






特征工程基础流程说明
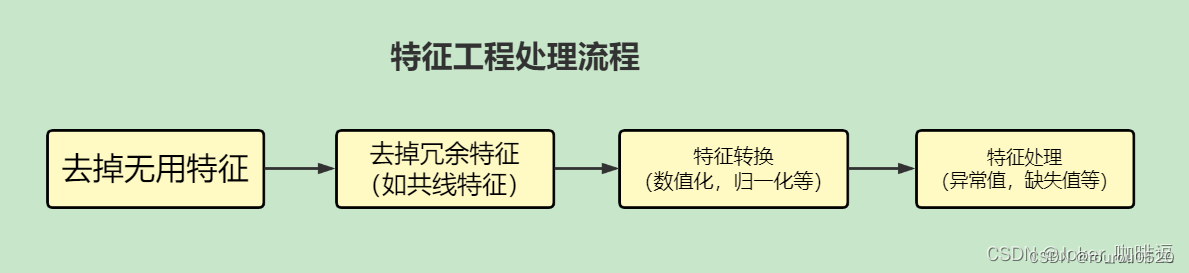
目的:对数据以及特征进行处理,发现对因变量具有明显影响作用的特征。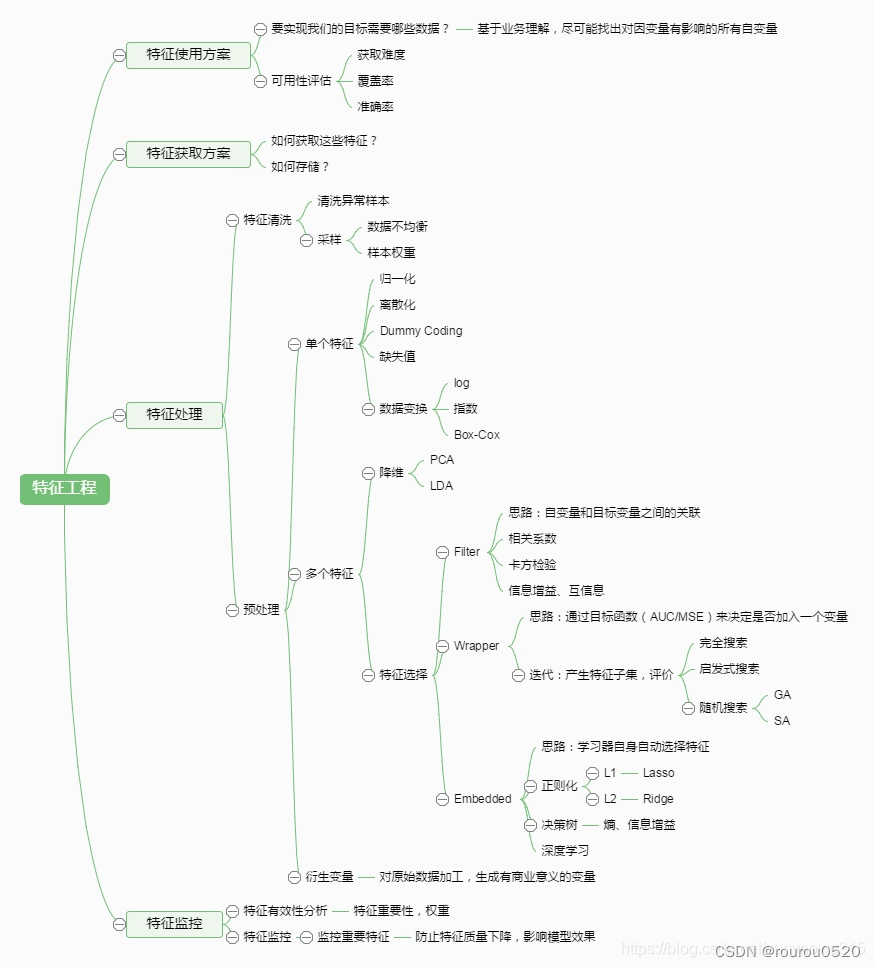
1、数据预处理
数据采集
采集数据前,不如先清楚哪些数据对最后的预测结果使用帮助的,是否可采集到,
在线上实时计算时数据获取是否快捷
数据清洗
除去“脏”的数据,例如,某些商品的刷单数据
数据采样
数据在采集、清洗过后、正负样本是不均匀的,故需进行数据采样
方法有:随机采样,分层采样
python预处理操作大全:
https://blog.csdn.net/overfit/article/details/79856417
1.1 缺失值处理
(1)缺失值删除(dropna)
# python缺失值查找: info函数 df:数据集名称
df.info()
# 使用dropna(0)函数删除所有含Nan空值的行
df.dropna()
(2)缺失值填充(dropna)
①用固定值填充
data['灰度分'] = data['灰度分'].fillna('-99')
②用均值填充
data['灰度分'] = data['灰度分'].fillna(data['灰度分'].mean()))
③用众数填充
data['灰度分'] = data['灰度分'].fillna(data['灰度分'].mode()))
④用插值法填充
data['灰度分'] = data['灰度分'].interpolate()
⑤用KNN进行填充
from fancyimpute import BiScaler, KNN, NuclearNormMinimization, SoftImpute
dataset = KNN(k=3).complete(dataset)
⑥random forest进行填充(一般不用)
from sklearn.ensemble import RandomForestRegressor
zero_columns_2 = ['机构查询数量', '直接联系人数量', '直接联系人在黑名单数量', '间接联系人在黑名单数量',
'引起黑名单的直接联系人数量', '引起黑名单的直接联系人占比']
#将出现空值的除了预测的列全部取出来,不用于训练
dataset_list2 = [x for x in dataset if x not in zero_columns_2]
dataset_2 = dataset[dataset_list2]
#取出灰度分不为空的全部样本进行训练
know = dataset_2[dataset_2['灰度分'].notnull()]
print(know.shape) #26417, 54
# 取出灰度分为空的样本用于填充空值
unknow = dataset_2[dataset_2['灰度分'].isnull()]
print(unknow.shape) #2078, 54
y = ['灰度分']
x = [1]
know_x2 = know.copy()
know_y2 = know.copy()
print(know_y2.shape)
#
know_x2.drop(know_x2.columns[x], axis=1, inplace=True)
print(know_y2.shape)
print(know_x2.shape)
#
know_y2 = know[y]
# RandomForestRegressor
rfr = RandomForestRegressor(random_state=666, n_estimators=2000, n_jobs=-1)
rfr.fit(know_x2, know_y2)
# 填充为空的样本
unknow_x2 = unknow.copy()
unknow_x2.drop(unknow_x2.columns[x], axis=1, inplace=True)
print(unknow_x2.shape) #(2078, 53)
unknow_y2 = rfr.predict(unknow_x2)
unknow_y2 = pd.DataFrame(unknow_y2, columns=['灰度分'])
⑦缺失值作为数据的一部分不填充
LightGBM和XGBoost都能将NaN作为数据的一部分进行学习,所以不需要处理缺失值。
1.2 异常值处理
1)特征异常平滑
2)重复值处理
3)数据格式处理
4)数据采样
1.3 数据无量纲化处理
特征的规格不一样,不能够放在一起比较。无量纲化可以解决这一问题。
(1)标准化
·标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布,即均值为0,标准差为1,其转化函数为:

应用场景:
在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score
standardization表现更好。
from sklearn.preprocessing import StandardScaler
#标准化,返回值为标准化后的数据
StandardScaler().fit_transform(iris.data)
(2)最大最小值归一化(区间缩放法)
区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。

本归一化方法比较适用在数值比较集中的情况;
应用场景:
在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法(不包括Z-score方法)。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围
from sklearn.preprocessing import MinMaxScaler
#区间缩放,返回值为缩放到[0, 1]区间的数据
MinMaxScaler().fit_transform(iris.data)
(3)L2范数归一化方法
依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”
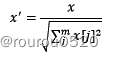
from sklearn.preprocessing import Normalizer
#归一化,返回值为归一化后的数据
Normalizer().fit_transform(iris.data)
(4)二值化(定量特征)
特征的二值化处理是将数值型数据输出为布尔类型。其核心在于设定一个阈值,当样本数据大于该阈值时,输出为1,小于等于该阈值时输出为0。
from sklearn.preprocessing import Binarizer
#二值化,阈值设置为3,返回值为二值化后的数据
Binarizer(threshold=3).fit_transform(iris.data)
(5)时间序列处理
时间戳
2、特征选择
2.1 线性降维
(1)主成分分析法(PCA)另一篇
通过某种线性投影,将高维的数据映射到低维的空间中,并期望方差最大,从而达到使用
较小的数据维度保留较多的原始数据点特征的效果。(无监督的线性降维算法)
(2)线性判别分析法(LDA)另一篇
使降维后的数据点尽可能地容易被区分(有监督的线性降维算法)
2.2 特征选择
方法:
1、判断特征是否发散(方差):
如果一个特征不发散,就是说这个特征大家都有或者非常相似,说明这个特征不需要。
2、判断特征和目标是否相关(相关性):
· 与目标的相关性越高,越应该优先选择;
· 利用特征之间的依赖关系, 来表示特征的冗余性加以去除。
3、按照特征评价标准分类:
选择使分类器的错误概率最小的特征或者特征组合。
4、利用距离来度量样本之间相似度。
特征选择思路图
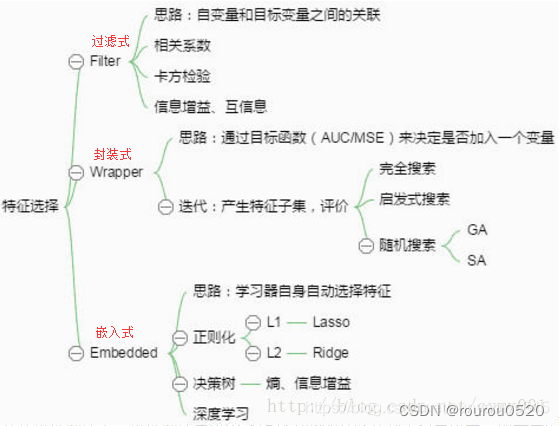
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
2.2.1 过滤法
相关度较大的特征或者特征子集会在分类器上获得较高的准确率。过滤式特征选择的评价标准分为四种,即距离度量、信息度量、关联度度量以及一致性度量。
(1)方差选择法
方差越小,说明变化小,提供的信息量小,选择删除,一般选取阈值为0
#查看方差
data.std().sort_values()
#去掉变化小的特征 比如一个特征如果全是1或者0 那么这数据是没有意义的
from sklearn.feature_selection import VarianceThreshold
#方差选择法,返回值为特征选择后的数据
#参数threshold为方差的阈值
VarianceThreshold(threshold=3).fit_transform(iris.data) #data不包含目标值
#输出的是该列的数据
(2)相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。用feature_selection库的SelectKBest类结合相关系数来选择特征的代码如下:
也可以计算特征间的相关性
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
#计算特征之间的相关系数做筛选
import matplotlib.pyplot as plt
data1 = pd.Series(np.random.rand(100)*100).sort_values()
data2 = pd.Series(np.random.rand(100)*50).sort_values()
data = pd.DataFrame({'value1':data1.values,
'value2':data2.values})
print(data.head())
print('------')
# 创建样本数据
corr = data.corr('pearson') # .corr('spearman')
#corr得到特征与特征之间的相关性 然后corr['target']就是目标特征与所有特征之间的相关性
#利用corr方法得出特征的pearson或spearman系数值
import seaborn as sns
# 用热力图看一下互相之间的关系
ax = plt.subplots(figsize=(10, 10))#设置大小
sns.heatmap(corr, annot=True)# annot表示是否在方块上出现数字
之间快速筛选
```python
#寻找K个最相关的特征信息
k = 14 # number of variables for heatmap
cols = train_corr.nlargest(k, 'target')['target'].index
hm = plt.subplots(figsize=(10, 10))#调整画布大小
hm = sns.heatmap(train_data[cols].corr(),annot=True,square=True)
plt.show()
# Threshold for removing correlated variables
threshold = 0.5
# Absolute value correlation matrix
corr_matrix = data_train1.corr().abs()
drop_col=corr_matrix[corr_matrix["target"]<threshold].index
#快速的删除一些不重要的特征
data_all.drop(drop_col, axis=1, inplace=True)
(3)卡方检验
统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,卡方值越大,越不符合;卡方值越小,偏差越小,越趋于符合。
自变量对因变量的相关性
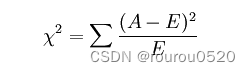

from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#选择K个最好的特征,返回选择特征后的数据
model = SelectKBest(chi2, k=2)
model.fit_transform(idata.data, idata.target)
model.get_support(True)
2.2.2 封装法

(1)递归消除法(常用)
递归特征前提是选择一种模型,例如SVM或者逻辑回归,然后选择一定数目的特征,进行模型评估。接下来对审改的特征重复上述动作,直到所有特征都遍历。最后,选择出模型效果最好的特征。
递归特征消除法属于一种贪心算法
#排序代码:Sklearn提供了RFE包,可以用于特征消除,还提供了RFECV,可以通过交叉验证来对的特征进行排序。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
boston = load_boston()
X = boston["data"]
Y = boston["target"]
names = boston["feature_names"]
#use linear regression as the model
lr = LinearRegression()
#rank all features, i.e continue the elimination until the last one
rfe = RFE(lr, n_features_to_select=1)
rfe.fit(X,Y)
print "Features sorted by their rank:"
print sorted(zip(map(lambda x: round(x, 4), rfe.ranking_), names))
另一种代码:
from sklearn.feature_selection import RFE #导入RFE库
from sklearn.linear_model import LogisticRegression #导入逻辑回归库
model = LogisticRegression() #设置算法为逻辑回归
rfe = RFE(model, 2) #选择2个最佳特征变量,并进行RFE
fit = rfe.fit(X, y) #进行RFE递归
print(fit.n_features_) #打印最优特征变量数
print( fit.support_) #打印选择的最优特征变量
print(fit.ranking_) #特征消除排序
输出结果为:
2
[False True False True]
[3 1 2 1]
可以看到X变量的第2、第4列选为最优变量,即True。最后的[3 1 2 1]也是说明第2、第4列保留到最后。
另一种代码:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# 创建逻辑回归模型
model = LogisticRegression()
# 创建特征递归消除法对象,选择最优的20个特征
rfe = RFE(model, n_features_to_select=20)
# 使用特征递归消除法来训练模型并选择最优的20个特征
X_selected = rfe.fit_transform(iris.data, iris.target) #数据集,目标集
# 打印最优的20个特征的索引和名称
print(rfe.get_support(indices=True))
# 打印特征选择后的数据集
print(X_selected)
(2拓展)双向搜索特征选择
鉴于RFE仅是后向迭代的方法,容易陷入局部最优,而且不支持Lightgbm等模型自动处理缺失值/类别型特征,便基于启发式双向搜索及模拟退火算法思想,产生了一个特征选择的方法。
"""
Author: 公众号-算法进阶
基于启发式双向搜索及模拟退火的特征选择方法。
"""
import pandas as pd
import random
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score, roc_curve, auc
def model_metrics(model, x, y, pos_label=1):
"""
评价函数
"""
yhat = model.predict(x)
yprob = model.predict_proba(x)[:,1]
fpr, tpr, _ = roc_curve(y, yprob, pos_label=pos_label)
result = {'accuracy_score':accuracy_score(y, yhat),
'f1_score_macro': f1_score(y, yhat, average = "macro"),
'precision':precision_score(y, yhat,average="macro"),
'recall':recall_score(y, yhat,average="macro"),
'auc':auc(fpr,tpr),
'ks': max(abs(tpr-fpr))
}
return result
def bidirectional_selection(model, x_train, y_train, x_test, y_test, annealing=True, anneal_rate=0.1, iters=10,best_metrics=0,
metrics='auc',threshold_in=0.0001, threshold_out=0.0001,early_stop=True,
verbose=True):
"""
model 选择的模型
annealing 模拟退火算法
threshold_in 特征入模的>阈值
threshold_out 特征剔除的<阈值
"""
included = []
best_metrics = best_metrics
for i in range(iters):
# forward step
print("iters", i)
changed = False
excluded = list(set(x_train.columns) - set(included))
random.shuffle(excluded)
for new_column in excluded:
model.fit(x_train[included+[new_column]], y_train)
latest_metrics = model_metrics(model, x_test[included+[new_column]], y_test)[metrics]
if latest_metrics - best_metrics > threshold_in:
included.append(new_column)
change = True
if verbose:
print ('Add {} with metrics gain {:.6}'.format(new_column,latest_metrics-best_metrics))
best_metrics = latest_metrics
elif annealing:
if random.randint(0, iters) <= iters * anneal_rate:
included.append(new_column)
if verbose:
print ('Annealing Add {} with metrics gain {:.6}'.format(new_column,latest_metrics-best_metrics))
# backward step
random.shuffle(included)
for new_column in included:
included.remove(new_column)
model.fit(x_train[included], y_train)
latest_metrics = model_metrics(model, x_test[included], y_test)[metrics]
if latest_metrics - best_metrics < threshold_out:
included.append(new_column)
else:
changed = True
best_metrics= latest_metrics
if verbose:
print('Drop{} with metrics gain {:.6}'.format(new_column,latest_metrics-best_metrics))
if not changed and early_stop:
break
return included
#示例
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y)
model = LGBMClassifier()
included = bidirectional_selection(model, x_train, y_train, x_test, y_test, annealing=True, iters=50,best_metrics=0.5,
metrics='auc',threshold_in=0.0001, threshold_out=0,
early_stop=False,verbose=True)
(2)基于树模型的特征筛选(R)
决策树剪枝方法
##决策树法特区特征向量
data = read.table("offlinefinal.csv",quote ="",header=TRUE,sep=",",stringsAsFactors = FALSE,fileEncoding = 'GBK')
str(data)
library(dplyr)
library(rpart)
library(rpart.plot)
library(klaR)
library(ggplot2) # 画图包
library(data.table) # 数据处理包,后面会专门写一下这两个包
View(data)
set.seed(0) #固定随机数,便于检查
train <- sample(nrow(data),0.8*nrow(data)) #随机选择3100*0.2=620个数据为测试集,其余为训练集
traindata <- data[train,] #将抽样行赋给训练集
testdata <- data[-train,] #将去掉抽样行的剩下的数据赋给测试集
#构建决策树并预测
tree <- rpart(class~.,data=traindata,method="class",control=rpart.control(minsplit=10,minbucket=5,xval=10,cp=0))#最小分类的样本数
printcp(tree) #查看模型的详细过程,见图1
rpart.plot(tree) #决策树图
#决策树预测的准确性
tree.Prediction <- predict(tree, newdata=testdata, type='class')
results <- table(Prediction=tree.Prediction, Actual=testdata$class)
results
Correct_Rate <- sum(diag(results)) / sum(results)
Correct_Rate
#剪纸
tree$cptable #查看交叉验证结果,见图5
plotcp(tree) #查看交叉验证结果图,见图6
#剪枝。一种方法是找xerror最小点对应的CP值,由此CP值决定树的大小
tree <- prune(tree, cp=0.01538) #通过cp看到分成3个子节点时交叉误差和4一样
rpart.plot(tree)
library('rattle')
fancyRpartPlot(tree)
printcp(tree)
#减枝后的决策树精确值
tree.Prediction <- predict(tree, newdata=testdata, type='class')
results <- table(Prediction=tree.Prediction, Actual=testdata$class)
results
Correct_Rate <- sum(diag(results)) / sum(results)
Correct_Rate
(2)前项特征选择以及后向特征选择
代码:weka软件里面的cfsSubsetEval中searchMethod选择GreedyStepwise:选择前向后向



2.2.3 嵌入法
基于学习模型给出的特征重要性排序筛选
(1)随机森林模型
特征重要性排序筛选,见随机森林模型
from sklearn.cross_validation import cross_val_score, ShuffleSplit
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
#Load boston housing dataset as an example
boston = load_boston()
X = boston["data"]
Y = boston["target"]
names = boston["feature_names"]
rf = RandomForestRegressor(n_estimators=20, max_depth=4)
scores = []
for i in range(X.shape[1]):
score = cross_val_score(rf, X[:, i:i+1], Y, scoring="r2",
cv=ShuffleSplit(len(X), 3, .3))
scores.append((round(np.mean(score), 3), names[i]))
print sorted(scores, reverse=True)
(2)XGboost模型
特征重要性排序筛选
(3)基于树模型
树模型中GBDT也可用来作为基模型进行特征选择;
训练能够对特征打分的预选模型:RandomForest和Logistic Regression等都能对模型的特征打分,通过打分获得相关性后再训练最终模型;
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
#GBDT作为基模型的特征选择
SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
(4)基于统计检验的特征选择
以卡方检验(chi²非负性特征的统计测试)来检验与数据集预测变量(类别)的最佳特征。
其基本思想:通过观察实际值和理论值的偏差来确定原假设是否成立。首先假设两个变量是独立的(此为原假设),然后观察实际值和理论值之间的偏差程度,若偏差足够小,则认为偏差是很自然的样本误差,接受原假设。若偏差大到一定程度,则否则原假设,接受备择假设。
在这里采用卡方检验来选择与class关系最强的变量。
import pandas as pd
import numpy as np
from sklearn.feature_selection import SelectKBest #导入SelectKBest库
from sklearn.feature_selection import chi2 #导入卡方检验
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = pd.read_csv("D:\\diabetes.csv", names=names) #读取数据集
dataframe.head()
array = dataframe.values
X = array[:,0:8] #选取前8列为特征变量
Y = array[:,8] #选取class为目标变量
print(X[0:5,:]) #打印前5行
(5)带惩罚项的正则化模型
from sklearn.feature_selection import SelectFromModel
#带L1和L2惩罚项的逻辑回归作为基模型的特征选择
#参数threshold为权值系数之差的阈值
SelectFromModel(LR(threshold=0.5, C=0.1)).fit_transform(iris.data, iris.target)
其他更综合的方法:
https://blog.csdn.net/someonelikesyou/article/details/107960801
参考:
https://blog.csdn.net/sunyaowu315/article/details/83782069
重要:https://blog.csdn.net/WEILING123/article/details/114638792?ops_request_misc=&request_id=&biz_id=102&utm_term=python%E5%AE%9E%E7%8E%B0%E4%BF%A1%E6%81%AF%E5%A2%9E%E7%9B%8A%E7%9A%84%E7%89%B9%E5%BE%81%E9%80%89%E6%8B%A9&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-8-114638792.142v93chatsearchT3_2&spm=1018.2226.3001.4187















 5840
5840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









