







前言:一直都是使用日志进行记录运行信息,保存的格式也是.txt的,最近有个项目需要保存一些数据到电脑中,保存格式是.txt格式的,顺手记录下。
一、代码
public void txtWrite(string filepath, string str)
{
try
{
if(!File.Exists(filepath))
{
//创建文件
try
{
FileStream fs = File.Create(filepath);//创建文件
fs.Close();
}
catch (Exception e)
{
}
}
if (File.Exists(filepath))
{
FileStream stream = new FileStream(filepath, FileMode.Append, FileAccess.Write);
StreamWriter writer = new StreamWriter(stream);
writer.WriteLine(str);
writer.Flush();
writer.Close();
stream.Close();
}
}
catch (Exception exception)
{
string text = exception.ToString();
if (exception.InnerException != null)
{
text = text + exception.InnerException.ToString();
}
if (exception.StackTrace != null)
{
text = text + exception.StackTrace.ToString();
}
}
}调用
string s = "123456789";
tXTHelper.txtWrite(path,s);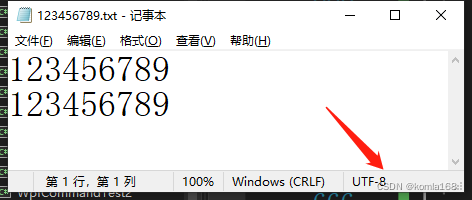
注意下这里的编码格式,用System.IO.StreamReader读取包含汉字的txt文件时,经常会读出乱码(StreamWriater写文本文件也有类似的问题),原因很简单,就是文件的编码(encoding)和StreamReader/Writer的encoding不对应。
上面代码中笔者没有设置或者说使用了默认的编码格式进行保存,下面我们改变下编码格式
二、编码格式
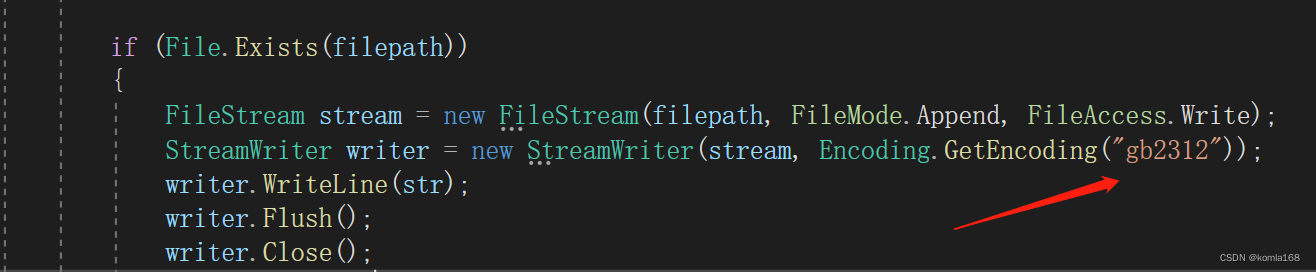
2.1 gb2312
2.2、utf-8


2.3 Encoding.UTF8
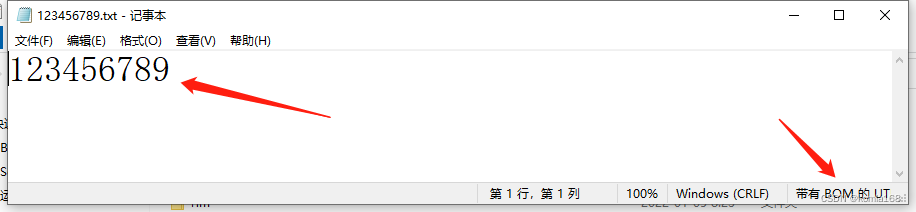
文本编辑器(比如XP自带的记事本)在生成文本文件时,如果编码格式和系统默认的编码(中文系统下默认为GB2312)不一致时,会在txt文件开头部分添加特定的“编码字节序标识(Encoding Bit Order Madk,简写为BOM)”,类似PE格式的"MZ"文件头。这样它在读取时就可以根据这个BOM来确定该文本文件生成时所使用的Encoding。这个BOM我们用记事本等程序打开默认是看不到的,但是用stream按字节读取时是可以读到的。
下面是System.Text.Encoding源码中介绍
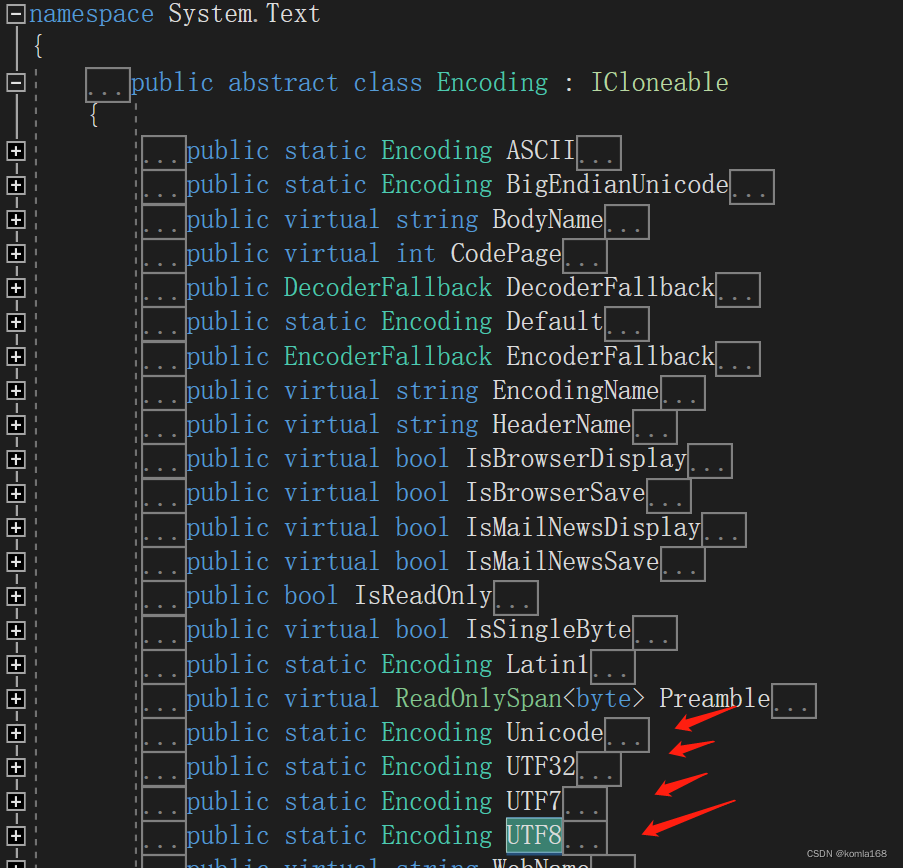
2.4 说明
utf-8、utf-16(都属于Unicode,其中window系统下utf-16等效于Unicode)、gb2312(简体中文)。。。这些都是各地区的编码格式,具体参考这篇文章
Encoding 类 (System.Text) | Microsoft Docs
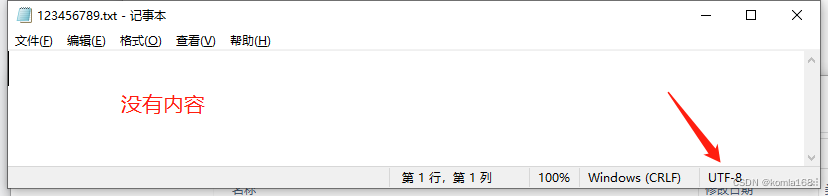
为什么Encoding.GetEncoding("GB2312")生成不了数据?
查阅资料发现是目标框架的原因,笔者测试框架是.NET5,后来在.NETFramework平台下测试,写进了数据,这可能是.NET为了跨平台没有默认设置框架的编码格式吧。
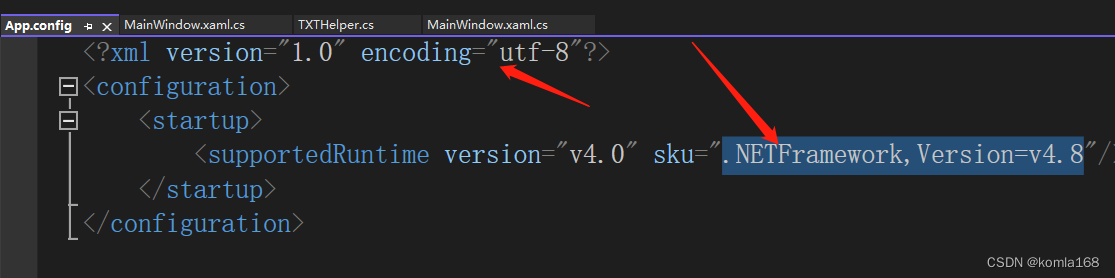
三、引用文章
为什么在C#中用GetEncoding无法获取gb2312等中文编码? - C# - ExcelOffice【微信公众号:水星Excel】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









