWidth - nWidthTemp[2];
nHeightTemp[0] = 0;
nHeightTemp[2] = (splitStruct.nHeigh + 1) / 2;
nHeightTemp[1] = splitStruct.nHeigh - nHeightTemp[2];
// 計算每一塊圖像的屬性值
int nValue;
int nValueTemp;
nAV = 0;
for(i = 1; i < 3; ++i)
{
for(j = 1; j < 3; ++j)
{
nValue = 0;
m = (n + nAllWidth * nHeightTemp[i - 1] + nWidthTemp[j - 1]);
for(nHeigh = 0; nHeigh < nHeightTemp[i]; ++nHeigh)
{
for(
{
l = (m + nAllWidth * nHeigh + nWidth) * 4;
//
}
}
if(
{
continu
}
if(
{
l = m * 4;
if((0.
// 這個值可以動態設定
{
}
else
{
}
continu
}
// 各塊圖像的灰度平
nValueS[i - 1][j - 1] = nValue / (nHeightTemp[i] * nWidthTemp[j]);
// 2. 對每一塊進行判斷是否繼續分裂(注意分裂的原則)
// 我這裡的分裂原則
if(nValueS[
{
}
else
{
// 3. 如果不需要分裂, 則進行合並
for(
{
fo
{
}
}
}
}
}
}
return;
}
該代碼的效果也不是太好,主要是分裂准則不好確定
區域分裂合並中 最初使用每塊圖像區域中極大與極小灰度值之差是
看均方誤差最小的情況

其中C是區域R中N個點的平均值。
相對於區域生長而言,















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









