






ChatCompletion最强大功能之一就是能够从模型中调用函数。这让你可以基于现有代码创建聊天机器人,实现自动化业务流程、生成代码片段等功能。
在 Semantic Kernel 中,函数调用的过程被大幅简化:它会自动将你的函数和参数描述给模型,并处理模型与代码之间的沟通。了解这一机制对优化代码、充分发挥函数调用的优势至关重要。
自动函数调用的工作原理
函数调用的工作原理可以分为以下几个步骤:
| 步骤 | 描述 |
|---|---|
| 1. 序列化函数 | 将所有可用的函数(及其输入参数)使用 JSON Schema 进行序列化。 |
| 2. 发送消息和函数到模型 | 将序列化后的函数(以及当前聊天历史)作为输入发送到模型。 |
| 3. 模型处理输入 | 模型处理输入,并生成响应。响应可以是普通的聊天消息,也可以是一个或多个函数调用。 |
| 4. 处理模型返回的响应 | 如果返回的是普通聊天消息,直接返回给调用方。如果返回的是函数调用,则解析出函数名称及其参数。 |
| 5. 执行函数 | 使用提取出的函数名称和参数,在 Kernel 中调用相应的函数。 |
| 6. 返回函数结果 | 函数调用的结果会作为聊天历史的一部分发送回模型。然后,步骤 2-6 会重复执行,直到模型返回普通的聊天消息或达到最大迭代次数。 |
如下Function Calling的流程
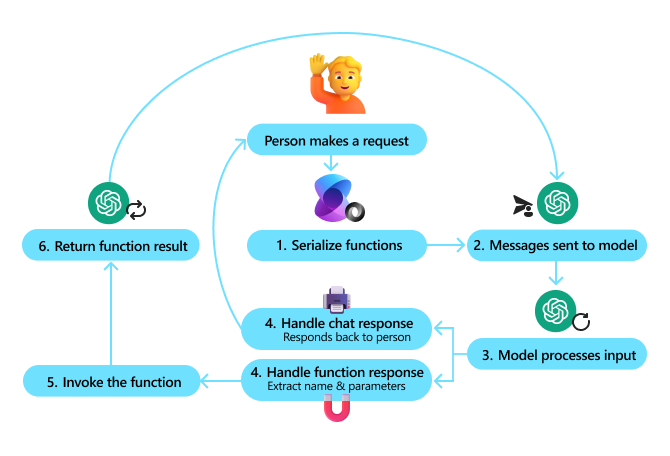
模拟函数调用
除了用户(User)、助手(Assistant)和系统(System)这几种角色外,你还可以使用工具(Tool)角色来模拟函数调用。这对于让 AI 学习如何使用插件,或者在对话中提供额外的背景信息非常有帮助。比如,如果你想让 AI 了解用户的信息(比如过敏情况),但又不希望用户每次都手动输入,也不想让 AI 反复询问,你可以用 工具(Tool) 角色直接把这些信息提供给 AI。
下面是一个示例,我们通过模拟调用“用户插件”,把用户的过敏信息直接提供给助手,让 AI 知道用户的饮食限制。
模拟函数调用在提供当前用户的详细信息时特别有用。如今的大型语言模型(LLM)对用户信息非常敏感。即使你在系统消息中提供了用户信息,LLM 仍然可能选择忽略它。但如果你通过用户消息(User Message)或工具消息(Tool Message)提供这些信息,LLM 更有可能正确使用它。
// 添加一个来自助手的模拟函数调用
chatHistory.Add(
new() {
Role = AuthorRole.Assistant,
Items = [
new FunctionCallContent(
functionName: "get_user_allergies", // 函数名称:获取用户过敏信息
pluginName: "User", // 插件名称:用户(User)
id: "0001", // 调用 ID
arguments: new () { {"username", "laimonisdumins"} } // 参数:用户名 laimonisdumins
),
new FunctionCallContent(
functionName: "get_user_allergies", // 函数名称:获取用户过敏信息
pluginName: "User", // 插件名称:用户(User)
id: "0002", // 调用 ID
arguments: new () { {"username", "emavargova"} } // 参数:用户名 emavargova
)
]
}
);
// 添加来自工具角色的模拟函数返回结果
chatHistory.Add(
new() {
Role = AuthorRole.Tool,
Items = [
new FunctionResultContent(
functionName: "get_user_allergies", // 函数名称:获取用户过敏信息
pluginName: "User", // 插件名称:用户(User)
id: "0001", // 调用 ID
result: "{ \"allergies\": [\"peanuts\", \"gluten\"] }"// 返回结果:用户对花生和麸质过敏
)
]
}
);
chatHistory.Add(
new() {
Role = AuthorRole.Tool,
Items = [
new FunctionResultContent(
functionName: "get_user_allergies", // 函数名称:获取用户过敏信息
pluginName: "User", // 插件名称:用户(User)
id: "0002", // 调用 ID
result: "{ \"allergies\": [\"dairy\", \"soy\"] }"// 返回结果:用户对乳制品和大豆过敏
)
]
}
);在模拟工具(Tool)返回结果时,必须始终提供与之对应的函数调用 ID。这是让 AI 理解返回结果上下文的重要信息。某些大型语言模型(LLM),比如 OpenAI,如果缺少 ID 或 ID 与函数调用不匹配,可能会抛出错误。
函数调用的示例
C# 版的函数调用示例,模拟了一个书籍订购插件(OrderBookPlugin),它提供了添加书籍到购物车、从购物车中移除书籍、获取购物车内容等功能。
配置Azure OpenAI
builder.Services.AddSingleton(sp =>
{
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAIChatCompletion(
deploymentName: "gpt-4.1", // 你在 Azure 上配置的模型部署名称
endpoint: "",
apiKey: ""
).Build();
var logger=kernel.LoggerFactory;
kernel.ImportPluginFromType<TimePlugin>("Time");
kernel.ImportPluginFromType<OrderBookPlugin>("OrderBook");
return kernel;
});新增 OrderBookPlugin
public classOrderBookPlugin
{
privatereadonly List<Book> _bookMenu;
privatereadonly Dictionary<Guid, Cart> _userCarts;
privatereadonly List<Cart> _carts;
privatereadonly List<BookTag> _bookTags;
// 模拟的数据
public OrderBookPlugin()
{
// 假设的书籍菜单
_bookMenu = new List<Book>
{
new Book { Id = 1, Name = "自控力", Price = 8.99 }, // The Power of Self-Control -> 自控力
new Book { Id = 2, Name = "人类简史", Price = 9.99 }, // Sapiens: A Brief History of Humankind -> 人类简史
new Book { Id = 3, Name = "活着", Price = 10.99 }, // To Live -> 活着
new Book { Id = 4, Name = "百年孤独", Price = 12.99 }, // One Hundred Years of Solitude -> 百年孤独
new Book { Id = 5, Name = "围城", Price = 11.99 }, // Fortress Besieged -> 围城
new Book { Id = 6, Name = "平凡的世界", Price = 10.49 } // Ordinary World -> 平凡的世界
};
// 模拟的书籍标签
_bookTags = new List<BookTag>
{
new BookTag { Id = 1, Name = "励志" }, // Motivational -> 励志
new BookTag { Id = 2, Name = "历史" }, // History -> 历史
new BookTag { Id = 3, Name = "小说" }, // Novel -> 小说
new BookTag { Id = 4, Name = "哲学" }, // Philosophy -> 哲学
new BookTag { Id = 5, Name = "社会学" }, // Sociology -> 社会学
new BookTag { Id = 6, Name = "文学" } // Literature -> 文学
};
// 模拟用户购物车
_userCarts = new Dictionary<Guid, Cart>();
_carts = new List<Cart>();
}
[KernelFunction("get_book_menu")]
public Task<List<Book>> GetBookMenuAsync()
{
return Task.FromResult(_bookMenu);
}
[KernelFunction("add_book_to_cart")]
[Description("添加书籍到用户购物车;返回新添加的书籍并更新购物车")]
public Task<CartDelta> AddBookToCart(
[Description("书名,例如《自控力》")] string name,
[Description("数量")] int quantity = 1)
{
// 假设用户只有一个购物车,并使用随机 ID 来生成 cartId
Guid cartId = Guid.NewGuid();
var book = _bookMenu.FirstOrDefault(b => b.Name == name);
if (book == null) return Task.FromResult(new CartDelta { Success = false });
var cart = new Cart
{
Id = cartId,
Items = new List<CartItem>
{
new CartItem { Book = book, Quantity = quantity }
},
TotalPrice = book.Price * quantity
};
_userCarts[cartId] = cart;
_carts.Add(cart);
return Task.FromResult(new CartDelta { Success = true, Cart = cart });
}
[KernelFunction("remove_book_from_cart")]
public Task<RemoveBookResponse> RemoveBookFromCart(int bookId)
{
// 假设我们从用户的购物车移除指定的书籍
var cart = _carts.FirstOrDefault(c => c.Items.Any(i => i.Book.Id == bookId));
if (cart == null) return Task.FromResult(new RemoveBookResponse { Success = false });
var item = cart.Items.FirstOrDefault(i => i.Book.Id == bookId);
if (item != null)
{
cart.Items.Remove(item);
cart.TotalPrice -= item.Book.Price * item.Quantity;
}
return Task.FromResult(new RemoveBookResponse { Success = true });
}
[KernelFunction("get_book_from_cart")]
[Description("返回用户购物车中书籍的详情; 使用此方法,而不是依赖之前的消息,因为购物车可能已经发生了变化.")]
public Task<Book> GetBookFromCart(int bookId)
{
var cartItem = _carts.SelectMany(c => c.Items).FirstOrDefault(i => i.Book.Id == bookId);
return Task.FromResult(cartItem?.Book);
}
[KernelFunction("get_cart")]
[Description("返回用户当前的购物车,包含总价和购物车中的所有商品.")]
public Task<List<Cart>> GetCart()
{
// 这里假设只返回第一个用户的购物车
return Task.FromResult(_carts);
}
[KernelFunction("checkout")]
[Description("这个函数主要负责将用户购物车中的商品进行结算.")]
public Task<CheckoutResponse> Checkout()
{
// 模拟结账过程
double totalAmount = 0;
_carts.ForEach(cart => totalAmount += cart.TotalPrice);
if (_carts == null) return Task.FromResult(new CheckoutResponse { Success = false });
_carts.Clear(); // 清空购物车
return Task.FromResult(new CheckoutResponse { Success = true, TotalAmount = totalAmount });
}
}Function Calling 演示
Semantic Kernel 中的函数调用
Semantic Kernel(SK)提供了一个强大的函数调用机制,它封装了与模型交互的复杂细节,让你可以更专注于业务逻辑的实现。SK 自动处理函数注册、参数绑定、模型调用等步骤,大大简化了开发流程。
这里假设你在使用 OpenAI Function Calling(或 Azure OpenAI)时,手动处理每一步,并对比 SK 替你做了哪些工作。
原始流程步骤 vs Semantic Kernel 封装对比
步骤 | Function Calling 原始做法(自己做) | SK 帮你封装 |
|---|---|---|
1. 函数注册与描述构建 | • 手动用 JSON 构建每个函数的 schema(name、description、parameters) | • 自动反射 [KernelFunction] 和参数描述 |
2. 组织聊天历史 | • 自己构造 messages 列表:用户消息、助手回复、函数调用请求 | • 用 ChatHistory 自动管理 |
3. 将函数定义与聊天记录发给模型 | • 把函数定义 + 聊天记录打包到 HTTP 请求体 | •GetChatMessageContentAsync(...) 一句完成 |
4. 解析模型返回,判断是否为函数调用 | • 检查 finish_reason == "function_call" | • 自动检查响应结构 |
5. 参数绑定 | • 把 JSON 字符串手动 JsonConvert.Deserialize() | • 自动转换为 C# 参数类型 |
6. 执行对应的函数逻辑 | • 自己手动查找函数(基于名称) | • 自动找到已注册插件函数并调用 |
7. 错误处理与恢复机制 | • 捕获错误 | • 自动捕获异常,返回默认失败响应 |
8. 函数结果回写到聊天历史 | • 自己构造 tool 角色的响应 JSON | • 自动封装为 FunctionResultContent 并追加 |
9. 模型继续生成最终回复 | • 再次发送新的消息上下文给模型 | • GetChatMessageContentAsync 自动完成 |
10. 多轮调用管理 | • 手动判断是否继续调用函数或结束对话 | • 由 SK 自动判断并进行多轮对话或结束流程 |
总结
Semantic Kernel 帮你自动处理了函数注册、上下文维护、参数绑定、模型调用、函数执行和结果回写,让你几乎只需要写业务逻辑函数,剩下的复杂流程都由它接管了。这大大简化了函数调用的开发流程,让你可以更专注于业务逻辑的实现,而不是底层的细节处理。
源代码地址
https://github.com/bingbing-gui/AspNetCore-Skill/tree/master/src/09-AI-Agent/SemanticKernel/SK.FunctionCalling
Open AI 原生Function Calling
https://platform.openai.com/docs/guides/function-calling?api-mode=responses#additional-configurations

















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









