






GGML
GGML全称是Georgi Gerganov Machine Learning,是由Georgi Gerganov开发的一个张量库(tensor library)
github地址:
https://github.com/ggerganov/ggmlGGML特性
1、用C语言编写:GGML是用C语言开发的,这意味着它可能具有高性能和低资源消耗的特点。
2、支持16位浮点:GGML支持16位浮点数,这可以减少模型的存储空间和计算资源需求,同时保持合理的精度。
3、整数量化支持(例如INT4位、INT5位、INT8位):GGML支持将模型权重量化为较低位数的整数,进一步减小模型大小并提高计算效率,同时也是一种平衡性能和精度的手段。
4、自动微分:GGML具有自动微分功能,这对于机器学习模型的训练和优化非常重要。
5、内置优化算法(例如ADAM, L-BFGS):GGML包含了多种优化算法,这些算法对于训练高效、精确的模型至关重要。
6、针对苹果芯片(Apple Silicon)优化:GGML针对苹果的芯片进行了优化,这意味着在苹果硬件上运行时,它能提供更好的性能。
7、在x86架构上利用AVX/AVX2内置函数:在x86架构上,GGML利用AVX和AVX2指令集来提升性能,这些指令集能够加速某些类型的计算。
8、通过WebAssembly和WASM SIMD支持Web:GGML可以通过WebAssembly(WASM)在Web环境中运行,增加了其在不同平台的可用性。
9、无第三方依赖:GGML不依赖于任何第三方库,这降低了使用的复杂性和潜在的兼容性问题。
10、运行时零内存分配:GGML在运行时不进行任何内存分配,这有助于减少内存消耗和提高性能。
GGMLSharp
GGMLSharp是对GGML进行包装,方便C#调用。
github地址:
https://github.com/IntptrMax/GGMLSharpDemo1: magika
测试文件:
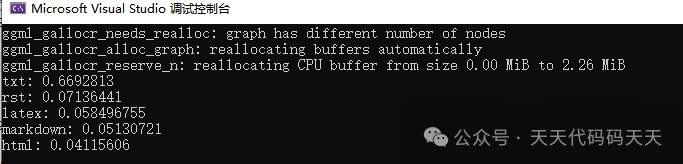
效果:
项目:
代码:
using GGMLSharp;
using System.Runtime.InteropServices;
using static GGMLSharp.Structs;
namespace magika
{
internal unsafe class Program
{
static string[] magika_labels ={
"ai", "apk", "appleplist", "asm", "asp",
"batch", "bmp", "bzip", "c", "cab",
"cat", "chm", "coff", "crx", "cs",
"css", "csv", "deb", "dex", "dmg",
"doc", "docx", "elf", "emf", "eml",
"epub", "flac", "gif", "go", "gzip",
"hlp", "html", "ico", "ini", "internetshortcut",
"iso", "jar", "java", "javabytecode", "javascript",
"jpeg", "json", "latex", "lisp", "lnk",
"m3u", "macho", "makefile", "markdown", "mht",
"mp3", "mp4", "mscompress", "msi", "mum",
"odex", "odp", "ods", "odt", "ogg",
"outlook", "pcap", "pdf", "pebin", "pem",
"perl", "php", "png", "postscript", "powershell",
"ppt", "pptx", "python", "pythonbytecode", "rar",
"rdf", "rpm", "rst", "rtf", "ruby",
"rust", "scala", "sevenzip", "shell", "smali",
"sql", "squashfs", "svg", "swf", "symlinktext",
"tar", "tga", "tiff", "torrent", "ttf",
"txt", "unknown", "vba", "wav", "webm",
"webp", "winregistry", "wmf", "xar", "xls",
"xlsb", "xlsx", "xml", "xpi", "xz",
"yaml", "zip", "zlibstream"
};
private class magika_hparams
{
public int block_size = 4096;
public int beg_size = 512;
public int mid_size = 512;
public int end_size = 512;
public int min_file_size_for_dl = 16;
public int n_label = 113;
public float f_norm_eps = 0.001f;
public int padding_token = 256;
};
private class magika_model
{
~magika_model()
{
Native.ggml_backend_buffer_free(buf_w);
Native.ggml_backend_free(backend);
Native.ggml_free(ctx_w);
}
public magika_hparams hparams = new magika_hparams();
public ggml_tensor* dense_w;
public ggml_tensor* dense_b;
public ggml_tensor* layer_norm_gamma;
public ggml_tensor* layer_norm_beta;
public ggml_tensor* dense_1_w;
public ggml_tensor* dense_1_b;
public ggml_tensor* dense_2_w;
public ggml_tensor* dense_2_b;
public ggml_tensor* layer_norm_1_gamma;
public ggml_tensor* layer_norm_1_beta;
public ggml_tensor* target_label_w;
public ggml_tensor* target_label_b;
public ggml_backend* backend = Native.ggml_backend_cpu_init();
public ggml_backend_buffer* buf_w = null;
public ggml_context* ctx_w = null;
};
private static ggml_tensor* checked_get_tensor(ggml_context* ctx, string name)
{
ggml_tensor* tensor = Native.ggml_get_tensor(ctx, name);
if (null == tensor)
{
throw new ArgumentNullException($"tensor {name} not found");
}
return tensor;
}
private static magika_model magika_model_load(string fname)
{
magika_model model = new magika_model();
ggml_context* ctx = model.ctx_w;
gguf_init_params @params = new gguf_init_params
{
no_alloc = true,
ctx = &ctx,
};
gguf_context* ctx_gguf = Native.gguf_init_from_file(fname, @params);
if (null == ctx_gguf)
{
throw new FileLoadException($"gguf_init_from_file() failed");
}
model.buf_w = Native.ggml_backend_alloc_ctx_tensors(ctx, model.backend);
if (null == model.buf_w)
{
throw new Exception($"%s: ggml_backend_alloc_ctx_tensors() failed");
//Native.gguf_free(ctx_gguf);
}
try
{
model.dense_w = checked_get_tensor(ctx, "dense/kernel:0");
model.dense_b = checked_get_tensor(ctx, "dense/bias:0");
model.layer_norm_gamma = checked_get_tensor(ctx, "layer_normalization/gamma:0");
model.layer_norm_beta = checked_get_tensor(ctx, "layer_normalization/beta:0");
model.dense_1_w = checked_get_tensor(ctx, "dense_1/kernel:0");
model.dense_1_b = checked_get_tensor(ctx, "dense_1/bias:0");
model.dense_2_w = checked_get_tensor(ctx, "dense_2/kernel:0");
model.dense_2_b = checked_get_tensor(ctx, "dense_2/bias:0");
model.layer_norm_1_gamma = checked_get_tensor(ctx, "layer_normalization_1/gamma:0");
model.layer_norm_1_beta = checked_get_tensor(ctx, "layer_normalization_1/beta:0");
model.target_label_w = checked_get_tensor(ctx, "target_label/kernel:0");
model.target_label_b = checked_get_tensor(ctx, "target_label/bias:0");
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
Native.gguf_free(ctx_gguf);
return null;
}
using (FileStream fs = new FileStream(fname, FileMode.Open, FileAccess.Read))
{
int n_tensors = Native.gguf_get_n_tensors(ctx_gguf);
for (int i = 0; i < n_tensors; i++)
{
string? name = Native.gguf_get_tensor_name(ctx_gguf, i);
ggml_tensor* tensor = Native.ggml_get_tensor(ctx, name);
long offs = Native.gguf_get_data_offset(ctx_gguf) + Native.gguf_get_tensor_offset(ctx_gguf, i);
long n_bytes = Native.ggml_nbytes(tensor);
byte[] buf = new byte[n_bytes];
fs.Seek(offs, SeekOrigin.Begin);
int bytesRead = fs.Read(buf, 0, buf.Length);
IntPtr buf_data = Marshal.UnsafeAddrOfPinnedArrayElement(buf, 0);
Native.ggml_backend_tensor_set(tensor, buf_data, 0, bytesRead);
}
}
Native.gguf_free(ctx_gguf);
return model;
}
private static ggml_cgraph* magika_graph(magika_model model)
{
int GGML_DEFAULT_GRAPH_SIZE = 2048;
magika_hparams hparams = model.hparams;
long buf_size = Native.ggml_tensor_overhead() * GGML_DEFAULT_GRAPH_SIZE + Native.ggml_graph_overhead();
ggml_init_params @params = new ggml_init_params
{
mem_buffer = IntPtr.Zero,
mem_size = buf_size,
no_alloc = true,
};
ggml_context* ctx = Native.ggml_init(@params);
ggml_cgraph* gf = Native.ggml_new_graph(ctx);
ggml_tensor* input = Native.ggml_new_tensor_3d(ctx, ggml_type.GGML_TYPE_F32, 257, 1536, 1); // one-hot
Native.ggml_set_name(input, "input");
Native.ggml_set_input(input);
ggml_tensor* cur;
// dense
cur = Native.ggml_mul_mat(ctx, model.dense_w, input);
cur = Native.ggml_add(ctx, cur, model.dense_b); // [128, 1536, n_files]
cur = Native.ggml_gelu(ctx, cur);
// reshape
cur = Native.ggml_reshape_3d(ctx, cur, 512, 384, 1); // [384, 512, n_files]
cur = Native.ggml_cont(ctx, Native.ggml_transpose(ctx, cur));
// layer normalization
cur = Native.ggml_norm(ctx, cur, hparams.f_norm_eps);
cur = Native.ggml_mul(ctx, cur, model.layer_norm_gamma); // [384, 512, n_files]
cur = Native.ggml_add(ctx, cur, model.layer_norm_beta); // [384, 512, n_files]
// dense_1
cur = Native.ggml_cont(ctx, Native.ggml_transpose(ctx, cur));
cur = Native.ggml_mul_mat(ctx, model.dense_1_w, cur);
cur = Native.ggml_add(ctx, cur, model.dense_1_b); // [256, 384, n_files]
cur = Native.ggml_gelu(ctx, cur);
// dense_2
cur = Native.ggml_mul_mat(ctx, model.dense_2_w, cur);
cur = Native.ggml_add(ctx, cur, model.dense_2_b); // [256, 384, n_files]
cur = Native.ggml_gelu(ctx, cur);
// global_max_pooling1d
cur = Native.ggml_cont(ctx, Native.ggml_transpose(ctx, cur)); // [384, 256, n_files]
cur = Native.ggml_pool_1d(ctx, cur, ggml_op_pool.GGML_OP_POOL_MAX, 384, 384, 0); // [1, 256, n_files]
cur = Native.ggml_reshape_2d(ctx, cur, 256, 1); // [256, n_files]
// layer normalization 1
cur = Native.ggml_norm(ctx, cur, hparams.f_norm_eps);
cur = Native.ggml_mul(ctx, cur, model.layer_norm_1_gamma); // [256, n_files]
cur = Native.ggml_add(ctx, cur, model.layer_norm_1_beta); // [256, n_files]
// target_label
cur = Native.ggml_mul_mat(ctx, model.target_label_w, cur);
cur = Native.ggml_add(ctx, cur, model.target_label_b); // [n_label, n_files]
cur = Native.ggml_soft_max(ctx, cur); // [n_label, n_files]
Native.ggml_set_name(cur, "target_label_probs");
Native.ggml_set_output(cur);
Native.ggml_build_forward_expand(gf, cur);
return gf;
}
private static float[] magika_eval(magika_model model, string fname)
{
magika_hparams hparams = model.hparams;
ggml_gallocr* alloc = Native.ggml_gallocr_new(Native.ggml_backend_get_default_buffer_type(model.backend));
ggml_cgraph* gf = magika_graph(model);
if (!Native.ggml_gallocr_alloc_graph(alloc, gf))
{
throw new Exception("ggml_gallocr_alloc_graph() failed");
}
ggml_tensor* input = Native.ggml_graph_get_tensor(gf, "input");
var buf = new List<int>(Enumerable.Repeat(hparams.padding_token, 1536));
using (FileStream fileStream = new FileStream(fname, FileMode.Open, FileAccess.Read))
{
var fsize = fileStream.Length;
long size = Math.Max(Math.Max(hparams.mid_size, hparams.end_size), hparams.beg_size);
byte[] read_buf = new byte[size];
// Read beg
int n_read = fileStream.Read(read_buf, 0, hparams.beg_size);
for (int j = 0; j < n_read; j++)
{
buf[j] = read_buf[j];
}
// Read mid
var midOffs = Math.Max(0, (int)(fsize - hparams.mid_size) / 2);
fileStream.Seek(midOffs, SeekOrigin.Begin);
n_read = fileStream.Read(read_buf, 0, hparams.mid_size);
for (int j = 0; j < n_read; j++)
{
// pad at both ends
int mid_idx = hparams.beg_size + (hparams.mid_size / 2) - n_read / 2 + j;
buf[mid_idx] = read_buf[j];
}
// Read end
var endOffs = Math.Max(0, fsize - hparams.end_size);
fileStream.Seek(endOffs, SeekOrigin.Begin);
n_read = fileStream.Read(read_buf, 0, hparams.end_size);
for (int j = 0; j < n_read; j++)
{
// pad at the beginning
int end_idx = hparams.beg_size + hparams.mid_size + hparams.end_size - n_read + j;
buf[end_idx] = read_buf[j];
}
}
var inpBytes = hparams.beg_size + hparams.mid_size + hparams.end_size;
var oneHot = new float[257 * inpBytes];
for (int j = 0; j < inpBytes; j++)
{
oneHot[257 * j + buf[j]] = 1.0f;
}
Native.ggml_backend_tensor_set(input, Marshal.UnsafeAddrOfPinnedArrayElement(oneHot, 0), 0, 257 * inpBytes * sizeof(float));
if (Native.ggml_backend_graph_compute(model.backend, gf) != ggml_status.GGML_STATUS_SUCCESS)
{
throw new Exception("ggml_backend_graph_compute() failed");
}
ggml_tensor* target_label_probs = Native.ggml_graph_get_tensor(gf, "target_label_probs");
float[] probs = new float[hparams.n_label];
Native.ggml_backend_tensor_get(target_label_probs, Marshal.UnsafeAddrOfPinnedArrayElement(probs, 0), 0, hparams.n_label * sizeof(float));
return probs;
}
static void Main(string[] args)
{
magika_model model = magika_model_load(@".\Assert\magika.gguf");
float[] result_tensor = magika_eval(model, @".\Assert\test");
List<result> results = new List<result>();
for (int i = 0; i < result_tensor.Length; i++)
{
results.Add(new result { label = magika_labels[i], score = result_tensor[i] });
}
results.Sort((a, b) => b.score.CompareTo(a.score));
for (int i = 0; i < 5; i++)
{
Console.WriteLine("{0}: {1}", results[i].label, results[i].score);
}
}
class result
{
public string label;
public float score;
}
}
}Demo2: mnist_cnn
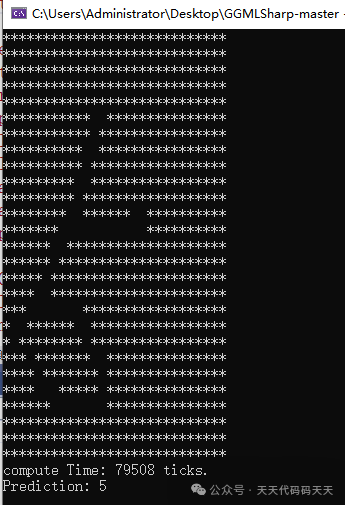
效果:
项目:
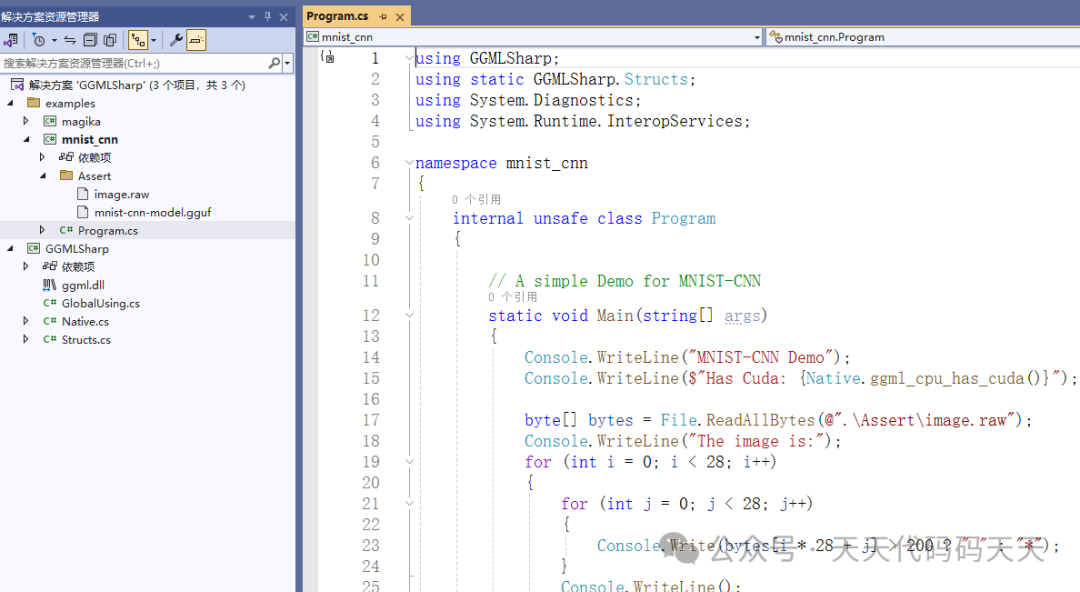
代码:
using GGMLSharp;
using static GGMLSharp.Structs;
using System.Diagnostics;
using System.Runtime.InteropServices;
namespace mnist_cnn
{
internal unsafe class Program
{
// A simple Demo for MNIST-CNN
static void Main(string[] args)
{
Console.WriteLine("MNIST-CNN Demo");
Console.WriteLine($"Has Cuda: {Native.ggml_cpu_has_cuda()}");
byte[] bytes = File.ReadAllBytes(@".\Assert\image.raw");
Console.WriteLine("The image is:");
for (int i = 0; i < 28; i++)
{
for (int j = 0; j < 28; j++)
{
Console.Write(bytes[i * 28 + j] > 200 ? " " : "*");
}
Console.WriteLine();
}
float[] digit = new float[28 * 28];
for (int i = 0; i < bytes.Length; i++)
{
digit[i] = bytes[i] / 255.0f;
}
mnist_model model = mnist_model_load(@".\Assert\mnist-cnn-model.gguf");
Stopwatch stopwatch = Stopwatch.StartNew();
int prediction = mnist_eval(model, 1, digit, string.Empty);
Console.WriteLine("Prediction: {0}", prediction);
Console.ReadKey();
}
private struct mnist_model
{
public ggml_tensor* conv2d_1_kernel;
public ggml_tensor* conv2d_1_bias;
public ggml_tensor* conv2d_2_kernel;
public ggml_tensor* conv2d_2_bias;
public ggml_tensor* dense_weight;
public ggml_tensor* dense_bias;
public ggml_context* ctx;
};
private static mnist_model mnist_model_load(string fname)
{
mnist_model model = new mnist_model();
gguf_init_params @params = new gguf_init_params
{
ctx = &model.ctx,
no_alloc = false,
};
gguf_context* ctx = Native.gguf_init_from_file(fname, @params);
if (ctx == null)
{
throw new FileLoadException("gguf_init_from_file() failed");
}
model.conv2d_1_kernel = Native.ggml_get_tensor(model.ctx, "kernel1");
model.conv2d_1_bias = Native.ggml_get_tensor(model.ctx, "bias1");
model.conv2d_2_kernel = Native.ggml_get_tensor(model.ctx, "kernel2");
model.conv2d_2_bias = Native.ggml_get_tensor(model.ctx, "bias2");
model.dense_weight = Native.ggml_get_tensor(model.ctx, "dense_w");
model.dense_bias = Native.ggml_get_tensor(model.ctx, "dense_b");
return model;
}
private static int mnist_eval(mnist_model model, int n_threads, float[] digit, string fname_cgraph)
{
long buf_size = 1024 * 1024; // Get 1M mem size
ggml_init_params @params = new ggml_init_params
{
mem_buffer = IntPtr.Zero,
mem_size = buf_size,
no_alloc = false,
};
ggml_context* ctx0 = Native.ggml_init(@params);
ggml_cgraph* gf = Native.ggml_new_graph(ctx0);
ggml_tensor* input = Native.ggml_new_tensor_4d(ctx0, ggml_type.GGML_TYPE_F32, 28, 28, 1, 1);
Marshal.Copy(digit, 0, input->data, digit.Length);
Native.ggml_set_name(input, "input");
ggml_tensor* cur = Native.ggml_conv_2d(ctx0, model.conv2d_1_kernel, input, 1, 1, 0, 0, 1, 1);
cur = Native.ggml_add(ctx0, cur, model.conv2d_1_bias);
cur = Native.ggml_relu(ctx0, cur);
// Output shape after Conv2D: (26 26 32 1)
cur = Native.ggml_pool_2d(ctx0, cur, ggml_op_pool.GGML_OP_POOL_MAX, 2, 2, 2, 2, 0, 0);
// Output shape after MaxPooling2D: (13 13 32 1)
cur = Native.ggml_conv_2d(ctx0, model.conv2d_2_kernel, cur, 1, 1, 0, 0, 1, 1);
cur = Native.ggml_add(ctx0, cur, model.conv2d_2_bias);
cur = Native.ggml_relu(ctx0, cur);
// Output shape after Conv2D: (11 11 64 1)
cur = Native.ggml_pool_2d(ctx0, cur, ggml_op_pool.GGML_OP_POOL_MAX, 2, 2, 2, 2, 0, 0);
// Output shape after MaxPooling2D: (5 5 64 1)
cur = Native.ggml_permute(ctx0, cur, 1, 2, 0, 3);
cur = Native.ggml_cont(ctx0, cur);
// Output shape after permute: (64 5 5 1)
cur = Native.ggml_reshape_2d(ctx0, cur, 1600, 1);
// Final Dense layer
cur = Native.ggml_mul_mat(ctx0, model.dense_weight, cur);
cur = Native.ggml_add(ctx0, cur, model.dense_bias);
ggml_tensor* probs = Native.ggml_soft_max(ctx0, cur);
Native.ggml_set_name(probs, "probs");
Native.ggml_build_forward_expand(gf, probs);
Stopwatch stopwatch = Stopwatch.StartNew();
Native.ggml_graph_compute_with_ctx(ctx0, gf, n_threads);
stopwatch.Stop();
Console.WriteLine("compute Time: {0} ticks.", stopwatch.ElapsedTicks);
//ggml_graph_print(&gf);
//Native.ggml_graph_dump_dot(gf, null, "mnist-cnn.dot");
if (!string.IsNullOrEmpty(fname_cgraph))
{
// export the compute graph for later use
// see the "mnist-cpu" example
Native.ggml_graph_export(gf, fname_cgraph);
Console.WriteLine("exported compute graph to {0}\n", fname_cgraph);
}
float* probs_data = Native.ggml_get_data_f32(probs);
List<float> probs_list = new List<float>();
for (int i = 0; i < 10; i++)
{
probs_list.Add(probs_data[i]);
}
int prediction = probs_list.IndexOf(probs_list.Max());
Native.ggml_free(ctx0);
return prediction;
}
}
}















 672
672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









