







selective search算法是一种图像分割的算法,能够找到图像中可能存在目标物体的区域,是RCNN算法的基础。
参考:
- 《Selective Search for Object Recognition》代码及论文 https://www.koen.me/research/selectivesearch/
- 算法python实现 https://github.com/AlpacaDB/selectivesearch
- https://www.cnblogs.com/zyly/p/9259392.html
1、快速开始
作者主页上给出了算法的MATLAB实现,github上有一个较为简单的实现,https://github.com/AlpacaDB/selectivesearch。下面的例子基于github上的实现,可以通过 pip install selectivesearch 安装。
测试代码如下,用的是http://www.lenna.org/下载的lenna图片。
# coding:utf-8
from selectivesearch import selective_search
import cv2
img = cv2.imread("len_std.jpg")
img_lbl, regions = selective_search(img, scale=500, sigma=0.3, min_size=10)
print("regions counts", len(regions))
candidates = set()
for r in regions:
# lenna标准图的大小是256乘256,这里选取像素个数在(5000,6000)的候选框
if r['size'] < 5000 or r['size'] > 6000:
continue
candidates.add(r['rect'])
print("candidates number",len(candidates))
for x,y,w,h in candidates:
cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,255,0),thickness=2)
cv2.imwrite("lena_out.png",img)
cv2.imshow("",img)
cv2.waitKey(0)程序运行后找到了123个区域,在这些候选区域中限制像素个数处于(5000,6000),经过过滤剩下了3个候选框,如下图所示。可以看出中间的框基本上完整的包括了lenna的脸部。
2、selective search基本流程
selective search算法的基本思想是先将整张图片分成多个较小的区域,然后再通过计算这些区域之间的相似度,将比较相似的两个区域融合在一起,以此类推。算法流程如下所示。
上面算法中提到的文献[13]是Efficient Graph-Based Image Segmentation,这篇论文提出了一个图像分割的方法,具体细节可以参考https://blog.csdn.net/root_clive/article/details/93973621。
上述算法中的要点在于如何计算两个区域之间的相似度,论文中给出的计算公式为:
其中,为了保证多样性,一般
取1。两个区域的相似度考虑了4个不同的角度,分别为:
(1) 颜色相似度
将某个区域内的像素值分成25个bins,那么3个通道就组成了长度为75的特征向量
,然后对
进行L1归一化(也就是给
的每一个值除以区域
内像素点的个数),特征向量
实际上表示了像素值的分布,于是区域
和区域
的颜色相似度为:
上面这个计算式度量了两个区域像素值分布的重叠程度。当两个区域合并之后,新的区域的特征向量就是合并前各个特征向量之和,但是由于特征向量
进行了L1归一化,所以没有归一化的特征向量为
,因此下面的公式用来计算合并后的特征向量。
(2) 纹理相似度
论文中参考了《Exploring features in a bayesian framework for material recognition》中的做法(没有仔细研究,大意是选取了8个方向,使用方差为1的高斯滤波,然后将结果分成10个bins,那么每个通道就会有80个bins,3个通道总共240个bins,然后进行L1归一化)。纹理相似度的计算方法和颜色相似度的计算方法相同,如下所示:
两个区域合并后的纹理特征向量计算方法也和颜色特征合并计算方法类似。
(3) 让较小的区域较早的融合
如果两个区域比较小的话,这个值相应会比较大。
(4) 度量两个区域的匹配程度
如果某一个区域被另一个区域完全包裹的话,那么这两个区域就应该被融合,或者两个区域几乎不接触,这两个区域应该就属于不同的区域,根据这样的思想,论文中给出了一种简单的计算公式。
其中是区域
和区域
的外接矩。
2、候选框过滤
在文章开始部分我们通过selective search从一张图中提取出来123个候选框,数量显然是太多了,不便于后面的特征提取和分类,论文中提出了一种过滤的策略。
首先论文提出了3种不同的方案,如下图所示,第一种方案使用HSV颜色空间,C+T+S+F分别是前面介绍的四种相似度,
,
,
,第二种方案是Selective Search Fast(RCNN论文中就是用的这种方案),分别用了HSV和Lab两种颜色空间,然后使用了C+T+S+F和T+S+F两种相似度计算方法,超参数k使用了50和100两个不同的值,因此总共会有
个分割结果。同理第三种方案会产生80个分割结果。
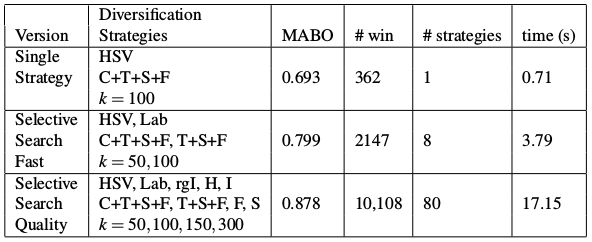
那么怎么将80种结果综合在一起呢?首先可以给不同的层级赋予不同的权重,这个算法是先将原图分割成很多个小区域然后再融合的,将最后一次融合的层级记为,层级
的时候权重为1,以此类推。将80个不同方案中不同层级的分割区域的权重相加,然后按照权重排序,排在前面的就是最可能存在有效目标的区域。
这里有个疑点,论文中没有明确指出,就是怎么寻找不同分割方案中的相同区域,如果要求两个区域必须所有像素位置相同似乎有些不可行,或者可以采用IOU来判断?
上面的方法存在一个问题,区域越大,在不同方案中出现的频率越高,叠加之后的概率越大,因此这种方法排序之后会倾向于找到较大的区域。论文中提出给权重乘以一个系数,其中RND是[0,1]之间的随机数。引入了随机之后,可以一定程度上避免较大区域一定排在前面的问题。
3、selective search应用于目标识别
在通过selective search算法将图形分割成多个区域之后,论文中提出了一种基于SVM的目标识别方法,下面的流程图来自论文。

在训练阶段,初始的正样本是ground-truth标注的框,用selective search从图中选出候选框,然后将这些候选框中和ground-truth重叠20%~50%的框作为负样本,将选出的负样本中重叠超过70%的只保留一个,论文中通过随机删除负样本使得每个类别的负样本数量在2000以下。然后从每个样本中提取360000个特征 (图像特征提取这一部分不是很了解,大意是提取SIFT特征和四层空间金字塔特征等),送入SVM(togram intersection kernel,这个核函数在图像分类中比径向基效果好)进行训练,训练中会迭代add hard negative examples。
在推断阶段,将selective search产生的候选区域提特征送入模型,按照得分高低排序,和最高得分框重叠超过30%的框将被删除。(SVM算法输出的是样本属于正样本或负样本,这个得分是怎么得出的?)















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









