






因为要用到神经网络算法,之前接触过一些机器学习的皮毛还是半知半解,先着手练习一些比较好理解的小项目吧,新手上路见笑了。开始:
回归模型(keras)
一元二次模型
先放模型:
y
=
x
2
+
1
y=x^2+1
y=x2+1
样本训练数据随机模拟就好了。引入tf库中的keras模块,程序小,所以要用到的函数我就直接单独加载了:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.initializers import Ones
import matplotlib.pyplot as plt
接下来生成200组数据样本,加入随机噪声,其中前160组作为训练样本,后40组用于测试评估网络
X = np.linspace(-10, 10, 200)
np.random.shuffle(X) # randomize the data
Y = X * X + 1 + np.random.normal(0, 0.05, (200, ))
X_train, Y_train = X[:160], Y[:160] # train 前 160 data points
X_test, Y_test = X[160:], Y[160:] # test 后 40 data points
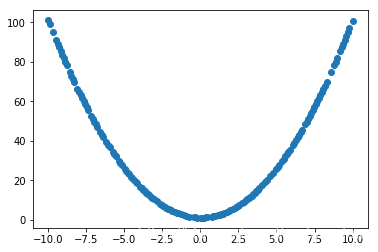
画出训练集
plt.scatter(X_train, Y_train)
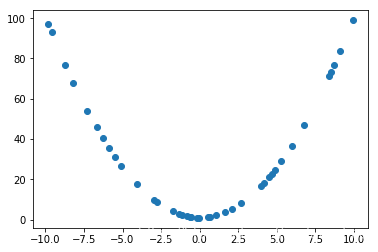
以及测试集
plt.scatter(X_test, Y_test)
接下来建立网络层。从这个部分开始,就要一点一点尝试设置参数了,以下参数的调整对结果均有影响(不调整有可能也有影响orz…)
# 建立神经网络
model = Sequential()
model.add(Dense(units=10, input_dim=1, activation='relu'))
model.add(Dense(units=10, activation='relu'))
model.add(Dense(units=1, activation='relu'))
先解释一下这个代码块的含义,Sequential()函数keras模块中的堆叠模型(简单理解就是网络层直接一层一层的叠加 )
add函数给这个模型增加Dense层,Dense即全连接层,存放每个权重的通道,这几行函数其实构建了如下这样一个网络:
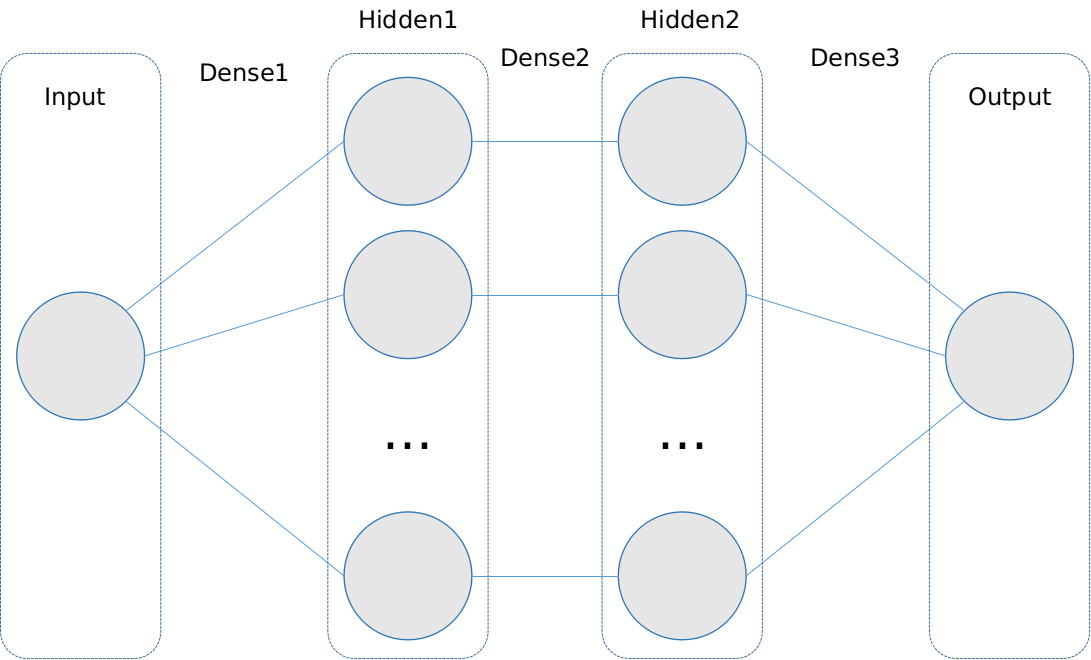 一元变量X对应输入层是一维的,这时Dense1必须要告知输入维度
一元变量X对应输入层是一维的,这时Dense1必须要告知输入维度Input_dim = 1,后面的连接层的input_dim参数就没必要写了,可以推算出来。每个dense层还要给出units个数,表示下个层的单元节个数,这里两个隐藏层节点数分别都为10个。这样一来,每一层的节点数就很清楚了。激活函数选择了"relu"。
接下来配置学习过程,损失函数选择均方根对数误差,优化器是SGD(随机梯度下降)参数lr是学习率,评估标准为精度值:
# 选择损失函数和优化器
model.compile(loss='mean_squared_logarithmic_error', optimizer=SGD(lr=0.01),metrics=["accuracy"])
开始训练,fit函数参数设置:epoch为训练次数,verbose=0表示我不想看到训练中输出的每个epoch,batch_size默认为32,我没有设置,validation_data放上测试集
# 训练
print('Training ----------')
history = model.fit(X_train, Y_train, epochs=50, verbose=0, validation_data=(X_test, Y_test))
这一部分是可视化的部分,精度值:
# 绘制训练 & 验证的准确率值
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
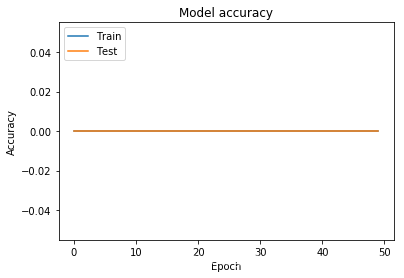
(好像出现了点问题,待解决。。)
损失函数:
# 绘制训练 & 验证的损失值
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
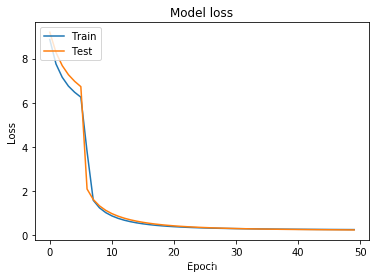
(有时候这个loss函数也会居高不下)
# 评估
loss_and_metrics = model.evaluate(X_test, Y_test)
loss_and_metrics
[0.22141730785369873, 0.0]
(误差很大,精度一直是0)
再做一个数据集预测一下
# 预测
X_pre = np.linspace(-10, 10, 200)
Y_pre = X_pre * X_pre + 1
classes = model.predict(X_pre, batch_size=7)
plt.scatter(X_pre, Y_pre)
plt.scatter(X_pre, classes)
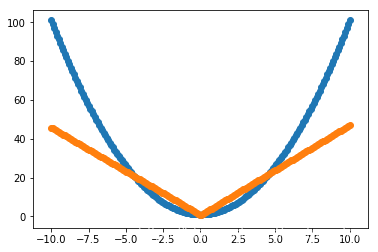
(看得出来误差很大。。)
调整与改进
阶段1——修改epochs
epochs = 500 试一下
history = model.fit(X_train, Y_train, epochs=500, verbose=0, validation_data=(X_test, Y_test))
loss:

预测:
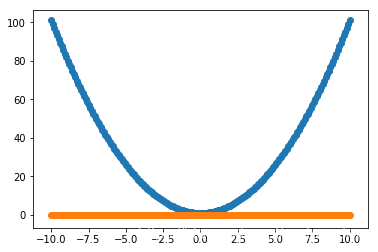
(???!@#¥%……&# )
重新跑一下。。。
loss:
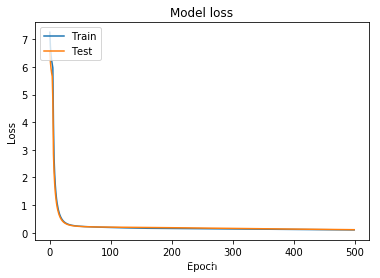
预测:

参数没调整的情况下也会出现全为0的问题,是否梯度下降过程中卡在局部极小点?
阶段2——修改学习率
前面的成图发现拟合的函数有了大概的雏形了,但最终曲线没有弯曲成想要的弧度。学习样本不足,步伐太慢,网络太小,都有可能。先调整一下学习率,令lr = 0.1
loss:
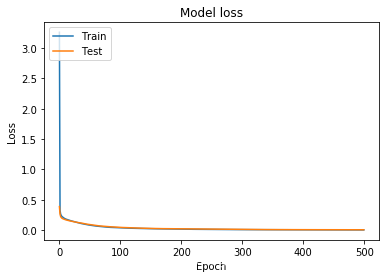
预测:
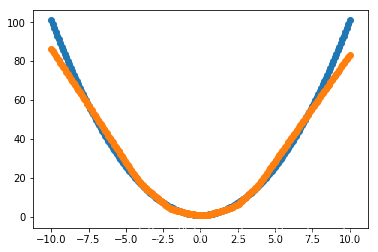
可以看到,loss函数收敛更快了,曲线拟合效果变好了。
令 lr = 0.2
loss:
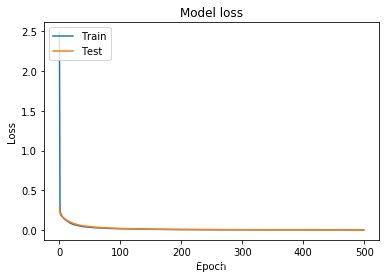
预测:

比刚刚的效果要好。
令 lr = 0.3
loss:
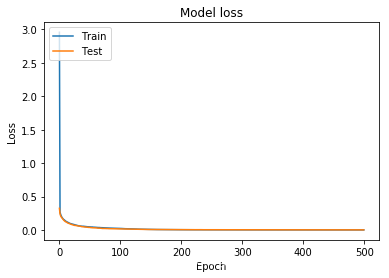
预测:
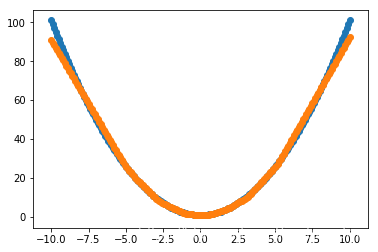
这次变化不是很大了,我想我应该找出一个让它效果变差的界限。
当我把学习率加到1时,
loss:
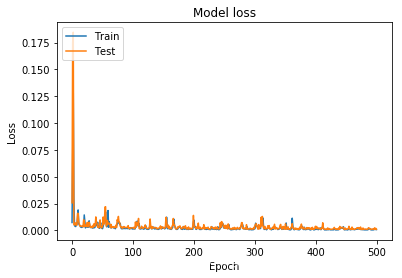
预测:
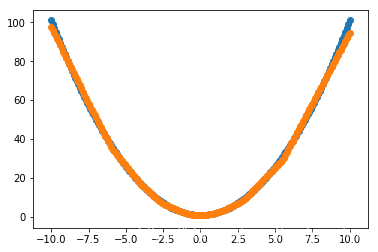
loss函数收敛的不那么平滑,但拟合结果更好了。
至于精度值一直为0的问题,有待解决,再去研究一下。
- 函数拟合
- 精度值的问题
------------------------------------------更新 2019/09/05------------------------------------------
回归模型不需要用到accuracy评估,accuracy是评估分类问题的,把那部分的代码和可视化去掉就行。
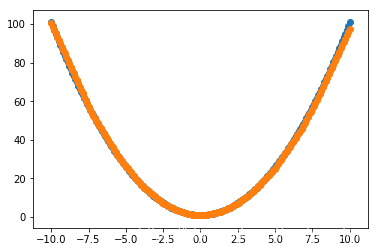
尝试了一下把优化器SGD改成了Adam,效果很明显:
# 选择损失函数和优化器
model.compile(loss='mean_squared_logarithmic_error', optimizer=Adam(lr=0.1))
loss:
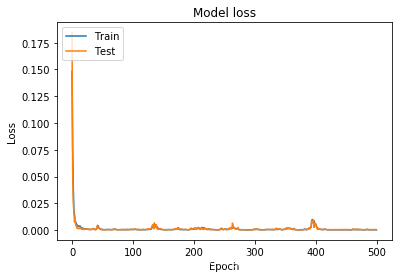
预测:














 9017
9017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









