







 一.背景介绍ClickHouse 是俄罗斯Yandex在2016年年开源的⼀一个⾼高性能分析型SQL数 据库,主要⾯面向OLAP场景。开源之后,凭借优异的查询性能,受到业界的青睐。优点:1)为了高效的使用CPU,数据不仅仅按列存储,同时还按向量进行处理;2)数据压缩空间大,减少io;处理单查询高吞吐量每台服务器每秒最多数十亿行;3)索引非B树结构,不需要满足最左原则;只要过滤条件在索引列中包含即可;即使在使用的数据不在索引中,由于各种并行处理机制ClickHouse全表扫描的速度也很快;
一.背景介绍ClickHouse 是俄罗斯Yandex在2016年年开源的⼀一个⾼高性能分析型SQL数 据库,主要⾯面向OLAP场景。开源之后,凭借优异的查询性能,受到业界的青睐。优点:1)为了高效的使用CPU,数据不仅仅按列存储,同时还按向量进行处理;2)数据压缩空间大,减少io;处理单查询高吞吐量每台服务器每秒最多数十亿行;3)索引非B树结构,不需要满足最左原则;只要过滤条件在索引列中包含即可;即使在使用的数据不在索引中,由于各种并行处理机制ClickHouse全表扫描的速度也很快;
一.背景介绍
ClickHouse 是俄罗斯Yandex在2016年年开源的⼀一个⾼高性能分析型SQL数 据库,主要⾯面向OLAP场景。开源之后,凭借优异的查询性能,受到业界的青睐。
优点:
1)为了高效的使用CPU,数据不仅仅按列存储,同时还按向量进行处理;
2)数据压缩空间大,减少io;处理单查询高吞吐量每台服务器每秒最多数十亿行;
3)索引非B树结构,不需要满足最左原则;只要过滤条件在索引列中包含即可;即使在使用的数据不在索引中,由于各种并行处理机制ClickHouse全表扫描的速度也很快;
4)写入速度非常快,50-200M/s,对于大量的数据更新非常适用;
ClickHouse并非万能的,正因为ClickHouse处理速度快,所以也是需要为“快”付出代价。选择ClickHouse需要有下面注意以下几点:
1)不支持事务,不支持真正的删除/更新;
2)不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下;
3)sql满足日常使用80%以上的语法,join写法比较特殊;最新版已支持类似sql的join,但性能不好;
4)尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作,因为ClickHouse底层会不断的做异步的数据合并,会影响查询性能,这个在做实时数据写入的时候要尽量避开;
5)Clickhouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的cpu去执行,所以ClickHouse不能支持高并发的使用场景,默认单查询使用cpu核数为服务器核数的一半,安装时会自动识别服务器核数,可以通过配置文件修改该参数;
二.支持应用场景
1.数据摄入
ClickHouse可以覆盖实时与离线两种场景:
实时:数据流可以通过kafka/flink/sparkstreaming实时处理后,通过JDBC的方式批量导入到ClickHouse中。
离线:数据落地HDFS ODS层,离线通过Spark,MR或其他方式的batch形式导入到ClickHouse中。
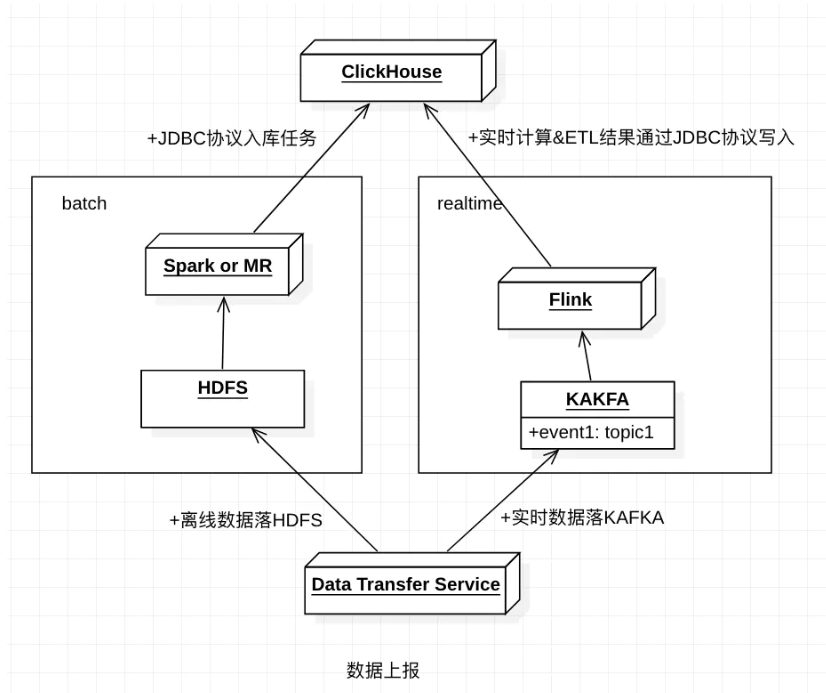
2. 数据存储
存储上使用多磁盘结构,可以充分利用物理机多磁盘特性,增加存储量和磁盘IO吞吐。
ClickHouse可以通过配置文件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1870
1870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









