






绝对引用和相对引用
在开始前,我想先说说一个搞笑的。昨天写完第二篇博客上网查了查,excel中"$"这个符号有专门名词的,但是我一直叫它锁,笑死。
以=a2来举例:
=a2的话我们拖拉公式就可以改变公式中的行和列,这就是相对引用
=$a$2的话我们拖拉公式无法改变行和列,这就是绝对引用
=a$2或=$a2的话我们拖拉公式要么改变行不改变列,要么改变列不改变行,这就是混合引用。
当然了,毕竟工作不是考试,叫什么其实没那么重要,能操作就行!
维度
那么回到正题,正如我在标题描述的那样。我的面试第二题,就是通过一张一维表来生成一张二维表。
什么是维度呢?简单地说,数据的维度,就是分析数据的角度。
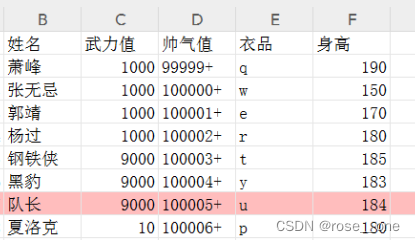
套用一下第二章的数据表(我偷我自己总没问题吧^_^)
第一列是各位大侠的姓名,是主列。那么后面几列其实就是分析各位大侠的一个角度,比如说武功多高,长得多帅,身材是不是魁梧。
一维表
数据表怎样算一维,也就是这张表里的数据,只用一个方面就可以定义。
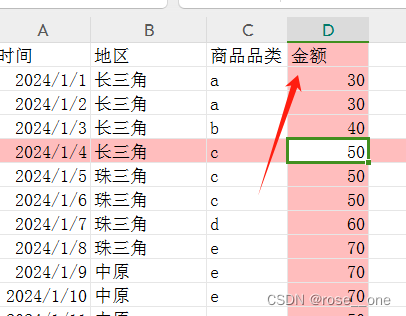
这张表是虚拟的电商后台,记录了什么时间,什么地区的客户购买了什么商品,且标注了金额。
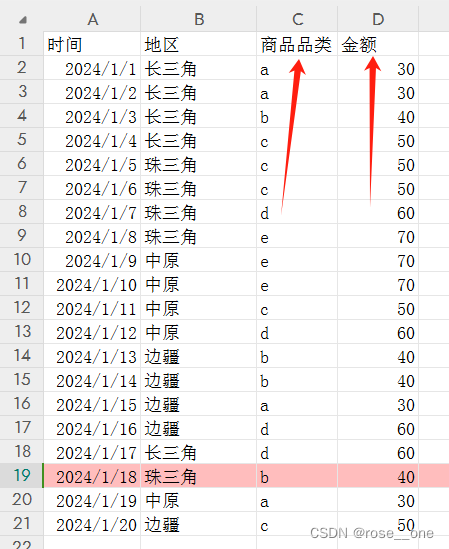
我们随便选择一个单元格,c8,它是d,就是商品的一种品类(文本型数据也是数据的一种)
另一个单元格,d8,它是60,就是说价格为数字60。
二维表
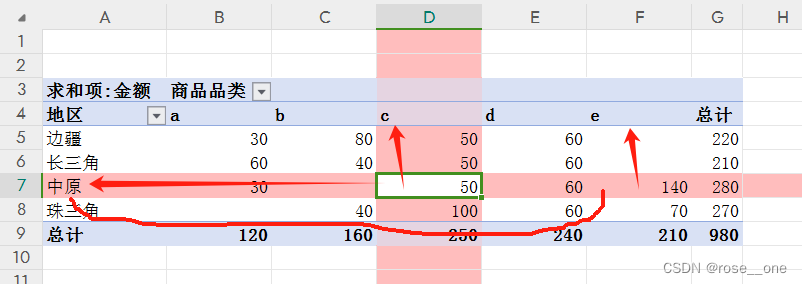
我使用数据透视表操作了上面的一维表,(ps:由于数据透视表是拖拽的,不好演示,所以我的博客里不会出现数据透视表的教程内容)
看单元格d7,它就不是普通的一个数50了。而是说中原地区购买的c商品的总金额。
也就是决定这个数据需要从两个方面考量了。地区和商品品类二者的共同作用(而一维表的数据就很单纯,时间就是时间,地区就是地区,金额就是金额,品类就是品类)
再看看f7单元格的值140,就是说中原地区购买的e商品总金额140。我们知道e的单价为70,所以这个单元格的数据表明了中原地区购买了2个e商品。
countif--条件计数
讲完纬度接下来讲两个函数,countif和sumif,也叫条件计数和条件求和。
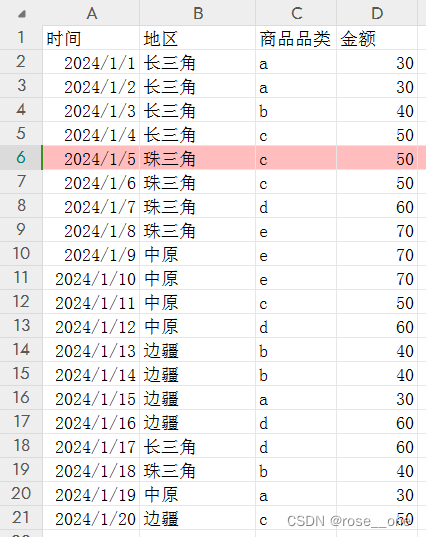
源数据在这,现在我们想求出a商品总共被购买了几次

在J6单元格输入公式:
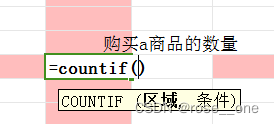
这个函数有两个参数,区域和条件。区域的话就是我们要在哪块区域去计数,条件就是我们的计数条件。因为我们需要的是a商品被购买了几次,所以区域是c列,条件就是a

这里插一嘴,公式里如果存在字符串的话需要英文状态下的双引号"",而不是中文状态的双引号“”。如果你要问我为什么,我会说我也不知道,它就是这样。
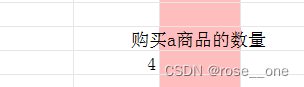
最终答案就是4,呼之欲出!
sumif--条件求和
现在我们想知道,a商品总共卖了多少钱

这里区域和条件还是跟上面一样,但是多了一个求和区域
在这里求和区域就是D列,毕竟我们需要的是a类产品的销售额总量


求和、计数
在excel表里,计数一般是指计算有几个单元格,而求和是指单元格内的数字相加。
所以求和列必是数字类型,而计数列都可以的了。
由此延伸一下,对countif和sumif另一个角度的理解
可以从筛选器的角度去理解这两个函数
还是跟上面一样,想要知道a类商品总共被购买了几次以及a类商品的总销售额
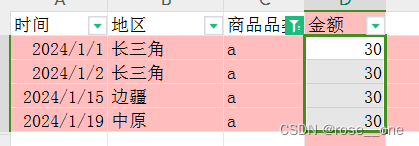
就可以看成把a筛选出来,countif就是计算有几个单元格(4个),sumif就是计算d列的单元格内数字之和(120)
面试第二题--一维表转二维表
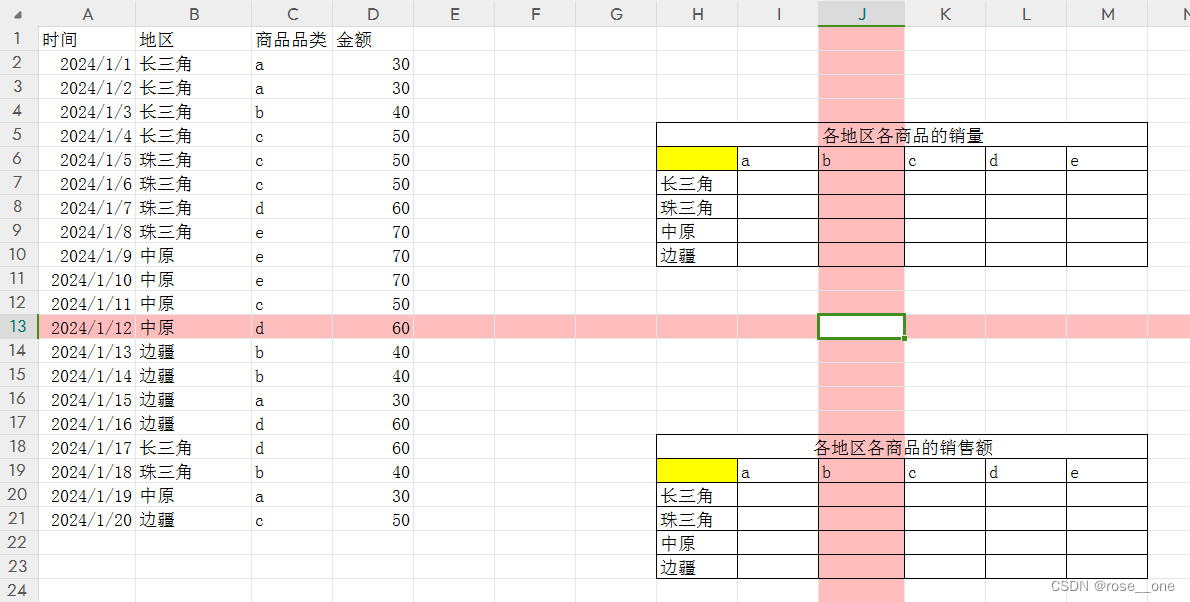
左边就是源数据,右边就是需要我们生成的数据表。
这里插一句,如果是分组、分类、计数、求和,其实数据透视表比这俩函数更方便直观。
但是!但是来了O(∩_∩)O,数据表的格式是死的(二维表),而通过在单元格里输入函数,我们最终的表格可以是多样化的(虽然但是。。。。在这确实还是二维表),而且通过函数生成,我们只修改源数据就可以自动生产需要的表格,这样就不需要每次都操作一次透视表,方便省力了许多呢^_^
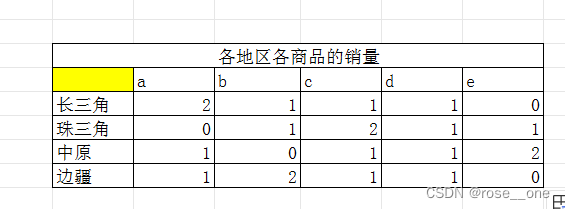
销量
首先!是销量
这里使用countifs函数,多条件计数。
原因就在于和第二章一样,我们需要在一个单元格里输入函数后通过自动填充来完成表格(快兮快)
每个单元格的计数条件一边就是纵列的地址,另一边就是横列的商品。
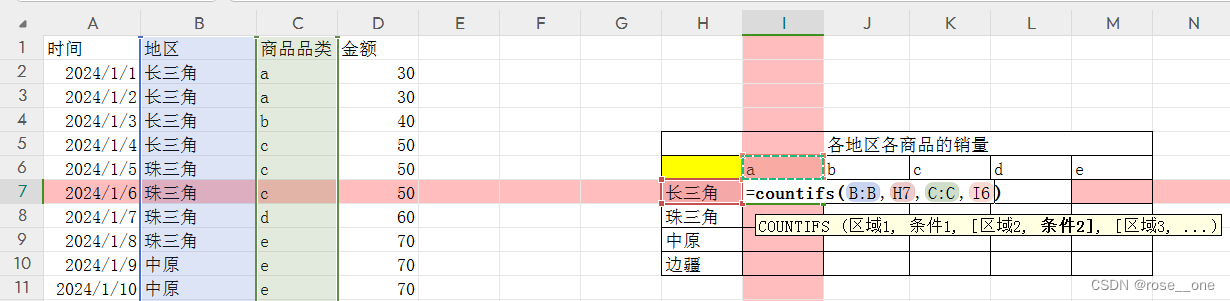
和第二章一样,通过想象移动来判断要给哪些参数上锁。
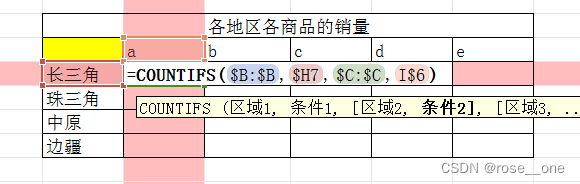
首先b:b和c:c当然是雷打不动的
然后是h7,它的列是不变的,行是可变的
横着的i6,它的行是不变的,列是可变的
因此如下:
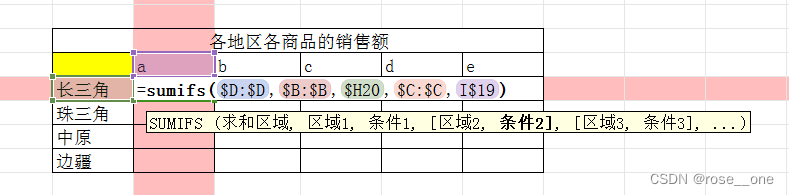
销售额
这个和上面的差不多,但是多了一个求和项
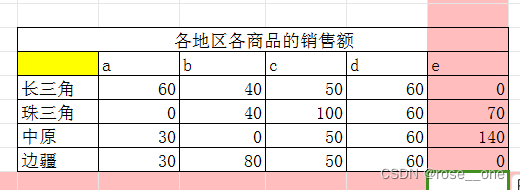
填充完毕如下:
劣势
上面讲过,计数函数对透视表的优势
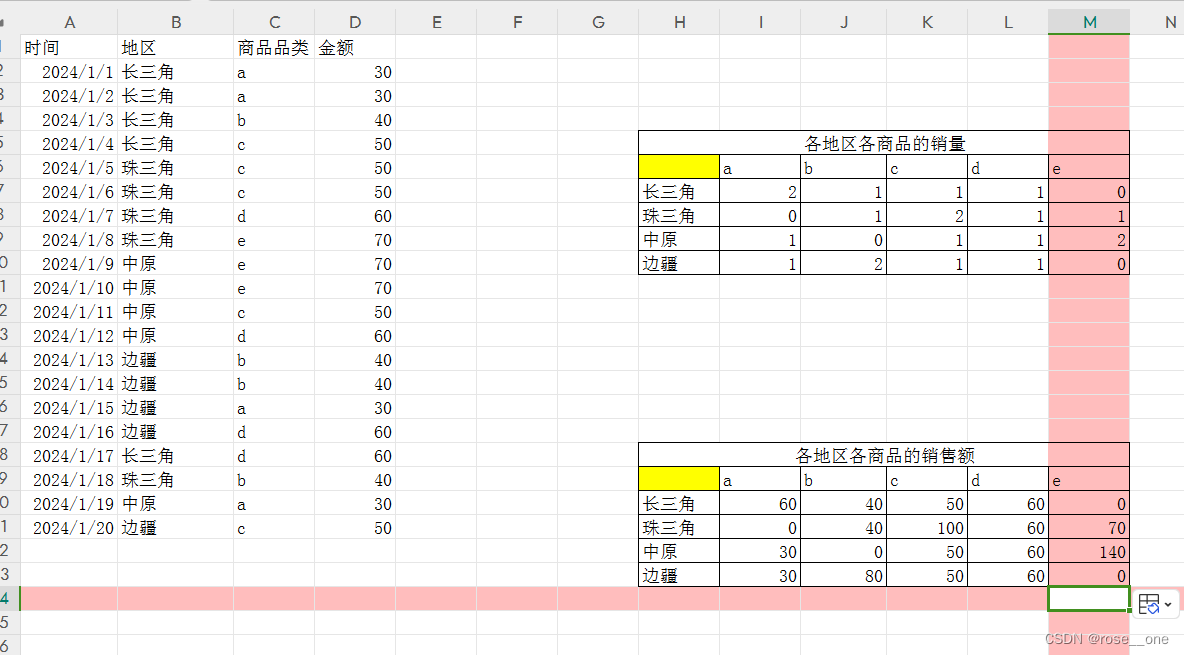
不仅能过使做的表灵活多变(因为使用数据透视表就只能是二维表了),而且更改源数据后可以实现报表的自动修改。我比较喜欢叫他报表自动化(是不是听起来很高大上^_^)
必须承认这个优势明显,但是劣势也是致命的
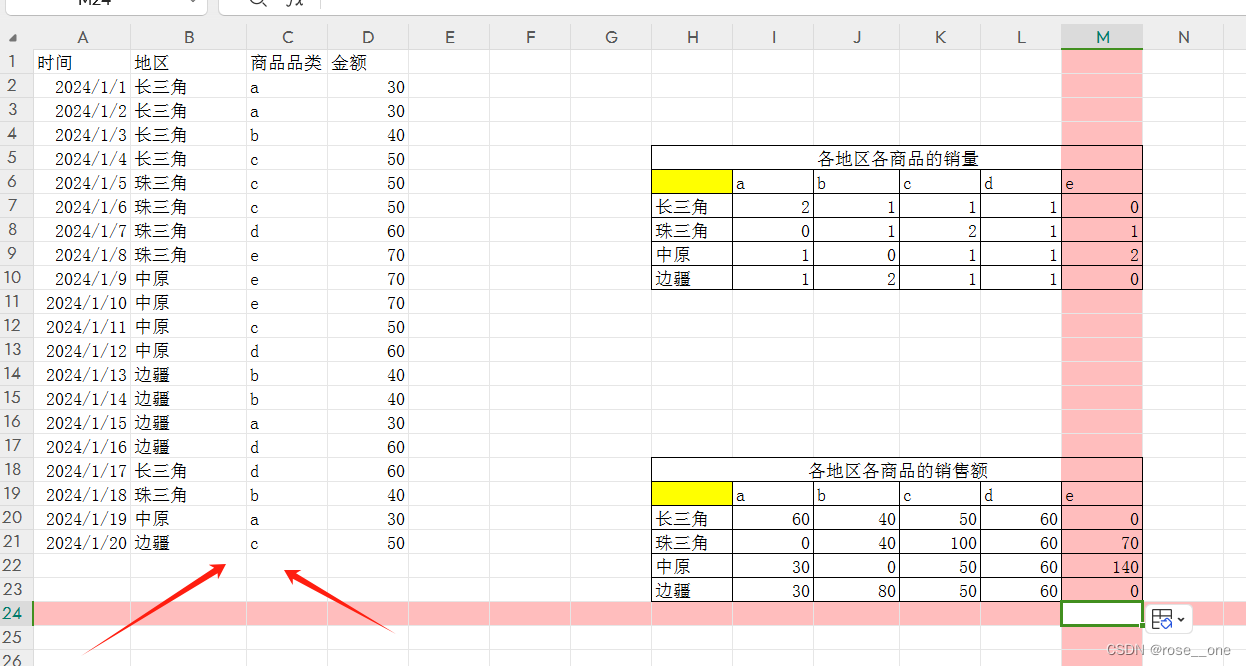
假如数据源的修改出现了异数,比如出现了东北地区,出现了z类商品、n类商品。那么在结果表里是无法体现的。这个时候数据透视表的好处就出来了,数据源中的分类它都可以给你搞定。
解决方法我有两种,对应着不同情况。
第一种,如果我们知道源数据的所有情况,那可以直接改表。比如地区有哪些我已经知道,总共有几类商品我也知道。我们的结果生成表,可以把所有情况的罗列出来先。

罗列之后,再使用函数,虽然有好多0,影响观感。但若是后续源数据有修改,这边就会自动修改。
第二种,我们不太能清查未来是否会有新的东西出现,出现的又会是什么。假设出现了o类商品,p类商品,但是在它出现之前我们都不会知道,这个时候应该怎么办呢。
答案是,出现之后再改变。出现了新产品,我们直接插入列,再把op填进去
然后再把整张表填充函数公式即可^_^















 8279
8279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









