






目录
1. 模型简介
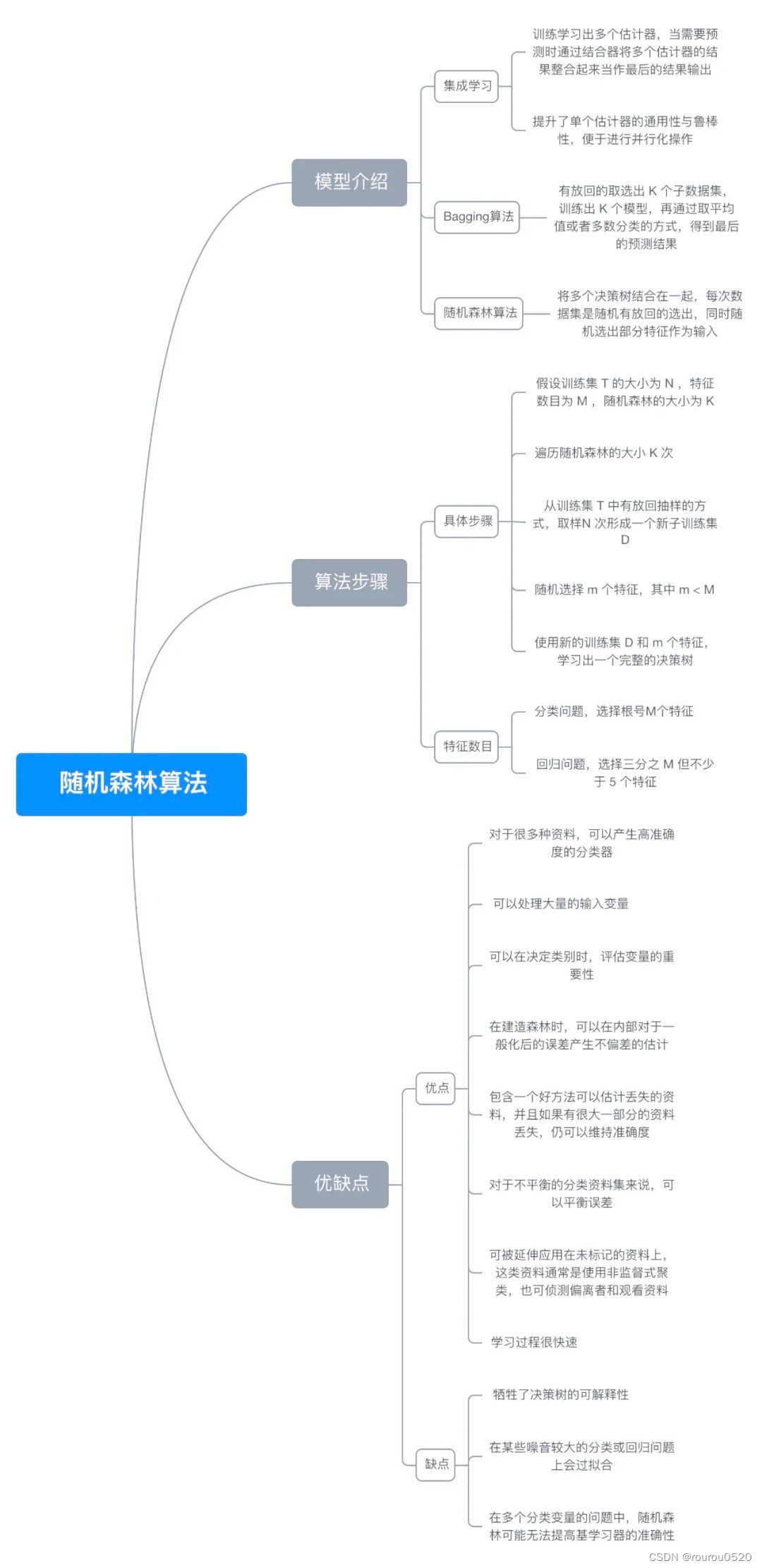
2. 随机森林回归算法
2.1 数据导入与读取
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# 划分测试训练集
from sklearn.ensemble import RandomForestRegressor # 随机森林模型导入
from sklearn import metrics # 评估性能函数
# 导入数据,路径中要么用\\或/或者在路径前加r
dataset = pd.read_excel('DataRFL.xlsx')
# 导入数据,路径中要么用\\或/或者在路径前加r
# dataset = pd.read_csv(r'D:\Documents\test_py\petrol_consumption.csv')
# 输出数据预览
print(dataset.head())
# 准备训练数据
# 自变量:汽油税、人均收入、高速公路、人口所占比例
# 因变量:汽油消耗量
X = dataset.iloc[:, 1:].values
y = dataset.iloc[:, 0].values
data_labels = dataset.columns[1:]
print(data_labels)
'''
# 读取数据
data = pd.read_excel('DataRFL.xlsx')
'''
# 将数据分为训练集和测试集 2\8比例
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2,
random_state=0)
2.2 回归模型的建立(函数参数说明)与评估
# 训练随机森林解决回归问题 训练模型
regressor = RandomForestRegressor(n_estimators=200, random_state=0)
regressor.fit(X_train, y_train)
'''
函数的具体参数
sklearn.ensemble.RandomForestRegressor(
n_estimators=100, *, # 树的棵树,默认是100
criterion='mse', # 默认“ mse”,衡量质量的功能,可选择“mae”。
max_depth=None, # 树的最大深度。
min_samples_split=2, # 拆分内部节点所需的最少样本数:
min_samples_leaf=1, # 在叶节点处需要的最小样本数。
min_weight_fraction_leaf=0.0, # 在所有叶节点处的权重总和中的最小加权分数。
max_features='auto', # 寻找最佳分割时要考虑的特征数量。
max_leaf_nodes=None, # 以最佳优先方式生长具有max_leaf_nodes的树。
min_impurity_decrease=0.0, # 如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂。
min_impurity_split=None, # 提前停止树木生长的阈值。
bootstrap=True, # 建立树木时是否使用bootstrap抽样。 如果为False,则将整个数据集用于构建每棵决策树。
oob_score=False, # 是否使用out-of-bag样本估算未过滤的数据的R2。
n_jobs=None, # 并行运行的Job数目。
random_state=None, # 控制构建树时样本的随机抽样
verbose=0, # 在拟合和预测时控制详细程度。
warm_start=False, # 设置为True时,重复使用上一个解决方案,否则,只需拟合一个全新的森林。
ccp_alpha=0.0,
max_samples=None) # 如果bootstrap为True,则从X抽取以训练每个决策树。
'''
# 输出目标方程(回归方程)
print("目标方程:")
for i, feature in enumerate(data_labels):
print("{} * {} +".format(regressor.feature_importances_[i], feature), end=' ')
# 预测结果
y_pred = regressor.predict(X_test)
# 评估回归性能 MAE/MSE/RMSE/R-SQ
print('回归性能指标:')
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:',
np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
from sklearn.metrics import mean_squared_error, r2_score
r2 = r2_score(y_test, y_pred)
print('R-squared:', r2)
2.3 特征重要性排序
##特征重要性排序
indices = np.argsort(regressor.feature_importances_)[::-1] # 取反后是从大到小
print("特征重要性排序:")
for i in range(X_train.shape[1]):
print("%2d) %-*s %f" % (i + 1, 30, data_labels[indices[i]], regressor.feature_importances_[indices[i]]))
# 绘制特征重要性条形图
import matplotlib.pyplot as plt
plt.title('Feature Importance')
plt.bar(range(X_train.shape[1]), regressor.feature_importances_[indices], align='center')
plt.xticks(range(X_train.shape[1]), data_labels[indices], rotation=90)
plt.xlim([-1, X_train.shape[1]])
plt.tight_layout()
plt.show()
3. 随机森林分类算法
3.1 数据准备
import pandas as pd
from sklearn import metrics
import numpy as np
import sklearn.ensemble as ensemble # ensemble learning: 集成学习
from sklearn.ensemble import RandomForestClassifier
df = pd.read_excel('regression.xlsx') # 宽带客户数据
# print(df.head()) # 输出数据预览
df.info()
# 首先将列名全部小写
df.rename(str.lower, axis='columns', inplace=True)
#现在查看因变量broadband分布情况,看是否存在不平衡
from collections import Counter
print('Broadband: ', Counter(df['broadband']))
## Broadband: Counter({0: 908, 1: 206}) 比较不平衡。
## 根据原理部分,可知随机森林是处理数据不平衡问题的利器
#变量的赋值划分
y = df['broadband']
X = df.iloc[:, 0:4]
future_labels = X.columns[0:]
print(future_labels)
# print(X)
#区分测试集与训练集
from sklearn.model_selection import train_test_split, GridSearchCV
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.4, random_state=12345)
3.2 特征重要性
#特征重要性
forest = RandomForestClassifier(n_estimators=200, random_state=1) # n_estimators:决策树个数-随机森林特有参数 #建立分类模型
forest.fit(X_train, y_train)
importances = forest.feature_importances_
print(len(importances))
importances
indices = np.argsort(importances)[::-1] # 取反后是从大到小
indices
'''
numpy.argsort(a, axis=-1, kind=’quicksort’, order=None) 功能:
将矩阵a在指定轴axis上排序,并返回排序后的下标
参数: a:输入矩阵, axis:需要排序的维度
返回值: 输出排序后的下标
'''
for i in range(X_train.shape[1]):
print("%2d) %-*s %f" % (i + 1, 30, future_labels[indices[i]], importances[indices[i]]))
注:随机森林分类函数说明:
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200
Criterion:string,可选(default =“gini”)分割特征的测量方法
max_depth:integer或None,可选(默认=无)树的最大深度 5,8,15,25,30
max_features="auto”,每个决策树的最大特征数量
If "auto", then max_features=sqrt(n_features).
If "sqrt", then max_features=sqrt(n_features)(same as "auto").
If "log2", then max_features=log2(n_features).
If None, then max_features=n_features.
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
min_samples_split:节点划分最少样本数
min_samples_leaf:叶子节点的最小样本数
超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf 需要网格搜索调优
因为分类模型具有超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
因此常常在此模型中采用网格搜索调优方法,下文中展示
3.3 使用网格搜索法边建立模型边优化—模型的预测与评估
# 随机森林建模一样是使用网格搜索,有关Python实现随机森林建模的详细参数解释可以看代码的注释
# # 直接使用交叉网格搜索来优化树模型,边训练边优化
# from sklearn.model_selection import GridSearchCV
# # 网格搜索的参数:正常决策树建模中的参数 - 评估指标,树的深度,
# ## 最小拆分的叶子样本数与树的深度
param_grid = {
'criterion': ['entropy', 'gini'],
'max_depth': [5, 6, 7, 8], # 深度:这里是森林中每棵决策树的深度
'n_estimators': [11, 13, 15], # 决策树个数-随机森林特有参数
'max_features': [0.3, 0.4, 0.5],
# 每棵决策树使用的变量占比-随机森林特有参数(结合原理)
'min_samples_split': [ 2, 3, 4, 5, 6, 8] # 叶子的最小拆分样本量
}
import sklearn.ensemble as ensemble # ensemble learning: 集成学习
rfc = ensemble.RandomForestClassifier()
rfc_cv = GridSearchCV(estimator=rfc, param_grid=param_grid,
scoring='roc_auc', cv=4)
# 传入模型,网格搜索的参数,评估指标,cv交叉验证的次数
# 这里也只是定义,还没有开始训练模型
#建立模型
rfc_cv.fit(X_train, y_train)
# 使用随机森林对测试集进行预测
test_est = rfc_cv.predict(X_test)
#模型的评估
print('随机森林精确度...')
print(metrics.classification_report(test_est, y_test))
print('随机森林 AUC...')
fpr_test, tpr_test, th_test = metrics.roc_curve(test_est, y_test)
# 构造 roc 曲线
print('AUC = %.4f' %metrics.auc(fpr_test, tpr_test))
best = rfc_cv.best_params_
print(best)
# 搜索最优的参数
# 重新构建
param_grid = {
'criterion': ['entropy', 'gini'],
'max_depth': [5, 6, 7, 8], # 深度:这里是森林中每棵决策树的深度
'n_estimators': [11, 13, 15], # 决策树个数-随机森林特有参数
'max_features': [0.1, 0.2, 0.3, 0.4, 0.5],
# 每棵决策树使用的变量占比-随机森林特有参数(结合原理)
'min_samples_split': [2, 3, 4, 5, 6, 8] # 叶子的最小拆分样本量
}
rfc_cv = GridSearchCV(estimator=rfc, param_grid=param_grid,
scoring='roc_auc', cv=4)
rfc_cv.fit(X_train, y_train)
# 使用随机森林对测试集进行预测
test_est = rfc_cv.predict(X_test)
print('随机森林精确度...')
print(metrics.classification_report(test_est, y_test))
print('随机森林 AUC...')
fpr_test, tpr_test, th_test = metrics.roc_curve(test_est, y_test)
# 构造 roc 曲线
print('AUC = %.4f' %metrics.auc(fpr_test, tpr_test))
参考文章: https://blog.csdn.net/sai_simon/article/details/123082619?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168223832916800192284131%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=168223832916800192284131&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-123082619-null-null.142v86wechat,239v2insert_chatgpt&utm_term=%E9%9A%8F%E6%9C%BA%E6%A3%AE%E6%9E%97&spm=1018.2226.3001.4187















 1865
1865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









