







0. 问题描述
输入数据: X = ( x 1 , x 2 , . . . . , x m ) \mathbf{X} = (x_1, x_2,...., x_m) X=(x1,x2,....,xm), 相应标签 Y = ( y 1 , y 2 , . . . , y m ) \mathbf{Y} = (y_1, y_2, ..., y_m) Y=(y1,y2,...,ym).
目标:建立模型描述 X X X 和 Y Y Y 的关系。
1. 线性回归,LR
模型:
Y
=
w
X
+
b
Y = wX + b
Y=wX+b
使用平方误差作为模型损失函数:
L
=
∑
i
=
1
m
(
y
i
−
x
i
T
w
)
L = \sum_{i = 1}^{m}(y_i - x_i^T w)
L=i=1∑m(yi−xiTw)
矩阵表示:
L
=
(
y
−
X
w
)
T
(
y
−
X
w
)
L = (y - Xw)^T(y - Xw)
L=(y−Xw)T(y−Xw)
求解:
对w求导,得到:
w
^
=
(
X
T
X
)
−
1
X
T
y
\hat{w} = (X^TX)^{-1}X^Ty
w^=(XTX)−1XTy
2. 局部加权线性回归,LWLR
英文名称为:Locally Weighted Linear Regression.
在线性回归的基础上,引入一些偏差,从而降低预测的误差。
对预测的样本点赋予一定的权重。
LWLR使用“核”来对附近的点赋予更高的权重,常用高斯核:
w
(
i
,
i
)
=
e
x
p
(
∣
x
(
i
)
−
x
∣
−
2
k
2
)
w(i, i ) = exp(\frac{ |x^{(i) } - x | }{ - 2k^2 } )
w(i,i)=exp(−2k2∣x(i)−x∣)
k 为超参数。
模型损失函数
L = 1 2 [ W ( 1 ) ( y ( 1 ) − θ T x ( 1 ) ) 2 + W ( 2 ) ( y ( 2 ) − θ T x ( 2 ) ) 2 + ⋯ + W ( m ) ( y ( m ) − θ T x ( m ) ) 2 ] = 1 2 ∑ i = 1 m W ( i ) ( y ( i ) − θ T x ( i ) ) 2 \begin{aligned} \mathcal{L} &=\frac{1}{2}\left[W^{(1)}\left(y^{(1)}-\boldsymbol{\theta}^{T} \mathbf{x}^{(1)}\right)^{2}+W^{(2)}\left(y^{(2)}-\boldsymbol{\theta}^{T} \mathbf{x}^{(2)}\right)^{2}+\cdots+W^{(m)}\left(y^{(m)}-\boldsymbol{\theta}^{T} \mathbf{x}^{(m)}\right)^{2}\right] \\ &=\frac{1}{2} \sum_{i=1}^{m} W^{(i)}\left(y^{(i)}-\boldsymbol{\theta}^{T} \mathbf{x}^{(i)}\right)^{2} \end{aligned} L=21[W(1)(y(1)−θTx(1))2+W(2)(y(2)−θTx(2))2+⋯+W(m)(y(m)−θTx(m))2]=21i=1∑mW(i)(y(i)−θTx(i))2
其中, θ = ( w , b ) \boldsymbol \theta = (w, b) θ=(w,b)
求解的w :
w ^ = ( X T W X ) − 1 X T W y \hat{w} = (X^T W X)^{-1}X^TW y w^=(XTWX)−1XTWy
当数据的特征比样本点多时, 计算 ( X T X ) (X^TX) (XTX)为非满秩矩阵,求逆会出错。岭回归和Lasso回归都是解决这个问题
3. 岭回归Ridge regression
岭回归让 ( X T X ) (X^TX) (XTX)加上 λ I \lambda I λI来使得矩阵非奇异。
回归系数变成:
w
^
=
(
X
T
X
+
λ
I
)
−
1
X
T
y
\hat{w} = (X^T X + \lambda I )^{-1} X^T y
w^=(XTX+λI)−1XTy
而其本质上,则是求解这个最优化问题:
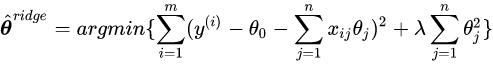
其中,
θ
=
w
\boldsymbol \theta = w
θ=w
注意到右侧添加了一个L2范数惩罚项。L2范数使得 θ \theta θ 的各分量不会过大(防止模型过拟合、降低模型复杂度),起到一个收缩作用;
岭回归一开始用来处理特征数比样本数多的情况,现在通过引入
λ
\lambda
λ来限制所有 w之和,通过加入该惩罚项来减少不重要的参数,在统计学叫缩减(shrinkage)。
4. Lasso 回归
Lasso回归使用 1 范数对 w 进行约束,约束条件为:
∑ k = 1 n ∣ w k ∣ ≤ λ \sum_{k = 1}^{n} | w_k | \leq \lambda k=1∑n∣wk∣≤λ
当λ很小的时候,一些系数会随着变为0,而岭回归却很难使得某个系数恰好缩减为0, Lasso容易获得稀疏解。
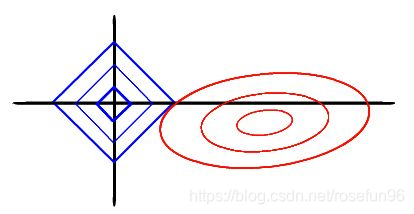
岭回归与Lasso回归异同
相同:
都可以用来解决标准线性回归的过拟合问题。
不同:
lasso 可以用来做特征选择,而 ridge 不行。或者说,lasso 更容易使得权重变为 0,而 ridge 更容易使得权重接近 0。
从贝叶斯角度看,lasso(L1 正则)等价于参数 w 的先验概率分布满足拉普拉斯分布,而 ridge(L2 正则)等价于参数 w 的先验概率分布满足高斯分布。
5. 主成分回归PCR
主成分回归分为两步,1是测定主成分数,幷由主成分分析(PCA)将矩阵X降维;2是降维的X矩阵再进行线性回归分析。
主成分是指,有原向量线性组合成的一个新向量,它用来表征原来变量时所产生的平方误差最小。
运用主成分分析,原变量矩阵 X 可表达成得分(即主成分)矩阵T,T由X在本征矢量 P 上的投影所得。
T = X P T = XP T=XP
多元线性回归应用了由 X 的列定义的全部空间,而主成分回归所占用的是一子空间。
T
=
X
P
Y
=
T
B
+
E
\begin{array}{c} T = XP\\ {Y=T B+E} \\ \end{array}
T=XPY=TB+E
其中,解:
B
=
(
T
′
T
)
−
1
T
′
Y
{B=\left(T^{\prime} T\right)^{-1} T^{\prime} Y}
B=(T′T)−1T′Y
主成分分析可以解决共线问题,去掉不太重要的主成分,减少随机误差产生的影响。
6. 偏最小二乘回归PLS
英文名:parital least squares.
PLS应用广泛的原因有:
-1. 模型的预报残差平方和较小。与线性回归,主成分回归等相比,具有较高的预报稳定性。
-2. PLS方法适合用于处理变量多而样本数又少的问题,高效地抽取信息。
原理:
输入矩阵 X, 目标矩阵Y,普通最小二乘法建立以下线性模型:
Y
=
X
B
+
E
Y = XB + E
Y=XB+E
其中,B为回归系数矩阵,E为残差矩阵,并且:
B
=
(
X
T
X
)
−
1
X
T
Y
B = (X^T X)^{-1} X^T Y
B=(XTX)−1XTY
- PLS 方法首先将矩阵 X 作双线性分解,即,
X = T P + E ( 1 ) X = TP + E \quad(1) X=TP+E(1)
其中,矩阵 T 含有两两正交的隐变量或得分矢量 t . - PLS 方法与主成分分析法不相同之处在于,主成分分析法要求分解后得到 t 的隐变量的方差最大。 PLS方法,需要用到矩阵 Y的信息,矩阵Y 也作双线性分解,即
Y = U Q + F ( 2 ) Y = UQ + F \quad(2) Y=UQ+F(2)
其中,U矩阵包涵 Y 的隐变量 u,即 u 为矩阵Y中变量的线性组合, F 为残差阵。
- PLS要求X分解得到的隐变量t与Y分解得到的隐变量u为最大重叠或相关性最大,因此,
u = v t + e . u = vt + e. u=vt+e.
其中,e 为残差矢量,系数根据最小二乘确定。
求解:
求解方法一:
(1)将 X 标准化并记为
E
0
=
(
E
01
,
E
02
,
…
,
E
0
P
)
n
×
p
E_{0}=\left(E_{01}, E_{02}, \ldots, E_{0 P}\right)_{n \times p}
E0=(E01,E02,…,E0P)n×p,Y 标准化并记为
F
0
=
(
F
01
,
F
02
,
…
,
F
0
q
)
n
×
q
F_{0}=\left(F_{01}, F_{02}, \ldots, F_{0 q}\right)_{n \times q}
F0=(F01,F02,…,F0q)n×q
(2)记
t
1
t_1
t1 是
E
0
E_0
E0 的第一个成分,
t
1
=
E
0
w
1
t_1 = E_0 w_1
t1=E0w1,
w
1
w_1
w1是
E
0
E_0
E0的第一个轴,它是一个单位向量,即
∣
∣
w
1
∣
∣
=
1
||w_1|| = 1
∣∣w1∣∣=1.
(3)为了
t
1
t_1
t1,
u
1
u_1
u1能分别代表 X, Y中的变异信息,以及要求
t
1
t_1
t1 对
u
1
u_1
u1 有最大的解释能力,即
t
1
t_1
t1,
u
1
u_1
u1的相关度达到最大值,即
m
a
x
v
a
r
(
t
1
)
m
a
x
v
a
r
(
u
1
)
m
a
x
r
(
t
1
,
u
1
)
max \; var(t_1)\\ max \; var(u_1) \\ max \; r(t_1, u_1)
maxvar(t1)maxvar(u1)maxr(t1,u1)
综合起来,就是协方差最大,
m
a
x
C
o
v
(
t
1
,
u
1
)
=
v
a
r
(
t
1
)
v
a
r
(
u
1
)
r
(
t
1
,
u
1
)
max \;\; Cov(t_1, u_1) = \sqrt{var(t_1)}\sqrt{var(u_1)}r(t_1, u_1)
maxCov(t1,u1)=var(t1)var(u1)r(t1,u1)
正规的表达式:
max < E 0 w 1 , F 0 c 1 > s.t { w 1 T w 1 = 1 c 1 T c 1 = 1 } \begin{array}{l} {\max <E_{0} w_{1}, F_{0} c_{1}>} \\ {\text {s.t}\left\{\begin{array}{l} {w_{1}^{T} w_{1}=1} \\ {c_{1}^{T} c_{1}=1} \end{array}\right\}} \end{array} max<E0w1,F0c1>s.t{w1Tw1=1c1Tc1=1}
在
∥
w
1
∥
2
=
1
\left\|w_{1}\right\|^{2}=1
∥w1∥2=1 和
∥
c
1
∥
2
=
1
\left\|c_{1}\right\|^{2}=1
∥c1∥2=1 的约束条件下,求
w
1
T
E
0
T
F
0
c
1
w_{1}^{T} E_{0}^{T} F_{0} c_{1}
w1TE0TF0c1 最大值。
采用拉格朗日算法,记
s = w 1 T E 0 T F 0 c 1 − λ 1 ( w 1 T w 1 − 1 ) − λ 2 ( c 1 T c 1 − 1 ) s=w_{1}^{T} E_{0}^{T} F_{0} c_{1}-\lambda_{1}\left(w_{1}^{T} w_{1}-1\right)-\lambda_{2}\left(c_{1}^{T} c_{1}-1\right) s=w1TE0TF0c1−λ1(w1Tw1−1)−λ2(c1Tc1−1)
求偏导,有
∂
s
∂
w
1
=
E
o
T
F
o
c
1
−
2
λ
1
w
1
=
0
∂
s
∂
c
1
=
F
0
T
E
0
w
1
−
2
λ
2
c
1
=
0
∂
s
∂
λ
1
=
−
(
w
1
T
w
1
−
1
)
=
0
∂
s
∂
λ
2
=
−
(
c
1
T
c
1
−
1
)
=
0
\begin{aligned} &\frac{\partial s}{\partial w_{1}}=E_{\mathrm{o}}^{T} F_{\mathrm{o}} c_{1}-2 \lambda_{1} w_{1}=0\\ &\frac{\partial s}{\partial c_{1}}=F_{0}^{T} E_{0} w_{1}-2 \lambda_{2} c_{1}=0\\ &\frac{\partial s}{\partial \lambda_{1}}=-\left(w_{1}^{T} w_{1}-1\right)=0\\ &\frac{\partial s}{\partial \lambda_{2}}=-\left(c_{1}^{T} c_{1}-1\right)=0 \end{aligned}
∂w1∂s=EoTFoc1−2λ1w1=0∂c1∂s=F0TE0w1−2λ2c1=0∂λ1∂s=−(w1Tw1−1)=0∂λ2∂s=−(c1Tc1−1)=0
推出, 2 λ 1 = 2 λ 2 = w 1 T E 0 T F 0 c 1 = c 1 T F 0 T E 0 w 1 = < E 0 w 1 , F 0 c 1 > \begin{aligned} &2 \lambda_{1}=2 \lambda_{2}=w_{1}^{T} E_{0}^{T} F_{0} c_{1}=c_{1}^{T} F_{0}^{T} E_{0} w_{1}=<E_{0} w_{1}, F_{0} c_{1}>\\ \end{aligned} 2λ1=2λ2=w1TE0TF0c1=c1TF0TE0w1=<E0w1,F0c1>
记
θ
1
=
2
λ
1
\theta_{1}=2 \lambda_{1}
θ1=2λ1,
则,
θ
1
\theta_1
θ1是优化问题的目标函数值。
并且有:
E
0
T
F
0
F
0
T
E
0
w
1
=
θ
1
2
w
1
F
0
T
E
0
E
0
T
F
0
c
1
=
θ
1
2
c
1
E_{0}^{T} F_{0} F_{0}^{T} E_{0} w_{1}=\theta_{1}^{2} w_{1}\\ F_{0}^{T} E_{0} E_{0}^{T} F_{0} c_{1}=\theta_{1}^{2} c_{1}
E0TF0F0TE0w1=θ12w1F0TE0E0TF0c1=θ12c1
可见,
w
1
w_1
w1 是矩阵
E
0
T
F
0
F
0
T
E
0
E_{0}^{T} F_{0} F_{0}^{T} E_{0}
E0TF0F0TE0 的特征向量,对应的特征值为
θ
1
2
\theta_1^{2}
θ12.
θ
1
2
\theta_1^{2}
θ12是目标函数值,要求取最大值,所以,
w
1
w_1
w1 是对应
E
0
T
F
0
F
0
T
E
0
E_{0}^{T} F_{0} F_{0}^{T} E_{0}
E0TF0F0TE0矩阵最大特征值
θ
1
2
\theta_1^{2}
θ12的单位特征向量。
同理,
c
1
c_1
c1 是对应
F
0
T
E
0
E
0
T
F
0
F_{0}^{T} E_{0} E_{0}^{T} F_{0}
F0TE0E0TF0矩阵最大特征值
θ
1
2
\theta_1^{2}
θ12的单位特征向量。
(4)求取
w
1
w_1
w1,
c
1
c_1
c1 ,得到成分,
t
1
=
E
0
w
1
u
1
=
F
0
c
1
\begin{aligned} &t_{1}=E_{0} w_{1}\\ &u_{1}=F_{0} c_{1} \end{aligned}
t1=E0w1u1=F0c1
(5)分别求
E
0
,
F
0
E_0, F_0
E0,F0对
t
1
,
u
1
t_1,u_1
t1,u1的3个回归方程。
E
o
=
t
1
p
1
T
+
E
1
F
0
=
u
1
q
1
T
+
F
1
∗
F
o
=
t
1
r
1
T
+
F
1
\begin{aligned} &E_{\mathrm{o}}=t_{1} p_{1}^{T}+E_{1}\\ &F_{0}=u_{1} q_{1}^{T}+F_{1}^{*}\\ &F_{\mathrm{o}}=t_{1} r_{1}^{T}+F_{1} \end{aligned}
Eo=t1p1T+E1F0=u1q1T+F1∗Fo=t1r1T+F1
其中,回归系数向量是,
p
1
=
E
0
T
t
1
∥
t
1
∥
2
q
1
=
F
0
T
u
1
∥
u
1
∥
2
r
1
=
F
0
T
t
1
∥
t
1
∥
2
\begin{aligned} &p_{1}=\frac{E_{0}^{T} t_{1}}{\left\|t_{1}\right\|^{2}}\\ &q_{1}=\frac{F_{0}^{T} u_{1}}{\left\|u_{1}\right\|^{2}}\\ &r_{1}=\frac{F_{0}^{T} t_{1}}{\left\|t_{1}\right\|^{2}} \end{aligned}
p1=∥t1∥2E0Tt1q1=∥u1∥2F0Tu1r1=∥t1∥2F0Tt1
其中,
E
1
F
1
∗
F
1
E_{1} \quad F_{1}^{*} \quad F_{1}
E1F1∗F1是3个回归方程的残差矩阵。
(6)用残差矩阵 E 1 , F 1 E_1,F_1 E1,F1取代 E 0 , F 0 E_0, F_0 E0,F0,然后求第2个轴 w 2 , c 2 w_2,c_2 w2,c2以及第2个成分 t 2 , u 2 t_2, u_2 t2,u2。
t 2 = E 1 w 2 u 2 = F 1 c 2 θ 2 = < t 2 , u 2 > = w 2 T E 1 T F 1 c 2 \begin{aligned} &t_{2}=E_{1} w_{2}\\ &u_{2}=F_{1} c_{2}\\ &\theta_{2}=<t_{2}, u_{2}>=w_{2}^{T} E_{1}^{T} F_{1} c_{2} \end{aligned} t2=E1w2u2=F1c2θ2=<t2,u2>=w2TE1TF1c2
不断计算下去。
(7)如果 X 的秩是A,则有:
E
0
=
t
1
p
1
T
+
t
2
p
2
T
+
…
+
t
A
p
A
T
F
0
=
t
1
r
1
T
+
t
2
r
2
T
+
…
+
t
A
r
A
T
+
F
A
\begin{aligned} &E_{0}=t_{1} p_{1}^{T}+t_{2} p_{2}^{T}+\ldots+t_{A} p_{A}^{T}\\ &F_{0}=t_{1} r_{1}^{T}+t_{2} r_{2}^{T}+\ldots+t_{A} r_{A}^{T}+F_{A} \end{aligned}
E0=t1p1T+t2p2T+…+tApATF0=t1r1T+t2r2T+…+tArAT+FA
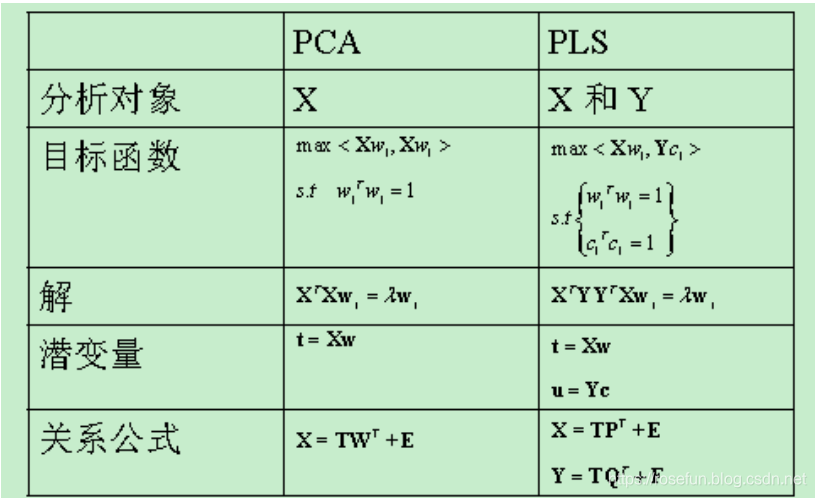
PLS 和PCA的比较:
最近开通了个公众号,主要分享机器学习相关内容,推荐系统,风控等算法相关的内容,感兴趣的伙伴可以关注下。

公众号相关的学习资料会上传到QQ群596506387,欢迎关注。
参考:


















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











