







链接:https://arxiv.org/pdf/2010.13154.pdf
github:https://speechbrain.github.io/
摘要
RNN在seq2seq上有很好的表现,但是不能够并行计算,使得计算的代价比较大;而Transformers的出现解决了RNN的这个问题,而Transformers由于attention的缘故,会有比较高的复杂性。后续出现了Transformers的各种变体,后续专门来写。
这篇文章提出了SepFormer,,一种利用Transformers来实现语音分离的方法,在WSJ0-2/3mix数据上实现了SOTA;而且由于Transformers的并行性,SepFormer是更快并且占内存比较小的。
背景
DPRNN是将较长的序列切割成较小的块,在块内和块间进行操作。但是RNN的局限,使得DPRNN也遇到了之前的问题;之后DPTNet整合了Transformers,但是DPTNet仍然嵌入了RNN。
本文的SepFormer,主要有多头attention和前向层组成,并采纳了DPRNN的双路径的框架,将其中的RNN用多尺度Transformers替换,用来学习长短依赖性。
模型框架

其中,encoder学习输入信号的表示,mask用来估计最优的masks来分离语音信号,decoder重构source.
1. masking network

masking network(图1上)得到encoder的输出h ,估计混合语言中N个讲话者的mask .
encoder的输出 h 会经过层正则和线性层,然后对此进行切块得到 ,其中会有参数每一个块的大小
以及块的个数
, 被feed到SepFormer block中得到输出
,然后经过PReLU的线性层得到输出
,然后使用overlap-add得到
,最后经过FFW和ReLU得到每一个讲话者的掩码
。
SepFormer block
图1的中部是详细的信息,SepFormer block利用DPRNNs去构建长短依赖,IntraTransformer(IntraT)构建了短依赖,InterTransformer(InterT)构建了长依赖;IntraT独立处理 的每一个块,从而构建了短依赖,InterT对IntraT的输出进行维度变换,并构建块之间的转移,从而构建了块之间的长依赖,整个过程的变换方式:
![]()
Intra and Inter Transformers
图1的底部是IntraT和InterT的transformers的结构。
Decoder
主要使用装置卷积层,和encoder的步长和核尺寸一致。source的 和encoder的h进行元素对应相乘:
![]()
Experiment
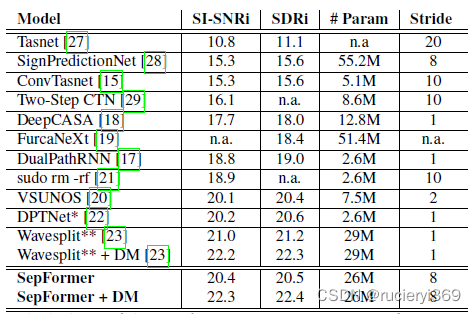
WSJ0-2mix的结果
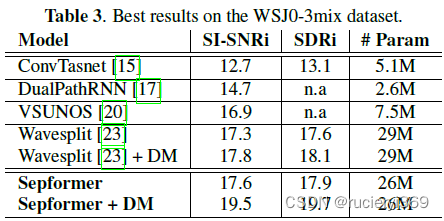
WSJ0-3mix的结果
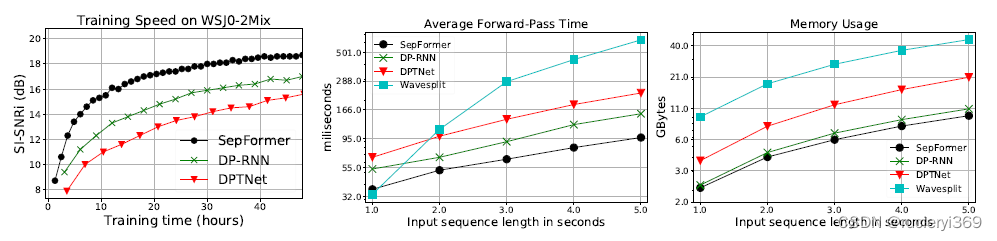
Speed and Memory Comparison
Conclusion
文章提出了一种新的语音分离神经模型SepFormer,是一种无RNN的架构,使用masking network来学习长短依赖。















 772
772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









